Status
-- Motivation
In our experience with airflow, we found that the resource utilization is very low. We need a lot of worker machines to support all the concurrent running tasks. Yet we found that many machines are running the maximum number of tasks however the machines are almost idle. Those machines are running sensor tasks. We also found that there are other operators with similar behavior, such as SubDag Operator and the airflow spark submit client.
Why can these tasks cause such problems?
Sensors are a special kind of operator that will keep running until a certain criterion is met. The criterion can be a file landing in hdfs or s3, a partition appearing in hive, some external task succeeded or even it is a specific time of the day. Executing a sensor task is very straightforward, sensors call the “poke” function for checking the criterion in a time interval, usually every 3 mins, and succeed if their “poke” functions return true and fail when sensors timeout. The execution of a “poke” is very fast. Most of the time, sensors are waiting for the next “poke” time coming.
SubDags is used to define the repeating patterns in a DAG and it makes complicated DAGs structure cleaner and more readable. The implementation of the SubDagOperator follows a similar pattern as sensors. It creates the dagrun for a subdag in pre_execute function and keeps “poking” the dagrun status in the execute function.
There are more other operators such as SparkSubmitOperator. The spark client in airflow submits the job and polls until completion. All these tasks, after some initialization work, fall into a lightweight and may be long running status which is inefficient.
From the previous analysis we can summarize issues for these tasks falling into the same “long running, lightweight” pattern:
- The resource utilization is very low. Worker process for these tasks idle for 99% of the time.
- These tasks are often long running and they are taking a big part of concurrent running tasks in a large scale cluster. In airbnb, more than 70% of running tasks are sensors.
- Every task in airflow emits heartbeats. Before migrating heartbeat to redis, the heartbeat took a great part of requests to airflow metaDB. A large number of long running tasks increase the metaDB load and make the situation worse when sth goes wrong
- There are a lot of duplicate sensor tasks ; more than 40% sensor jobs are duplicate. The reason is that many downstream DAGs usually wait for the same partitions from a few important upstream DAGs.
In Airbnb existing sensor tasks account for 70% of concurrent airflow tasks and the number keeps growing. Usually they are long running so we have to use a large number of worker slots to run these tasks at peak hours. However sensor tasks are light weight tasks that poke every 3 minutes and idle most of the time. Since we are having more and more sensors, the increased number of tasks also increased DB load by generating heartbeats.
-- What is Smart Sensor
The smart sensor is a service which greatly reduces airflow’s infrastructure cost by consolidating some of the airflow long running light weight tasks.
Idea
Instead of using one process for each task, our main idea to improve the efficiency of these long running tasks is to use centralized processes to execute those tasks in batches.
To do that, we need to run a task in two steps, the first step is to serialize the task information into the database; and the second step is to use a few centralized processes to execute the serialized tasks in batches.
In this way, we only need a handful of running processes. In airbnb, we just need 50-80 running processes, compared to more than 20 thousands before.
Good news is that the heartbeats decrease as the running process decreases and the database load is reduced correspondingly.
Another problem with the existing approach is that there are a lot of duplicate tasks. In smart sensor, we also implemented a way to detect the duplicate tasks and then avoid running the duplicate jobs in the same poking cycle.
Our way to handle duplicate sensors is : first, we create a hash for each job by the job’s meta data. We use the hash as the signature of the job such that If two jobs have the same hash, they are duplicate jobs. We then save the job’s hash in the database along with other serialized info from the job. The centralized process will only process task with the same hash once in each poking cycle.
Logic Flow
A task starts with the same logic of rendering the template and runs the pre_execute function for both smart sensor/ non smart sensor modes. After running the pre_execute function, there is a new branch for smart sensor logic. It checks if itself is smart sensor compatible. A task supported by smart sensors tries to register itself in the smart sensor service. If the registration succeeded, it exited with a “sensing” state and expected the centralized smart sensor tasks to handle the rest of the work. If the registration fails or this task is not supported by the smart sensor, it falls back to run the execute function.

With smart sensor enabled. Large numbers of sensor tasks that are smart sensor compatible will be consolidated into a few smart sensor operators.

Details of Issues that need to be addressed and the analysis.
Implementation: https://github.com/apache/airflow/pull/5499
Change summary:
- Add a new mode called “smart sensor mode”. In smart sensor mode, instead of holding a long running process for each sensor and poking periodically, a sensor will only store poke context at sensor_instance table and then exits with a ‘sensing’ state.
- When the smart sensor mode is enabled, a special set of builtin smart sensor DAGs (named smart_sensor_group_shard_xxx) is created by the system; These DAGs contain SmartSensorOperator task and manage the smart sensor jobs for the airflow cluster. The SmartSensorOperator task can fetch hundreds of ‘sensing’ instances from sensor_instance table and poke on behalf of them in batches. Users don’t need to change their existing DAGs.
- The smart sensor mode currently supports NamedHivePartitionSensor and MetastorePartitionSensor however it can easily be extended to support more sensor classes.
- Smart sensor mode on/off, the list of smart sensor enabled classes, and the number of SmartSensorOperator tasks can be configured in airflow config.
- Sensor logs in smart sensors are populated to each task instance log UI.
Schema change
CREATE TABLE `sensor_instance` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`task_id` varchar(250) NOT NULL,
`dag_id` varchar(250) NOT NULL,
`execution_date` timestamp(6) NOT NULL,
`state` varchar(20) DEFAULT NULL,
`try_number` int(11) DEFAULT NULL,
`start_date` timestamp(6) NULL DEFAULT NULL,
`operator` varchar(1000) DEFAULT NULL,
`op_classpath` varchar(1000) DEFAULT NULL,
`hashcode` bigint(20) DEFAULT NULL,
`shardcode` int(11) DEFAULT NULL,
`poke_context` text DEFAULT NULL,
`execution_context` text DEFAULT NULL,
`created_at` TIMESTAMP DEFAULT CURRENT_TIMESTAMP ,
`updated_at` TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id));
CREATE UNIQUE INDEX ti_primary_key
ON sensor_instance(dag_id, task_id, execution_date);
ALTER TABLE `sensor_instance`
ADD INDEX si_hashcode(hashcode),
ADD INDEX si_shardcode(shardcode),
ADD INDEX si_state_shard(state, shardcode)
;
ALTER TABLE `sensor_instance`
ADD INDEX si_updated_at(updated_at)
;
Add sensor_instance table
- Smart sensor tasks will query the sensor_instance table instead of parse DAG file to get task information thus avoid taking a long time on parsing multiple DAGs at runtime.
- What is in the sensor_instance table
- The sensor_instance table duplicates most information from task_instance. It will need all the ti keys (dag_id, task_id, execution_date, try_number) if we propose to create a log entry for each sensor. Compared with doing a join table query each time I would rather duplicate these columns.
- The sensor_instance table has new columns:
`hashcode` bigint(20) DEFAULT NULL,
`shardcode` int(11) DEFAULT NULL,
`poke_context` text DEFAULT NULL,
`execution_context` text DEFAULT NULL,
- Why did we create a new table?
- Give some isolation for sensor (Based on task_instance state changing strategy it is hard to have full isolation unless we have a well defined API )
- Smart sensor tasks will query the sensor_instance table so that it reduces the risk of locking the task_instance table which is accessed by most processes in airflow.
- Consistency and sync issue:
- Keep most of the behavior of the task_instance table. A new state "sensing" should be added. A ti will get into either “sensing” or “running” state after being picked up by a worker based on if it can use a smart sensor.
- Mirror state in sensor table from task_instance table when a record created (initial state in “sensing”). Smart sensor service should only poke for 'sensing' state in sensor table
- Smart sensor service only visits the task_instance table when a sensor is considered in a final state “success”/”failed”. Smart sensor checks the current state of ti in the task_instance table and only writes back when the ti state is 'sensing'. If the ti state was in another state, it should mirror the state in the sensor table without changing it.
Persist poke information to DB
The purpose is to avoid parsing all big DAG files from the smart sensor operator. Most sensors have simple and limited arguments, if we can retrieve these from DB without parsing DAG at runtime, one process should be easily handle hundreds of poking jobs.
Solution:
- Whitelist the fields that need to be persist. Persisting all attributes for task instance objects is very difficult and contains redundant fields. For those sensors that want to be supported by smart sensor. We use poke_context_fields in the sensor class to identify fields that this sensor will need for poking
- For handling execution settings such as timeout, execution_timeout and email on failure of tasks, we add execution_context_fields to base sensor operator.
Shards and Deduplicate
To handle a large number of sensor jobs, multiple smart sensor tasks need to be spinned up. The sharding logic in smart sensor is in the following diagram.
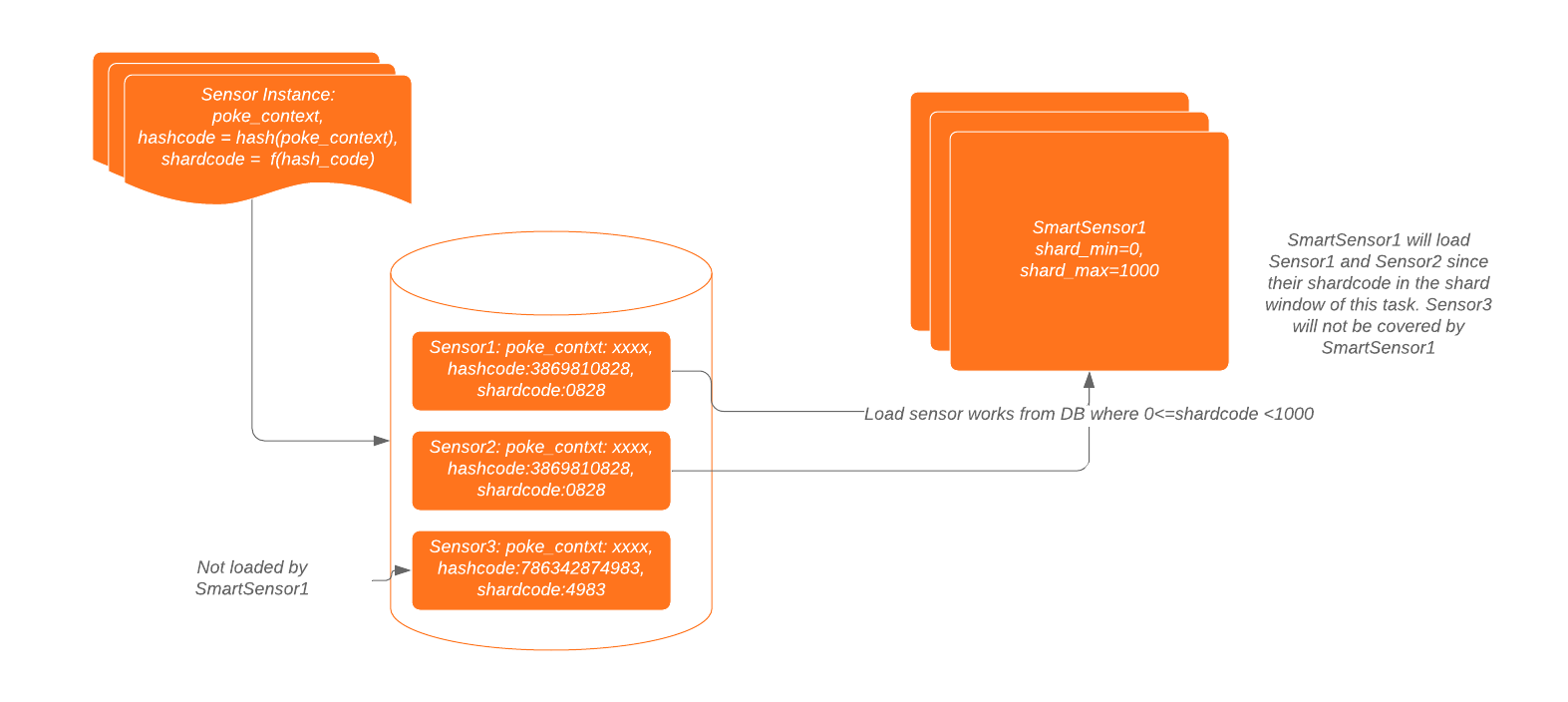
We add columns in sensor_instance:
- hashcode = hash(poke_context)
- Shardcode = hashcode % shard_code_upper_limit
Each smart sensor task set shard_min and shard_max when it was created. The task will handle all sensors with their shardcode satisfying shard_min <= shardcode < shard_max.
- Sensors with same poke_context are considered duplicated sensors in smart sensor
- In our native DAG implementation, we can guarantee:
- The smart_sensor_group DAGs will cover all sensor tasks in the cluster -- each sensor task, if it is smart_sensor_compatible, will be picked up by one DAG in smart_sensor_group
- Duplicated sensors will be loaded by the same smart sensor task.
Sensor logs
One smart sensor task will execute hundreds of sensors’ work and output logs to one single log file with default airflow log setup. To keep the user’s log access, a smart sensor creates separate log files for each sensor it handles. It configures the log handler to output log file to the same path where a regular sensor log should be.
Support different sensor operators
The sensor classpath was persisted into DB at sensor registration. Which will be used to import the sensor class in smart sensor. The smart sensor then uses this class to create a cached sensor task object whose “poke()” function will be reused.
Smart sensor tasks management
Airflow configuration use_smart_sensor = True will include smart_sensor_group DAGs.
Implementation checklist
- DB schema and new ORM class
- Add sensor_instance table
- Add corresponding class SensorInstance to register sensor tasks and persist poke arguments in DB
- Add ‘sensing’ state to airflow task instance states. Update UI for the new state as well.
- BaseOperator: Add is_smart_sensor_compatible() to BaseOperator with default value false.
- BaseSensorOperator
- Override is_smart_sensor_compatible()
- Add register_in_sensor_service()
- Add function to get the poke context and execution context for sensor jobs
- In taskinstance.py
- Add checking after pre_execute for smart sensor compatibility.
- Register qualified sensor jobs(which will set the task instance state to ‘sensing’ state) and exit running tasks without poking it.
- Change email_alert to make it callable from both traditional task instance and smart sensor operator
- New Operator: SmartSensorOpeartor keeps querying DB from sensor jobs in ‘sensing’ state and poke them one by one.
- Smart sensor task control
- Use native DAGs with a smart sensor operator to spin up and rotate the smart sensor jobs for the airflow cluster.
- Turn smart sensor mode on/off by configuring use_smart_sensor configuration
- Provide flexible smart sensor support by configurable “shards” and “sensors_enabled”
- Simulate task instance logs that executed by smart sensor
How to enable/disable smart sensor
Enabling/Disabling the smart sensor is a system level config which is transparent to the individual users. An example of smart sensor enabled cluster config is as follows:
[smart_sensor]
use_smart_sensor = true
shard_code_upper_limit = 10000
shards = 5
sensor_enabled = NamedHivePartitionSensor, MetastorePartitionSensor
The "use_smart_sensor" config indicates if the smart sensor is enabled. The "shards" config indicates the number of concurrently running smart sensor jobs for the airflow cluster. The "sensor_enabled" config is a list of sensor class names that will use the smart sensor. The users use the same class names (e.g. HivePartitionSensor) in their DAGs and they don’t have the control to use smart sensors or not, unless they exclude their tasks explicits.
- Enabling/disabling the smart sensor service is a system level configuration change. It is transparent to the individual users.
- Existing DAGs don't need to be changed for enabling/disabling the smart sensor.
- Rotating centralized smart sensor tasks will not cause any user’s sensor task failure.
How to support new operators
- Define "poke_context_fields" as class attribute in the operator. "poke_context_fields" include all key names used for initializing a sensor object.
- In airflow.cfg, add new operator classname to [smart_sensor] sensors_enabled. All supported sensor classname should be comma separated.
-- Impact after deployment
Cost Saving: we are able to terminate about 80% of the ec2 instances in airflow clusters which were designated for sensor tasks, the worker slots used for sensor tasks went down 85%.

System Improvement: The number of parallel sensor tasks is reduced by 85%, and the number of concurrent airflow tasks is reduced more than 60%. The reduction of tasks greatly helps stabilize airflow cluster by reducing the airflow metaDB load, mostly from heartbeat operations (before deployment sensor tasks took more than 70% ratio of all running tasks).
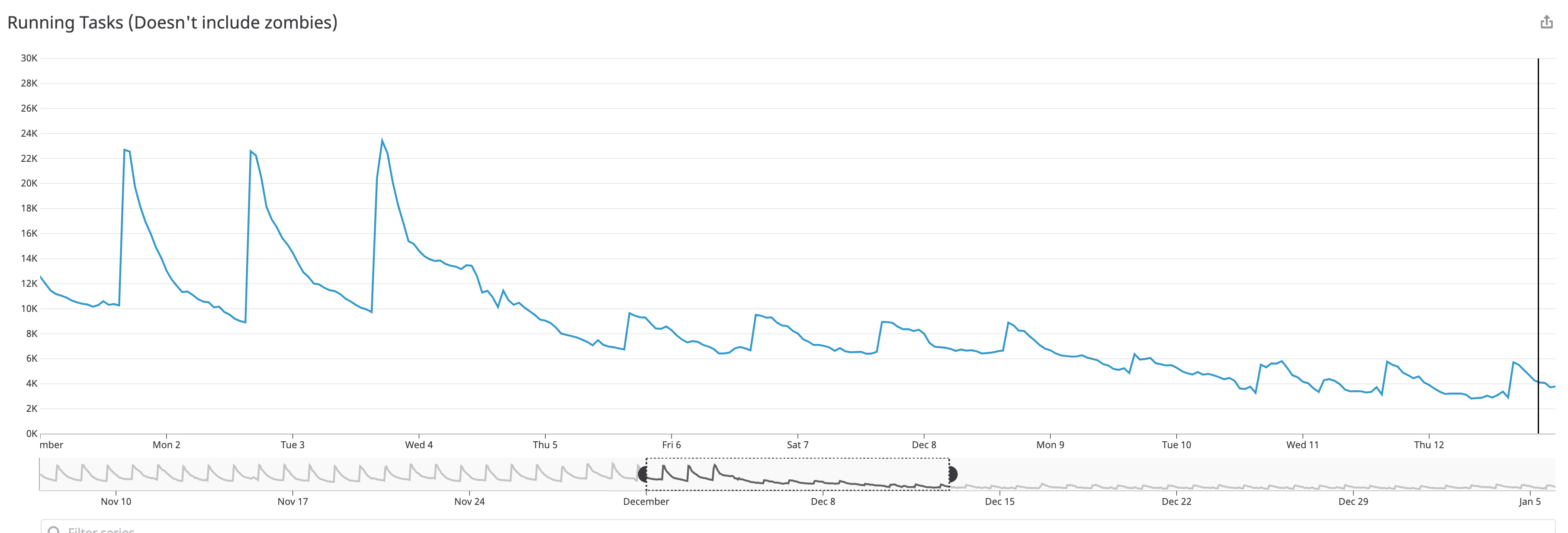
Reducing the request to Hive metastore database because the smart sensor consolidates duplicate sensor tasks. As shown below, the gray dot-line shows the original number of requests to hive metastore database and the blue solid line shows the number of requests after we deployed the smart sensor.

Considerations
- To make the smart sensor extensible to all sensor operators, we may need to improve poke context serialize/deserialize function with a more general solution.
- The callbacks were not supported in this first version.
- Smart sensor do syn mode poke for all sensors. One of the future work is to support customized poke_interval.
6 Comments
Ash Berlin-Taylor
This is really interesting.
Would this also alllow, for instance, an operator to go into "Sensor mode" – I'm thinking of the SparkSubmitOperator, where in once it has submitted the job to yarn, it's job is mostly done, and the rest of it's job is just to poll for completion. Having this work, but not need a separate Submit and Sensor tasks is appealing.
Yingbo Wang
I think this is able to be extended to cover more polling operators. Use the SparkSubmitOperator as an example, we can move the submit logic in the pre_execute hook and give the operator a "poke" function. After that the Operator should fit in this logic perfectly (which is how the SubDagOperator implemented right now).
Sumit Maheshwari
Yeah, this feature would be very helpful. In fact a couple of years back we were also thinking of doing something like this but for operators. As Ash said, I believe a large number of operators operate in the same fashion, i.e. submit jobs to a third party and then wait for its completion only. So would like it to be extendable to operators as well, but not necessarily in the first phase itself.
Kaxil Naik
If DAG Serialization is turned on, you would be able to get the task information from the serialized_dag table.
Kaxil Naik
Most of the information you have listed in "Persist poke information to DB" section can be retrieved from serialized_dag table.
Yingbo Wang
There are fields not available in serialized_dag table but will be used at "poke" time. (e.g. The partition with ds) For argument that are defined with airflow macro, they need to be rendered in "render_template" function before a task instance could execute and may depends on the "execution_date" of its task instance. Serialized dag definitely will be beneficial for all operators including sensor but the task definition in it is the metamodel for a running instance.