Status
Summary
The multi-team feature described here allows to have a single deployment of Airflow for several/multiple teams that will be isolated from each other in terms of:
- access to team-specific configuration (variables, connections)
- execute the code submitted by team-specific DAG authors in isolated environments (both parsing and execution)
- allow different teams to use different set of dependencies/execution environment libraries
- allow different teams to use different executors (including multiple executors per-team following AIP-61)
- allows to link DAGs between different teams via a “dataset” feature. Datasets can be produced/consumed by different teams
- allow the UI users to to see a subset of single team or multiple teams DAGs/ Connections / Variables/ DAGRuns etc.
- reduce (and allows to distribute) maintenance/upgrade load on Devops/deployment managers
The goal of this AIP/Document is to get feedback from the wider community of Airflow on the proposed multi-team architecture to better understand if the proposed architecture is - in fact - addressing the needs of the user.
Airflow Survey 2023 shows that multi-tenancy is one of the highly requested features of Airflow. Of course multi-tenancy can be understood differently, this document aims to propose a multi-team model chosen by Airflow maintainers, not a "customer multi-tenancy", where all resources are isolated between tenants, but rather propose a way how Airflow can be deployed for multiple teams within the same organization, which we identified as what many of our users understood as "multi-tenancy". We chose to use "multi-team" name to avoid ambiguity of the "multi-tenancy". The ways how some levels of multi-tenancy can be achieved today is discussed in the “Multi-tenancy today” chapter and differences between this proposal and those current ways is described in the “Differences vs. current Airflow multi-team options”.
Motivation
The main motivation is the need for the users of Airflow to have a single deployment of Airflow, where separate teams in the company structure have access to only a subset of resources (e.g. DAGs and related tables referring to dag_ids) belonging to the team. This allows to share the UI/web server deployment and scheduler between different teams, while allowing the teams to have isolated DAG processing and configuration/sensitive information. It also allows a separate group of DAGs that SHOULD be executed in a separate / high confidentiality environment, also allows to decrease the cost of deployment by avoiding having multiple schedulers and web servers deployed.
Note that it does not prevent to run multiple schedulers - one per team if needed and if we implement support for it, but it is not a goal or motiviation of this AIP.
This covers the cases where currently multiple Airflow deployments are used in several departments/teams by the same organization and where maintaining (even if more complex) single instance of Airflow is preferable over maintaining multiple, independent instances.
This allows for partially centralized management of airflow while delegating the execution environment decisions to teams as well as makes it easier to isolate the workloads, while keeping the option of easier interaction between multiple teams via shared dataset feature of Airflow.
Wording/Phrasing
Note, that this is not a formal specification, but where emphasised by capital letters, The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in the RFC 2119
Considerations
Multi-tenancy today
There are today several different ways one can run multi-team Airflow:
A. Separate Airflow instance per-tenant
The simplest option is to implement and manage separate different Airflow instances, each with own database, web server, scheduler, workers and configuration, including execution environment (libraries, operating system, variables and connections)
B. Separate Airflow instance per-tenant with some shared resources
Slightly more complex option is to reuse some of the resources - to save cost. The Database MAY be shared (each Airflow environment can use its own schema in the same database), web server instances could be run in the same environment, and the same Kubernetes Clusters can be used to execute workloads of tasks.
In either of the solution A/B, where multiple Airflow instances are deployed, the AuthUI access of Airflow (especially with the new Auth Manager feature AIP-56) can be delegated to a single Authentication proxy (for example KeyCloak Auth Manager could be implemented that uses single KeyCloak authentication proxy to implement a unified way of accessing the various UI webserver instances of Airflow that can be exposed in a unified URL scheme).
C. Using a single instance of Airflow by different teams
In the Airflow as we have it today he execution and parsing environment “per-team” could be - potentially - separated for different teams.
You could have separate set of DAG file processors per each folder in Airflow DAG folder, and use different set of execution environments (libraries, system libraries, hardware) - as well as separate queues (Celery) or separate Kubernetes Pod Templates used to separate workload execution for different teams. Those are enforceable using Cluster Policies. UI access “per team” could also be configured via custom Auth Manager implementation integrating with organization-managed authentication and authorization proxy.
In this mode, however, the workloads still have access to the same database and can interfere with each other’s DB including Connections and Variables - wmanhich means that there is no “security perimeter” per team, that would disallow DAG authors of one team to interfere with the DAGs written by DAG authors of other teams. Lack of isolation between the team group is the main shortcoming of such a setup that compared to A. and B. this AIP aims to solve.
Also it is not at all "supported" by Airflow configuration in an easy way. Some users do it by putting limitations on their users (for example only using Kubernetes Pod Operator), some might implement custom cluster policies or code review rules to make sure DAG authors from different teams are not mixed with other teams, but there is no single, easy to use mechanism to enable it
Differences of the multi-team proposal vs. current Airflow multi-tenant options
How exactly the current proposal is different from is possible today:
- The resource usage for Scheduling and execution can be slightly lower compared to A. or B. The hardware used for Scheduling and UI can be shared, while the workloads run “per-team” would be anyhow separated in the similar way as they are when either A. or B. is used. Single database and single schema is reused for all the teams, but the resource gains and isolation is not very different from the one achieved in B. by utilizing multiple, independent schemas in the same database. Decreasing resource utilization is a non-goal of the proposal.
- The proposal - when it comes to maintenance - is a trade-off between complete isolation of the execution environment available in options A. and B. and being able to centralize part of the maintenance effort from option C. This has some benefits and some drawbacks - increased coupling between teams (same Airflow version) for example, but also better and complete workload isolation than option C.
- The proposed solution allows to - easier and more complete than via cluster policies in option C. - manage a separation between teams. With this proposal you can trust that teams cannot interfere with each other’s code and execution. Assuming fairness in Scheduling algorithms of the scheduler also execution efficiency between the teams SHOULD be isolated. Security and isolation of workflows and inability to interference coming from DAG authors belonging to different teams is the primary difference that brings the properties of isolation and security available in options A. and B. to single instance deployment of Airflow.
- The proposal allows to have a single unified web server entrypoint for all teams and allows to have a single administrative UI interface for management of the whole “cluster”.
- Utilizing the (currently enhanced and improved) dataset feature allowing teams to interface with each other via datasets. While this will be (as of Airflow 2.9) possible in options A. and B. using the new APIs that will allow sharing dataset events between different instances of Airflow, having a multi-team single instance Airflow to allow for dataset driven scheduling between teams without setting up authentication between different, independent Airflow instances.
- Allowing users to analyse their Airflow usage and corellation/task analysis with single API/DB source.
Credits and standing on the shoulders of giants.
Prior AIPs that made it possible
It took quite a long time to finalize the concept, mostly because we had to build on other AIPs - funcationality that has been steadily added to Airflow and iterated on - and the complete design could only be based once the other AIPs are in the shape that we coud "stand on the shoulders of giants" and add multi-team layer on top of those AIPs.
The list of related AIPs:
- AIP-12 Persist DAG into DB- initial decision to persist DAG structure to the DB (Serialization) - that allowed to have OPTIONAL DAG serialization in the DB.
- AIP-24 DAG Persistence in DB using JSON for Airflow Webserver and (optional) Scheduler - that allowed to separate "Webserver" nd extract it to "common" infrastructure.
- AIP-43 DAG Processor separation - it allowed to separate DAG Parsing and Execution environment from Scheduler and move Scheduler to "common" infrastructure
- AIP-48 Data Dependency Management and Data Driven Scheduling - introducing the concept of DataSets that could be used as "Interface" Between teams
- AIP-51 Removing Executor Coupling from Core Airflow - that decoupled executors and introduced clear executor API that allowed to implement Hybrid executors
- AIP-56 Extensible user management - allowing to have externally managed and flexible way to integrate with Organization's Identity services
- AIP-60 Standard URI representation for Airflow Datasets - implementing "common language" that teams could use to communicate via Datasets
- AIP-61 Hybrid Execution - allowing to have multiple executors - paving the way to have separate set executors per team
- AIP-72 Task Execution Interface aka Task SDK - allowing to use GRPC/HTTPS communication usig new Task SDK/API created for Airflow 3
- AIP-73 Expanded dataset awareness - and its sub-aips, redefinind datasets into data assets
Initially the proposal was based on earlier (Airflow 2) approach for DB access isolation based on AIP 44, but since we target this AIP for Airflow 3, it will be based on AIP-72 above
AIP-44 Airflow Internal API - (in progress) allows to separate DB access for components that can also execute code created by DAG Authors - introducing a complete Security Perimeter for DAG parsing and execution
Design Goals
Structural/architectural changes
The goal of the implementation approach proposed is to minimize structural and architectural changes in Airflow to introduce multi-team, features and to allow for maximum backwards compatibility for DAG authors and minimum overhead of Organization Deployment Managers. All DAGs written for Airflow 2, providing that they are using only the Public Interface of Airflow SHOULD run unmodified in a multi-team environment.
Minimum database structure needs to be modified to support multi-team mode of deployment.
The whole Airlfow instance continues to use the same shared DAG folder containing all the DAGs it can handle from all teams, however each team user might have access to only folder(s) belonging to that team and their Standalone Dag File Processor(s) will only work on those folders. This MAY be relaxed in the future, if we use different way of identifying source files coming from different teams than based on the location of the DAG in the shared DAG folder being the source of all DAGs.
Security considerations
The following assumptions have been made when it comes to security properties of multi-team Airflow:
- Reliance on other AIPs: Multi-team mode can only be used in conjunction with AIP-72 (Task Execution Interface aka Task SDK) and Standalone DAG file processor.
- Resource access security perimeter: The security perimeter for parsing and execution in this AIP is set at the team boundaries. The security model implemented in this AIP assumes that once your workload runs withing a team environment (in execution or parsing) it has full access (read/write) to all the resources (DAGs and related resources) belonging the same team and no access to any of those resources belonging to another team.
- DAG authoring: DAGs for each team are stored in a team-specific folder (or several folders per team) - this allows per-folder permission management of DAG files. Having teams based on team-specific folders allows for common organization DAG code managed and accessed by a separate “infrastructure” team within a deployment of Airflow. When Airflow is deployed in multi-team deployment, all DAGs MUST belong to exactly one of the teams.
- Execution: Both parsing and execution of DAGs SHOULD be executed in isolated environment. Note that Organization Deployment Managers might choose different approach here and colocate some or all teams within the same environments/containers/machines if the separation based on process separation is good enough for them.
- Data assets: Data assets containing URI are shared between teams in terms of assets events produced by one team might share the events by another team if they share the same URI. DAG Authors can produce and consume events from between teams if both are using the same URI , however DAG authors of consuming events from Datasets will be able to specify which other team's events will be consumed by them. That allows us to effectively share assets using URIs between different teams in organisation while giving control to the team which other teams can produce asset events that they react to.
- DB access: In Phase 2 of the implementation Airflow is deployed with internal API / GRPC API component enabled (separate internal API component per team) - this Internal API component only allows access to DAGs belonging to the team. Implementing filtering of access "per-team" in the Internal API component is part of this AIP.
- UI access: Filtering resources (related to DAGs) in the UI is done by the auth manager. For each type of resource, the auth manager is responsible for filtering these given the team(s) the user belongs to. We do not plan to implement such filtering in the FAB Auth Manager which we consider as legacy/non-multi-team capable.
- Custom plugins: the definition of plugin in Airflow cover a number of ways Airflow can be extended: plugins can contribute parsing and execution "extension" (for example macros), UI components (custom views) or Scheduler extensions (timetables). This means that plugins installed in "team" parsing and execution environment will only contribute the "parsing and execution" extensions, plugins installed in "scheduler" environment will contribute "scheduler" extensions, plugins installed in "webserver" will contribute "webserver" extensions. Which plugins are installed where, depends on those who manage the deployment. There might be different plugins installed by the team Deployment Manager (contributing parsing and execution extensions) and different plugins installed by the organization admin - contributing scheduler and UI extensions.
- UI plugins auth manager integration: Since webserve is shared, the custom UI plugins have to be implemented in multi-team compliant way, in order to be deployable in the multi-team environment. This means that they have to support AIP-56 based auth management and they have to utilize the feature of the Auth Manager exposed to it that it will allow to distinguish team users and their permissions. It MAY require to extend AuthManager API to support multi-team environments. A lot could be done with existing APIs and we do not technicallly have to support custom UI plugins at all for the multi-team setup. It MAY be easily implemented as a follow-up to this AIP add better support in the future.
- UI controls and user/team management: with AIP-56, Airflow delegated all responsibility to Authentication and Authorisation management to Auth Manager. This continues in case of multi-team deployment. This means that Airlfow webserver completely abstracts-away from knowing and deciding which resources and which parts of the UI are accessible to the logged-in user. This also means for example that Airflow does not care nor manages which users has access to which team and whether the users can access more than one team or whether the user can switch between teams while using Airflow UI. All the features connected with this are not going to be implemented in this API, particular implementations of Auth Managers might choose different approaches there. It MAY be that some more advanced features (for example switching the team for the user logged in) might require new APIs in Auth Manager (for example a way how to contribute controls to Airflow UI to allow such switching) - but this is outside of the scope of this AIP and if needed should be designed and implemented as a follow up AIP.
Design Non Goals
It’s also important to explain the non-goals of this proposal. This aims to help to get more understanding of what the proposal really means for the users of Airflow and Organization Deployment Managers who would like to deploy a multi-team Airflow.
- It’s not a primary goal of this proposal to significantly decrease resource consumption for Airflow installation compared to the current ways of achieving “multi-tenant” setyp. With security and isolation in mind, we deliberately propose a solution that MAY have small impact on the resource usage, but it’s not a goal to impact it significantly (especially compared to option B above where the same Database can be reused to host multiple, independent Airflow instances. However isolation trumps performance whenever we made design decision and we are willing to sacrifice performance gain in favour of isolation.
- It’s not a goal of this proposal to increase the overall capacity of a single instance of Airflow. With the proposed changes, Airflow’s capacity in terms of total number of DAGs and tasks it can handle is going to remain the same. That also means that any scalability limits of the Airflow instance apply as today and - for example - it’s not achievable to host multiple 100s or thousands of teams with a single Airflow instance and assume Airflow will scale it’s capacity with every new team
- It’s not a goal of the proposal to provide a one-stop installation mechanism for “Multi-team” Airflow. The goal of this proposal is to make it possible to deploy Airflow in a multi-team way, but it has to be architected, designed and deployed by the Organization Deployment Manager. It won't be a turn-key solution that you might simply enable in (for example) Airflow Helm Chart. However the documentation we provide MAY explain how to combine several instances of Airflow Helm Chart to achieve that effect - still this will not be a "turn-key", it will be more of a guideline on how to implement it.
- It’s not a goal to decrease the overall maintenance effort involved in responding to needs of different teams, but it allows to delegate some of the responsibilities for doing it to teams, while allowing to maintain “central” Airflow instance - common for everyone. There will be different maintenance trade-offs to make compared to the multi-team options available today - for example, the Organization Deployment Manager will be able to upgrade Airflow once for all the teams, but each of the teams MAY have their own set of providers and libraries that can be managed and maintained separately. Each deployment will have to add their own rules on maintenance and upgrades to maintain the properties of the Multi-team environmet, where they all share the same Airflow version but each of the teams will have their own set of additional dependencies. Airflow will not provide any more tooling for that than those existing today - constraint files, reference container images and documentation on how to build, extend and customise container images based on Airflow reference images. This might mean that when single Airflow instance has 20 teams, there needs to be a proper build and customisation pipeline set-up outside of Airflow environment that will manage deployment, rebuilds, upgrades of 20 different container images and making sure they are properly used in 20 different teame-specific environments deployed as parts of the deployment.
- It's not a goal to support or implement the case where different teams are used to support branching strategies and DEV/PROD/QA environments for the same team. The goal of this solution is to allow for isolation between different groups of people accessing same Airflow instance, not to support case where the same group of people would like to manage different variants of the same environment.
Architecture
The Multi team Airflow extends “Sepearate DAG processing” architecture described in the Overall Airflow Architecture.
Current "Separate DAG processing" architecture overview
The "Separate DAG processing" brings a few isolation features, but does not addresses a number of those. The features it brings is that execution of code provided by DAG authors can happen in a separate, isolated perimeter from scheduler and webserver. This means that today you can have a deployment of Airflow where code that DAG author submits is never executed in the same environment where Scheduler and Webserver are running. The isolation features it does not bring - are lack of Database access isolation and inability of DAG authors to isolate code execution from one another. Which means that DAG authors can currently write code in their DAGs that can modify directly Airflow's database, and allows to interact (including code injection, remote code execution etc.) with the code that other DAG authors submit. Also there are no straightforward mechanisms to limit access to the Operations / UI actions - currently the way how permissions are managed are "per-individual-DAG" and while it is possible to apply some tooling and permissions syncing to apply permissions to groups of DAGs, it's pretty clunky and poorly understood.
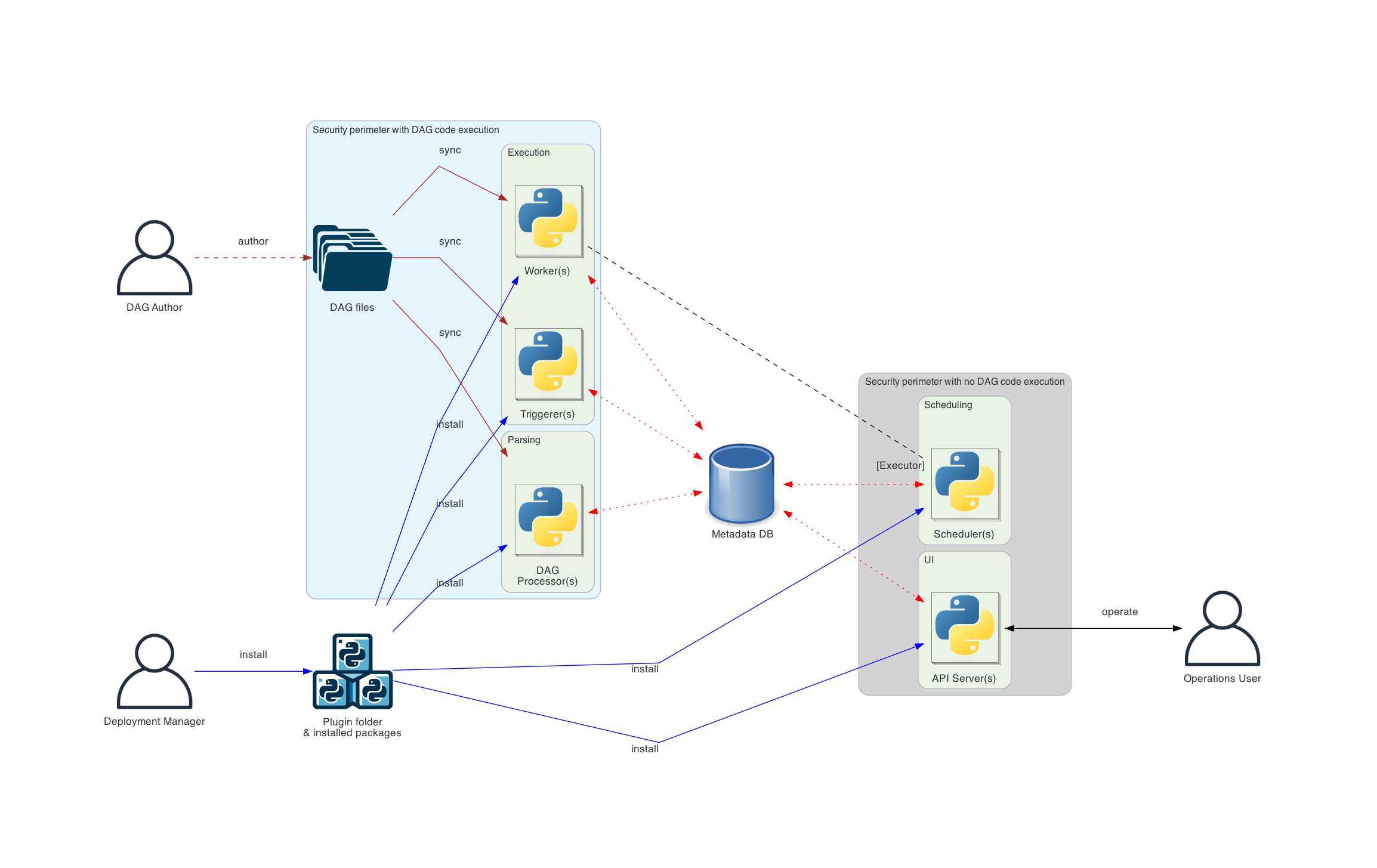
Proposed target architecture with multi-team setup
The multi-team setup - provides workload isolation while DB isolation will be provider by AIP-72.
Once AIP-72 is in place, this is a relatively small change comparing to the current Aiflow 3 proposal, that mostly focuses on isolating Dag File Processing and Task/Triggerer environment so that the code from one tenant can have different dependencies for different teams, the teams can have separate executors configured and their code can execute in isolation from other teams.
The multi-team setup provides:
- allows for separate set of dependencies for different teams
- it isolates credentials and secrets used by each team
- isolation of code workloads between teams - where code from one team is executed in a separate security perimeter

Implementation proposal
Managing multiple teams at Deployment level
Multi-team is a feature that is available to Organization Deployment Managers who manage the whole deployment environment and they SHOULD be able to apply configuration, networking features and deploy airflow components belonging to each team in an isolated security perimeter and execution environment to make sure they “team” environment does not interfere with other teams environment.
It’s up to the Organization Deployment manager, to create and prepare the deployment in a multi-team way. Airflow components will perform consistency checks for the configuration - verifying the presence of appropriate folders, per-team configuration etc., but it will not provide separate tools and mechanisms to manage (Add / remove / rename teams). Process of adding/removing teams will require manual deployment reconfiguration.
We do not expect nor provide tooling/UI/CLI to manage the teams, the whole configuration and reconfiguration effort required to reconfigure such team deployment should be implemented as part of deployment changes.
Executor support
The implementation utilizes AIP-61 (Hybrid Execution) support where each team can have their own set of executors defined (with separate configuration). While multi-team deployment will work with multiple Local Executors, it SHOULD only be used with Local Executor for testing purposes, because it does not provide execution isolation for DAGs.
Since each team has their own per-team configuration, in case of remote executors, credentials, brokers, k8s namespaces etc. can be separated and isolated from each other.
When scheduler starts, it instantiates all executors of all teams configured and passes each of them configuration defined in per-team configuration.
In the case of Celery Executor, several teams will use a separate broker and result backend. For the future we MAY consider using a single broker/result backend and use `team:` prefixed queues, but this is out of scope from this implementation.
Changes in DAGFileProcessor (integration wiht AIP-72 Task API)
In order to integrate with the Task API solution, the API introduced by AIP-72 will have to be extended to cover DAGFileProcessing (DAGFileProcessor will be a specialized Task)
- Scheduler requesting parsing to DAGFileProcessor
- Submitting serialized DAGs back to the API server
- Getting rid of callbacks executed by DAGFileProcessor currently (replacing them with callbacks requested by scheduler)
Changes in configuration
Multi-tenancy of scheduler and webserver is controlled by a "core/multi-team" bool flag (default False).
Each team configuration SHOULD be a separate configuration file or separate set of environment variables, holding team-specific configuration needed by DAG file processor, Workers and Triggerer. This configuration might have some data duplicated from the global configuration defined for webserver and scheduler, but in general the "global" airflow configuration for the organization should not be shared with "teams". This is "airflow configuration" as defined in the config file. Each team can also have access to separate Configuration and variables (identified by the team_id) but there are also common configurations and variables that might be shared between the teams (with null team-id). Uniqueness is maintained across all connection and variable ids between the teams (regardless if they have team_id or not).
Internal API / GRPC API components will have to have configuration allowing them to communicate with Airflow DB. This configuration should only be accessible by the internal API component and should not be shared with other components that are run inside the team. This should be part of the deployment configuration, the components should be deployed with isolation that does not allow the code run in DAG file processor, Worker or Triggerrer to be able to retrieve that configuration. Similarly none of the team components (including internal API component) should be able to retrieve "Global" configuration used by Scheduler and webserver.
The multi-executor configuration should be extended to allow for different sets of executors to be created and configured by different teams (and having separate configuration). That configuration is managed by the Organization Deployment Manager. This extends the configuration described in the AIP-61 Hybrid Execution. The proposal is to change the AIRFLOW__CORE__EXECUTOR env variable/configuration into array of tables defined by TOML specification and it will require changes in the configuration mechanism to use TOML rather than "INI" specification. TOML is a successor of "INI" filles that is standardized and heavily used in Python world already (pyproject.toml) for configuration purposes. It's largely backwards compatible with "ini" format used by Airflow currently but it allows for bigger spectrum of configuration options (it allows for arrays, tables and arrays of tables and nesting those).
Detailed configuration specification for executor is an implementation detail and will be worked out while the AIP is being implemented, but it should be similar to (this can be refined during implementation):
[[ executor ]]
teams = [ "team1", "team2" ]
[[ executor.team1 ]]
executors = [ "celery", "kubernetes"]
[[ executor.team1.celery ]]
class = CeleryExecutor
[[ executor.team1.celery.configuration ]]
key_1 = "value 1"
key_2 = "value 2"
[[ executor.team1.kubernetes ]]
class = KubernetesExecutor
[[ executor.team1.kubernetes.configuration ]]
key_1 = "value 1"
key_2 = "value 2"
[[ executor.team2 ]]
executors = [ "aws", "kubernetes" ]
[[ executor.team2.aws ]]
class = AWSExecutor
[[ executor.team1.aws.configuration ]]
key_1 = "value 1"
key_2 = "value 2"
[[ executor.team2.kubernetes ]]
class: KubernetesExecutor
[[ executor.team1.aws.configuration ]]
key_1 = "value 1"
key_2 = "value 2"
or:
[[team]] name = "team1" executors = ["celery", "kubernetes"] [[team.executor]] type = "celery" class = "CeleryExecutor" key_1 = "value 1" key_2 = "value 2" [[team.executor]] type = "kubernetes" class = "KubernetesExecutor" key_1 = "value 1" key_2 = "value 2" [[team]] name = "team2" executors = ["aws", "kubernetes"] [[team.executor]] type = "aws" class = "AWSExecutor" key_1 = "value 1" key_2 = "value 2" [[team.executor]] type = "kubernetes" class = "KubernetesExecutor" key_1 = "value 1" key_2 = "value 2"
The current airflow ENV_VARIABLE → CONFIGURATION mapping where __ denotes separation between segments will be extended to support this "nesting" of configuration components (AIRFLOW__CORE__EXECUTOR__TEAM1__KUBERNETES__CONFIGURATION__KEY_1=VALUE1).
This also opens up the possibility of having more than one executor of the same type defined for the same team, extending capabilities of AIP-61 Hybrid Execution. In the follow up AIP we might also allowing a "global" executor entry for non-multi-team environments and we MAY extend it even further to allow combined "global" and "multi-team" deployment into a single deployment, but this is a non-goal of this AIP.
This configuration is not backwards-compatible with the single-team configuration. We will convert the current configuration file automatically during migration to Airflow 3 so that single team/hybrid executor (AIP-61) setting can also be supported by the new TOML syntax, This will extend AIP -61 with capability (foreseen in the AIP as extension) of allowing multiple executors of the same type in single installation (single team in case of multi-team setup.
[[ executor ]]
executors = [ "celery1", "celery2", "kubernetes"]
[[ executor.celery1 ]]
class = CeleryExecutor
[[ executor.celery1.configuration ]]
key_1 = "value 1"
key_2 = "value 2"
[[ executor.celery2 ]]
class = CeleryExecutor
[[ executor.celery2.configuration ]]
key_1 = "value 1"
key_2 = "value 2"
[[ executor.kubernetes ]]
class = KubernetesExecutor
[[ executor.kubernetes.configuration ]]
key_1 = "value 1"
key_2 = "value 2"
Connections and Variables access control
In multi-team deployment, Connections and Variables might be assisgned to team_id via external mapping table. Also each team has their own configuration specifying the Secrets Manager they use and has access to their own specific connections and variables and access to connections and variables via secret manager might be controlled by service accounts in team environment, or more broadly credentials used by each team. This will be coordinated with AIP-72, most likely this is only needed for UI control and management - because AIP-72 does not introduce a way to distinguish who has access to each connection via UI. Likely - with AIP-72 tasks will not have direct access to secrets managers, the secrets will be injected into the tasks and DAG parsers, so only UI distinction is needed.
The UI of Airflow for managing connections and variables should implement rules (to be defined) to assign default team_ids to connections/variables. The "admin" role should be defined to allow creating connections/variables for different teams than your own or "global".
Pools
Pools will get additional team_id field which will be nullable. This means that Pools can be either shared, or specific "per-team". For example (depending on the deployment decisions) - default_pool might be "common" for all teams or each team can have their own default_pool (configurable in team configuration file/env variable). DAGFileProcessor will fail parsing DAG files that will use pools belonging to other teams. while scheduling will remain unchanged for pools.
Dataset triggering access control
While any DAG can produce events that are related to any data assets, the DAGs consuming the data assets will - by default - only receive events that are triggered in the same team or by an API call from a user that is recognized to belong to the same team by Auth Manager. DAG authors could specify a list of teams that should additionally be allowed to trigger the DAG (joined by the URI of the Data Asset) by adding a new asset parameter and the triggering will happend. Also this AIP depends on AIP-73 - Expanded Data Awareness - and the exact approach will piggiback on deailed implementation of Data ASsets..
allow_triggering_by_teams = [ "team1", "team2" ]Changes in the metadata database
The structure of the metadata database introduces a new "team_id" identifier accross the DAG/DAG_RUN/TASK/TASK_INSTANCE/CONNECTIONS/VARIABLES families of tables (however for Connections/Variables new tables are going to be created to keep team_id assignments- in order to allow multiple teams to share the same connection/variable).
Due to the limitations of various databases (MySQL) the actual implementation of DAG family tables will depend on the choice of supported databases in Airflow 3. There are two options of implementing it:
- If we choose Postgres DB/SQLITE only, we can extend the current approach where dag_id, task_id, dag_run_id by adding team_id as another column
- If we stick to MySQL we will have to restructure Airflow DB to use a unique syntetic uuid6/uuid7 identifier that will be used across all other tables that refer to DAG
The fillowing tables are also affected:
- CONNECTION and VARIABLE tables will have `team_id" additional field denoting to which team the connection/variable belongs (nullable)
- DATA_ASSET tables will have "team_id" field
- POOL table also gets team_id added to it's unique index (but nullable)
- No "team" nor team management table is foreseen in this AIP - this might be changed in the futur
Airflow scheduler runs scheduling unmodified - as today - with the difference that it will choose the right sets of executors to send the dags to, based on the team of the DAG.
We MAY consider adding per-team concurrency control (later) and prioritization of scheduling per team but it is out of the scope of this change. It MAY even turn to be not needed, providing that we will address any potential scheduling fairness problem in the current scheduling algorithm, without the need of having a specific per-team prioritization and separation of scheduling per-team.
The current separation of scheduling and execution in Airflow internal architecture, SHOULD cope pretty well with fairnes of scheduling - currently Airflow copes pretty well with “fair” scheduling decisions involving hundreds and thousands of independent DAGs and there are very few issues - if any - connected with Airflow not being able to create DAG runs and mark tasks as ready for execution, and there seems to be not many cases where scheduling decisions are starved between DAGs. Therefore it seems reasonable to assume that this algorithm continue to be fair and efficient, when multiple teams are involved. It’s worth noting that scheduling decisions are made mostly upfront - DAG runs are created before tasks are eligible for execution, so bulk of the work necessary to prepare tasks for execution is not time-critical and Airflow can efficiently scale to tens of thousands of DAGs with those. Also the scheduling decision capacity can be increased by using multiple schedulers in Active-Active HA setup, which means that generally speaking it does not really matter how many teams there are configured - overall scheduling capacity depends on the number of DAGs and tasks handled by the Airlfow instance - and increasing that capacity is a non-goal of this proposal.
The more important aspect here which does impact the fairness and potential starvation problem between teams is addressed by utilizing multiple executors (and separate executors per team). It’s the executor that handles the actual workload of performing “task execution” once the task are ready to be executed, and properly isolating the executors is far more important in the context of isolation and starvation than isolating scheduling decisions .
UI modifications
Changes to the UI, filtering is done by AuthManager based on presence of team_id:: the way how to determine which team prefixes are allowed for the user SHOULD be implemented separately by each AuthManager. Each user served by AuthManager can belong to one or many teams and access to all resources in the UI will be decided based on the team the resource belongs to.
Team flag
Originally in this AIP each of the affected "team" components was supposed to have a new "–team" flag that would limit the scope of the team access to particular team. This is no longer needed as AIP-72 provides per-task isolation and authentication of executed workfload and separation of workload per-team is done purely on the base of which executor is used to handle given task and it is decided by the scheduler.
Per-team deployment
Since each team is deployed in its own security perimeter and with own configuration, the following properties of deployment can be defined per-team:
- set of dependencies (possibly container images) used by each team (each component belonging to the team can have different set of dependencies)
- credential/secrets manager configuration can be specified separately for each team separately in their configuration
- team components MUST only have access their own team configuration, not to the configuration of other teams
This introduces a separate Parsing/Runtime environment that is specific "per-team" and not shared with other teams. While the environments are separate and isolated, there are some limits for the environment that introduce some coupling between them:
- All the environments of all teams have to have the same Airflow version installed (exact patch-level version)
- Dependencies installed by each team cannot conflict with that of Airflow core dependencies or other providers and libraries instaled in the same environment
- No connections or variables are visible in UI of multi-team Airflow. All Connections and Variables must come from Secrets Manager
Roles of Deployment managers
There are two kinds of Deployment Managers in the multi-team Airflow Architecture: Organisation Deployment Managers and team Deployment Managers.
Organization Deployment Managers
Organization Deployment Managers are responsible for designing and implementing the whole deployment including defining teams and defining how security perimeters are implementing, deploying firewalls and physical isolation between teams and figure out how to connect the identity and authentication systemst of the organisation with Airflow deployment. They also manage common / shared Airflow configuration, Metadata DB, the Airflow Scheduler and Webserver runtime environment including appropriate packages and plugins (usually appropriate container images), Manage running Scheduler and Webserver. The design of their deployment has to provide appropriate isolation betweeen the security perimeters. Both physical isolation of the workloads run in different security perimeters but also implementation and deployment ot the appropriate connectivity rules between different team perimeters. The rules implemented has to isolate the components running in different perimeters, so that those components which need to communicate outside of their security perimeter can do it, and make sure the components cannot communicate with components outside of their security perimeters when it's not needed. This means for example that it's up to the Organisation Deployment manager to figure out the deployment setup where Internal APIs / GRPC API components
running inside of the team security perimeters are the only componets there that can commmunicate with the metadata Database - all other components should not be able to communicate with the Database directly - they should only be able to communicate with the Internal API / GRPC API component running in the same security perimeter (i.e. the team they run in).
When it comes to integration of organisation's identity and authentication systems with airflow such integration has to be performed by the Deployment Manager in two areas:
- Implementation of the Auth Manager integrated with organization's identity system that applies appropriate rules that the operations users that should have permissions to access specific team resources, shoudl be able to do it. Airflow does not provide any specific implementation for that kind of Auth Manager (and this AIP will not change it) - it's entirely up to the Auth Manager implementation to assign appropriate permissiosn. The Auth Manager API of Airflow implemented as part of AIP-56 providers all the necessary information to take the decision by the implementation of such organisation-specific Auth Manager
- Implementation of the permissions for the DAG authors. Airflow completely abstract away from the mechanisms used to limit permissions to folders belonging to each team. There are no mechanisms implemented by Airflow itself - this is no different than today, where Airflow abstracts away from the permissions needed to access the whole DAG folder. It's up to the Deployment Manager to define and implement appropriate rules, group access and integration of the access with the organisation's identity, authentication, authorisation system to make sure that only users who should access the team DAG files have appropriate access. Choosing and implementing mechanism to do that is outside of the scope of this AIP.
- Configuration of per-team executors in "common" configuration - while Tenatn Deployment Managers can make decisions on runtime environment they use, only Organization Deployment Manager can change the executors configured for each team.
Team Deployment Managers
Team Deployment Manager is a role that might be given to other people, but it can also be performed by Organization Deployment Managers. The role of team Deployment Manager is to manage configuration and runtime environment for their team - that means set of pacakges and plugins that should be deployed in team runtime environment (where Airflow version should be the same as the one in the common environment) and to manage configuration specific "per team". They might also be involved in managing access to DAG folders that are assigned to the team, but the scope and way of doing it is outside of the scope of this AIP. team Deployment managers cannot on their own decide on the set of executors configured for their team. Such configuraiton and decisions should be implemented by the Organization Deployment Manager.
Team Deployment Managers can control resources used to handle tasks - by controlling the size and nodes of K8S clusters that are on the receiving end of K8S executor, or by controlling number of worker nodes handling their specific Celery queue or by controlling resources of any other receiving end of executors they use (AWS/Fargate for example). In the current state of the AIP and configuration team Deployment Manager must involve Organization Deployment Managers to change certain aspects of configuration for executors (for example Kubernetes Pod templates used for their K8S executor) - however nothing prevents future changes to the executors to be able to derive that configuration from remote team configuration (for example KPO template could be deployed as Custom Resources at teh K8S cluster used by the K8S executor and could be pulled by the executor.
Team Deployment Managers must agree the resources dedicated for their executors with the Organization Deployment Manager. While currently executors are run inside the process of Scheduler as sub-processes, there is little control over the resources they used, as a follow-up to this AIP we might implement more fine-grained resource control for teams and executors used.
Support for custom connections in Airflow UI
Similarly as in case of other resources - connections and variables belonging to specific team will only be accessible by users who belong to that team.
Why is it needed?
The idea of multi-tenancy has been floating in the community for a long itme, however it was ill-defined. It was not clear who would be the target users and what purpose would multi-tenancy serve - however for many of our users this meant "multi-team"
This document aims to define multi-team as a way to streamline organizations who either manage themselves or use a managed Airflow to setup an instance of Airflow where they could manage logically separated teams of users - usually internal teams and departments within the organization. The main reason for having multi-team deploymnent of Airflow is achieving security and isolation between the teams, coupled with ability of the isolated teams to collaborate via shared Datasets. Those are main, and practically all needs that proposed multi-team serves. It's not needed to save resources or maintenance cost of Airflow installation(s) but rather streamlining and making it easy to both provide isolated environment for DAG authoring and execution "per team" but within the same environment which allows for deploying "organisnation" wide solutions affecting everyone and allowing everyone to easily connect dataset workflows coming from different teams.
Are there any downsides to this change?
- Increased complexity of Airflow configuration, UI and Multiple Executors.
- Complexity of deployment consisting of a number of separate isolated environment.
- Increased responsibilty of maintainers with regards to isolation and taking care about setting security perimeter boundaries
Which users are affected by the change?
- The change does not affect users who do not enable multi-team mode. There will be no database changes affecting such users and no functional changes to Airflow.
- Users who want to deploy airflow with separate subsets of DAGs in isolated teams - particularly those who wish to provide a unified environment for separate teams within their organization - allowing them to work in isolated, but connected environment.
- Database migration is REQUIRED as well as specific deployment managed by the Organization Deployment Manager has to be created
What defines this AIP as "done"?
- All necessary Airflow components expose –team flags and all airflow components provide isolation between the team environment (DAGs, UI, secrets, executors, ....)
- Documentation describes how to deploy multi-team environment
- Implemented simple reference implementation “demo” authentication and deployment mechanism in multi-team deployment (development only)
What is excluded from the scope?
- Sharing broker/backend for celery executors between teams. This MAY be covered by future AIPs
- Implementation of FAB-based multi-team Auth Manager. This is unlikely to happen in the community as we are moving away from FAB as Airflow's main authentication and authorisation mechanism.
- Implementation of generic, configurable, multi-team aware Auth Manager suitable for production. This is not likely to happen in the future, unless the community will implement and release a KeyCloak (or simillar) Auth Manager. It's quite possible however, that there might be 3rd-party Auth Managers deployed that will provide such features.
- Per-team concurrency and prioritization of tasks. This is unlikely to happen in the future unless we find limitations in the current Airlflow scheduling implementation. Note that there are several phases in the process of task execution in Airflow. 1) Scheduling - where scheduler prepares dag runs and task instances in the DB so that they are ready for execution, 2) queueing - where scheduled tasks are picked by executors and made eligible for running 3) actual execution where (having sufficient resources) executors make sure that the tasks are picked from the queue and executed. We believe that 1) scheduling is suffificiently well implement in Airflow to avoid starvation betweeen teams and 2) and 3) are handled by separate executors and environments respectively. Since each team will have own set of executors, and own execution environment, there is no risk of starvation between teams in those phases as wel, and there is no need to implement separte prioritisation.
- Resource allocation per-executor. In the current proposal, executors are run as sub-processes of Scheduler and we have very little control over their individual resource usage. This should not cause problems as generally resource needs for executors is limited, however in more complex cases and deployments it migh become necessary to limit those resources on a finer-grained level (per executor or per all executors used by the team). This is not part of this API and will likely be investigated and discussed as follow-up.
- Turn-key multi-team Deployment of Airflow (for example via Helm chart). This is unlikely to happen. Usually multi-team deployments require a number of case-sepecific decisions and organization-specific integrations (for example integration with organization's identity services, per-team secrets managements etc. that make it unsuitable to have 'turn-key' solutions for such deployments.
- team management tools (creation, removal, rename etc.). This is unlikely to happen in the future, but maybe we will be able to propose some tooling based on experience and expectations of our users after they start using multi-team setup. The idea behind multi-team proposed in this AIP is not to manage dynamic list of teams, but fairly static one, that changes rarely. Configuration, naming decisions in such case can be done with upfront deliberation and some of the steps there (creating configurations etc. ) can be easily semi-automated by the Organization Deployment Managers.
- Combining "global" execution with "team" execution. While it should be possible in the proposed architecture to have a "team" execution and "global" execution in a single instance of Airflow, this has it's own unique set of challenges and assumption is that Airflow Deployment is either "global" (today) or "multi-team" (After this AIP is implemented) - but it cannot be combined (yet). This is possible to be implemented in the future.
- Running multiple schedulers - one-per team. While it should be possible if we add support to select DAGs "per team" per scheduler, this is not implemented in this AIP and left for the future
57 Comments
Jens Scheffler
Thanks for the summary and write-up! This is very much in accordance to the individual pieces I have seen today. This is great, now we can direct everybody asking for this to this AIP. Looking forward for the "small leftovers" to completion and the official docs. Actually in level of quality I do see this almost in review, very much post-draft
Jarek Potiuk
Thanks Jens Scheffler and Shubham Mehta for the comments. I addressed all the comments so far - feel free to mark the comments as resolved if you think they are
Jarek Potiuk
I updated the diagram better reflecting the separation now.
Niko Oliveira
Thanks for the AIP Jarek, it stitches many pieces together and we're getting close to a very nice and holistic solution.

I left a number of inline comments and look forward to more discussion
Cheers!
Jedidiah Cunningham
Can you restate the "why"? I feel like I'm missing something.
My initial reaction is why would org deployment managers want to take on the complexity of this? We aren't hand holding much at all. Even for power users, the only concrete goals I'm seeing, that aren't in the other approaches and/or a wash relative to them, is cross-tenant datasets and single ingress point. Did I miss others?
I understand the guard rails you are trying to put around this to, I just worry that this vision of multitenancy isn't what the average user had in mind when they chose it on the survey.
Another risk I see is complexity for maintainers, to make sure we aren't breaking this. Especially if there isn't an auth manager that unlocks this for local dev. Is that flow something you've given thought to?
Shubham Mehta
I can try to take a shot at this...
I think the primary motivation behind this multi-tenancy approach is to enable organizations to have a single Airflow deployment that can serve multiple teams/departments, while providing strong isolation and security boundaries.
The 3 key words are: Isolation, Collaboration, and Centralized management. A reduction in a portion of the cost is an added advantage, of course.
As a data platform team (or deployment manager), maintaining multiple Airflow deployments means you need to manage networking configuration, Airflow configuration, and compute for multiple instances, and this is not an easy job even for a single instance, let alone multiple instances – the primary reason managed service providers have a business value 😅. Based on my conversations with at least 30+ customers, they'd like to reduce the work they are doing in managing environments and rather focus on building additional capabilities like enabling data quality checks and lineage on their environment. Not to mention that having one environment makes it easier to bring other pieces from the Airflow ecosystem and make them available to all tenants. It also makes it easier to keep all teams upgraded to the latest/newer version of Airflow. Yes, it also increases responsibility as now teams need to move together, but the benefits outweigh the added effort.
As for the lack of a concrete turn-key solution or an out-of-the-box auth manager, the idea is to provide the necessary building blocks and guidelines for organizations to implement multi-tenancy in a way that aligns with their specific needs and existing infrastructure. Moreover, I believe this is an important first step, and the tooling around it would evolve as more community members adopt it. I don't think 2 years down the road, the setup for a multi-tenant deployment would look as complex as it looks on the first read of this doc. The pieces Jarek described are essential to get this off the ground, and then we can have the ecosystem and open-source do its magic.
I can confirm that anecdotally this is what users mentioned in my discussions with them. I definitely can't confirm for all the survey takers.
This is a fair ask, and I think having a Keycloak auth manager that enables this for local development should be considered. Given the work mentioned in this AIP, I am afraid to state that as a goal, but it should be mentioned as future work at least.
Jarek Potiuk
I think Shubham Mehta responded very well and follows very closely the way of thinking of mine. And thanks Jedidiah Cunningham for asking this very question - because this is precisely what I was hoping for when I created the document - that this question will be asked and that we will discuss it.
And yes - you might be surprised, but I do agree it's not MUCH of a difference vs. what you can do today. This was exactly the same thought I had - almost literally the same words you put it in - when I wrote the first draft of it. And I decided to complete the document and describe in more detail what it would mean, add the comparision, very explicitly state the roles of Deployment Managers and clarify what they will have to take care about and explain in detail what is "included" and what is "excluded" - i.e. delegated to the Deployment Manager "effort" that needs to be put in order to get multi-tenant deployment.
And also yes - I am even 100% sure that this vision is not the same that average responded to our survey had in mind when they responded "Yes" for multi-tenancy. But, that made me even more eager to write this AIP down, to simply make sure that those who care and want it - will have a chance to take a look and actually understand what we are proposing, before implementing all of it.
Internal API being still not complete and enabled, but also -currently very little impacting Airflow regular development - we might still be able to decide what to do and when there, and when to put more effort on completing it. And I deliberately did not hurry with that work on AIP-44 and later even tried to mininimise the unexpected impact it had on Airflow and other things we implemented in the meantime (for example by moving Pydantic as optional dependency after it turned out that Pydantic 1 vs. Pydantic 2 had causes some unexpected compatibility issues for external libraries that used Pydantic).
All that because I actually realised some time ago (and while writing this AIP it turned out into a more concrete "why") - that one of the viable paths we might take is NOT to implement AIP-67. But even if we decide not to do it, we need to know WHAT we decide not to do.
But I am still hopeful that there will be enough of the users that will see value and their "Multi-Tenancy" vision very nicely fit into what we proposal - say if we had even 30% of the 50% of our respondents who voted "yes" on Multitenancy, we already arrive at 15% of our respondents, and that might be significant enough of a user base to decide "yes, it's worth it".
Of course the question is "How do we find out?" → and my plan is as follows:
1) we complete discussion on this AIP, clarify outstanding points (many of them are already clarified and updated/changed)
2) we involve the users - Shubham Mehta already - as you see - already started to reach out, and I am also asking Astronomer, and Google to reach out and get their customers chime in
3) I personally know ONE user - Wealthsimple - who are my customer, and I spoke to them before and (they have not seen the doc yet - only some early draft which was far from complete) - I got a lot of the ideas on what should be in and what should be out from the discussions I had with them. So - in a way - this is tailored proposal for a customer of their size. Customer who has < 100 independent groups of DAG authors, and their platform team struggles on how to separate them but at the same time run them on a consistent set of platforms. For various reasons having multiple instances of Airflow or using services are not possible for them.
The key person - Anthony - is back from holidays soon but they promised to take a very close look and give feedback on how they see the value it brings them.
But of course it might be that I am heavily biased and they are. outlier in the whole ecosystem of ours . I take it into account seriously.
. I take it into account seriously.
4) Once I get that initial feedback flowing in (and I think we have enough momentum and incentive to bring quite a lot of that kind of feedback) I already reached out at our #sig-multitenancy group - where people in the past expressed their interest - to give their feedback and I also plan to have a call where I will explain it all and try to get feedback and encourage people to give more feedback asynchronously.
And ... Well ... we should be far more equipped after all that feedback to get a final discussion on devlist and vote
Elad Kalif
I think this is a great AIP and I am very happy with it.
I left some inline comments (more of future thoughts).
Jarek Potiuk
Niko Oliveira - > after some thinking and following your comments on the previous image I decided to change slightly the approach for configuration - actually simplifying it a bit when it comes to management (I mentioned that I am considering that in previous comments). That will actually even simplify the implementation, as rather than implementing a way how to read configuration from multiple sources, we delegate the task to keeping common configuration in multiple places to the deployment (and it can even be automated by deployment tools like Terraform/Open-Tf,Puppet, Chef etc - the only thing we will have to implement is a way how we configure multiple executors for tenants in Scheduler. I proposed somethig simple - taking into account that we can have dictionaries simply as strings in both env variables and in config files. That seems like most reasonable and simple approach we can take. See the "Changes in configuration" chapter and updated architecture diagram - it should explain a lot.
Niko Oliveira
> 'This configuration might have some data duplicated from the global configuration defined for webserver and scheduler, but in general the "global" airflow configuration for the organization should not be shared with "tenants".'
I'm very happy now with this piece, I think it sets a safer boundary to begin with.
As for dict base executor config, that would be a breaking change. Although, to get around that we could teach Airflow to understand that config as both a string/list (in the current/classic way we do now) and also a dict. That would be backwards compatible. I chose to keep a string (parsed as a list of course) in AIP-61 for this reason to keep this simplified (and of course we don't have tenants yet).
But I still wonder if we can keep executor config within the Tenants config file. Since I think tenants may want to iterate on that config frequently (setting tags, run-as users, and other tweaks to their executor config) and having to contact the cluster/environment admin to get those changes reflected in the common config deployed with the scheduler would be frustrating. Although for those changes to take effect they need a scheduler restart anyway so maybe it's not terrible? I'm still on the fence here.
Jarek Potiuk
Back -compatibilithy in this case is not a concern (I am going to have "multi-tenant" flag that will change how executor configuration is parsed. I think we will never mix multi- and single- tenant and switching between the two will be much more than just swapping configuration
I am afraid we cannot make it part of the tenant configuration. Look at the image. Choosing which executor you have is firmly on the right side - inside scheduler. I think changing the set of executors per-tenant is part of the global configuration effort and the "Organization Deployment Manager" is the one who will HAVE TO be involved when it changes. You wil need a redis queue and a way from schediler to communicate with it for example when you will add Celery executor. Or Kubernetes credentials and a way to communicate from scheduler to the K8S cluster you want to use. if you want to add K8S one, or AWS credentials if you want to use any of the AWS executors. This all should not be decided single-handedly by the Tenant Deployment Managers - this need to be "central " part of the configuratio - I do not see any other way here. On the other hand Tenant Deployment managers will be able to control and tweak the actual "execution". Adding more Celery workers to handle the Tenant queue? Sure - it's just increasing number of replicas of those, adding new node to the K8S cluster that accepts new Pods scheduled by the scheduler's K8S executor ? Hell yeah. Increase the Fargate capacity - absolutely. All that can be done without changing the configuration that sits in executor.
Of course we will not be able to change some things - KPO template for one - and this is potentially problematic, and it would be great if it can be configured by Tenant Deployment Manager on their own without involving Organization Deployment Manager. But that would likely require to add some split of responsibility - for example I could see that such template might be deployed as custom resource definition in the Target K8S, and K8S executor could pull that before launching POD. But that would be definitely out-of-scope of that AIP.
I will add notes about those two cases.
Jarek Potiuk
Updated.
Jarek Potiuk
I added a few more clarifications - like I stated what isolation level are currently provided by "separate dag processor" architecture and what is the isolation that the new architecture brings.. Just realised it could at a bit better context to the whole proposal.
Tzu-ping Chung
I find the title a tad weird. Multi-tenancy usually means to host different tenants in one deployment, but this pruposal is kind ot approaching the same problem multi-tenancy solves, but entirely from another direction. Instead of having one deployment host multiple tenants, a better description to the approach here IMO would be to allow multiple deployments, each hosting one tenant, share components. This sounds a good idea to me, but describing it as multi-tenancy would potentially be confusing and frustrate users if they try to use it in a way that does not work.
Jarek Potiuk
I 100% agree with your assessment on what this AIP is about. This was exactly my line of thought. And I believe th title directly reflect it. It's not 'Airflow Multi-Tenancy". It's merely a way how to deploy and connect airflow components to achieve Multi-Tenant deployment. I thought the title is exactly about this - and also the doc describes what we want to achieve as I 100% agree that various people might understand multi-tenancy in different ways. But if there are other proposals for name to Better reflect it - I am absolutely open to change the title. Any better ideas ?
Tzu-ping Chung
I understand the difference, but am not sure users will. Multi-tenancy has been talked about so much in the community, it seems destined to me most people will misunderstand the feature. I would prefer to not have tenant anywhere in both the proposal and implementation.
Jarek Potiuk
I think tenant (and multi) is actually a very good part of it. And that's why we explain it to get clarity. The `tenant` is precisely what it is all about. Airlfow Deployment managed by "Owner" (Organization Deployment Manager) where "Tenants" (Usually Department Deployment Manager - see Shubham Mehta 's use case in the devlist thread) who are independently occupying their part od the deployment. I personally think Tenant is perdectly describing this. And I have not seen yet any other proposal, but if there is a good proposal, for this I am sure we can consider it - and maybe even vote for it if there will not be a consensus.
While there were many discussions - I think currently there is no clear notion of what Tenant would mean in the context of Airflow. And we have a chance to explain it, define and deploy. Rather listen to (disorganized, not clear and not well defined) chatter of what Tenant in Airflow context mean, we take the reigns and define it. We shape it rather than try to fit into what some people might vaguely think it might mean. And I will stress it here __vaguely__ - no-one, literally no-one so far had no concrete idea what "multi-tenancy" in Airflow context is. In **some** other context it might mean something different - wherever you look at - multi-tenancy is defined differently. But if you for example look at K8S https://kubernetes.io/docs/concepts/security/multi-tenancy/ - they have two concept of tenancy "multi-customer" and "multi-team" tenancy. And what the AIP proposes here is really "multi-team" tenancy, not the "multi-customer" one. And while we could name it "Multi-team tenant deployment", even K8s opted for generic "multi-tenant" name and explained what it means - with similar thing - "some" resource sharing, a lot more of isolation security, and a bit of common management. So it's not that alien to use the "tenant" concept in context of "tenant teams" rather than "customers" in our world.
I think we have a long history (take Triggerer for example) of picking names and THEN defining what it really is by actual way it is implemented in the context of Airflow. Picking
tenantname that is currently not existing at all in Airflow world and defining it is exactly what IMHO we should do now, when we have a chance, rather than introducing another name. I would be worried if there was another "Tenant" concept making Airflow "customer multi-tenant", but ... there is none in sight. And we have a chance to use the shortcut "Multi-Tenant" meaning "multi-team tenant" under the hood.But I am perfectly open to another name - if somoene has a good suggestion, I am all ears. And I think if there are - we might have a separate discussion on **just** naming the feature providing that it will be accepted as concept in the community.
Amogh Desai
I really like the way this has been written with utmost detail and I am generally happy with this AIP. Happy to see this finally shaping up.
Some points I want to discuss:
Jarek Potiuk
a) This it is described in 'Runtine environment's - look closer - it's repeated several times as well . I might want to add even more explicit sentence but this is one of the big advantages of this approach that you can have different runtime environment for the same airflow instalation. In the future (but this is something way later) we might even introduce a runtime airflow package that will be 'minimal' airflow package with minimal set of dependencies compatible with given airflow version. But that will be much later and I did not want to cloud this AIP with this option (but I might add it as future improvement now that I think about it)
b) I think there is nothing against building such deployment in Yunicorn. But this is very external to this AIP. This AIP shows what can be done by deploying airflow cmponent in a way to achieve multi-tenant deployment. How it is done - whether with Yunicorn or Terraform or multiple charts - is totally out of scope of this AIP. This AIP just explains all conditions that has to be made to achieve multi-tenant deployment and it ends here future AIPs might build on top of it andescribe Moe 'opinionated ways how to do it - but lets get this one in first.
C. Cool
Elad Kalif
Jarek Potiuk What is the plan for DAG Dependency page? With in a tenant it's simple but what happens if tenant A takes triggers a dag in tenant B say with TriggerDAGRunOperator?
There is aspect if this can be done and if so how do we make sure that DAG Dependency page shows only what it needs to?
Jarek Potiuk
That is a very good question. For now I assumed that DAG triggering needs no special access within the same airflow instance. And that is the same for "dataset" triggering and "dag" triggering knowing their name. And I thought to defer the access control for later. But now, you are the second one to raise a concern there (Shubham Mehta was the first one), so maybe we should indeed add a mechanism to control it. A bit of complexity there is that you need to add a new "tenant" level access. Because (unlike with the API calls) we are not able to distinguish particular users who are triggering the DAG in either of the ways. They are triggered not by an authorised person, but by the "tenant" (in other words any one of the DAG authors of the tenant). And this is not covered, nor controlled by the Auth Manager (this is a UI-access concept only and we are talking about backend-triggered access level here).
A simple solution there would be to have "alllow-triggering-by-tenants" (name to be defined) property of DAG, which could nicely solve the issue. It could be a list of globs to match tenants who can trigger the dag. So for example:
"allow-triggering-by-tenants": ["*"]
would allow any other tenant to trigger it
"allow-truggering-by-tenants": [ "tenant-1", "tenant-2"]
would allow those tenants to trigger
"allow-truggering-by-tenants": [ "tenant-marketing-*", "tenant-ceo"]
would allow all marketing teams and ceo "special" tenant to trigger the DAG.
That's all of course ten(t)ative . Andi it would apply to both direct triggering as well as dataset triggering. Simply in the "dataset" case we will not emit events if the target DAG has no permissions to allow it.
. Andi it would apply to both direct triggering as well as dataset triggering. Simply in the "dataset" case we will not emit events if the target DAG has no permissions to allow it.
But it woudl have a nice few properties:
It does not seem to add a lot of complexity. Should be pretty easy to include in the AIP
Let me know what you think
Shubham Mehta
I think the proposed solution would work quite nicely. This would introduce the concept of DAG/dataset Consumers and ensure that only those who have access to consume or utilize those resources can do so.
I think this also means, similar to DAGs, we need to have a concept of dataset owner/producer - a tenant that primarily owns the dataset and would be defining the list of tenants in "allow-triggering-by-tenants". This could again be a tenant name that is added as prefix to the dataset.
That said, I really think we should mark this as future work and keep the scope of this AIP limited. We can call it out explicitly so that folks reviewing the AIP are aware of it. My main rationale is that we will learn a lot when users start using this and users who really need it would create Github issues (or even contribute) for the cases they'd like to handle. We can't possibly nail down all the diverse use cases that users will come up with.
Vincent BECK
I agree. As mentioned by Jarek, when a DAG is triggered by a dataset or another DAG, it is not an action triggered by the user. The auth manager is only responsible of authorizing user actions (through the UI or Rest API). Thus, this cannot be covered by the auth manager.
The little thought I already had on that topic was we would need to create some new configuration in the DB/UI to configure which tenant can trigger which DAG. I did not quite like this solution. That is why I like the option proposed by Jarek, I like its simplicity. It would also be easily backward compatible with DAGs not having this new decorator.
+1
Ash Berlin-Taylor
Question about how this will work in practice – and to take one specific example:
Are usernames globally unique or unique per tenant? Does that lead to some information leakage assuming it's globally per install.
If datasets are shared between tenants then I worry what this means for the permissions model (A malicious actor can wreak havok on other dags) or if the dataset is per tenant then I worry what this does to our database schemas! We'd need to add tennant_id to almost every single PK wouldn't we?
This as proposed is a monumental amount of work – is it at all possible to split this up into smaller AIPs?
Overall I'm -1 on this if we continue to call it multiple tenant – that should be reserved for a truly "adversarial MT" system which from skimming (sorry, trying to clear time to read the full thing!) this AIP is not about? Calling it "multi-team Airflow" would be better to my mind.
(One style nit: The very first line says "This document describes the proposal of adding a “--tenant” flag to Airflow components, so that it will be possible to create a multi-tenant deployment of Airflow." which is true, but not how I would open this AIP with!)
Vincent BECK
When Airflow is used in multi-tenant/multi-team mode, an auth manager different from FAB auth manager must be used. FAB auth manager is not compatible with multi-tenancy and never will. Thus, users are no longer managed/saved by Airflow itself but by an external software/service such as KeyCloak, ... So this is no longer an Airflow problem.
Ash Berlin-Taylor
How does that work with the dag_notes/task_notes tables which currently have (had?) a FK to the user table?
Jarek Potiuk
dag_id, connection_id, variable_id, will be prefixed with "tenant_id" and Auth Manager will look at the user, and the rules implemented and decide if this particular entity should be visible to the user or not. There are few extra things (like lising allowed values) - but they are aloready nicely implemented in the Auth Manager API to handle it in optimized way.Jarek Potiuk
> (One style nit: The very first line says "This document describes the proposal of adding a “--tenant” flag to Airflow components, so that it will be possible to create a multi-tenant deployment of Airflow." which is true, but not how I would open this AIP with!)
Yep that's a left over when I started writing it. I will change it definitely, Good point
Jarek Potiuk
> If datasets are shared between tenants then I worry what this means for the permissions model (A malicious actor can wreak havok on other dags) or if the dataset is per tenant then I worry what this does to our database schemas! We'd need to add tennant_id to almost every single PK wouldn't we?
There is a proposal above how to handle dataset access, it might be as simple as to add "tenant_id" to add "allow-truggering-by-tenants": [ "tenant-1", "tenant-2"] . I plan to detail it a bit more as indeed being able to trigger any datasets by any tenant was flagged before as potential issue.
> We'd need to add tennant_id to almost every single PK wouldn't we?
No. This is what prefixing dag_id with tenant_id is going to handle. Every entity we care (except connection and variables) have dag_id as part of their primary key. So the idea - precisely to avoid the monumental work, is to add tenant_id as prefix there and make sure "multi-tenant" deployment always has such prefix - i.e. that all DAGs always belong to some tenant - so they always have the prefix. This will allow to avoid massive redesign of our DB. Similarly in case of connections, prefixing them with tenant_id will allow us to get-by without any modifications of the DB structure and without massively modifying of the webserver.
Jarek Potiuk
> Overall I'm -1 on this if we continue to call it multiple tenant – that should be reserved for a truly "adversarial MT" system which from skimming (sorry, trying to clear time to read the full thing!) this AIP is not about? Calling it "multi-team Airflow" would be better to my mind.
Surely - I can rename it to be multi-team, seems that people are very picky about the tenant name - even if K8S itself uses "multi-team tenants" as well, but If changing the name will change it from "-1" to "+1", I am willing to adapt it. That even calls for a new talk for Airflow Summit "Multi-tenant is now multi-team". Kind of cool talk name.
Ash Berlin-Taylor
The name is part of my problem with it certainly, but there is something else about this proposal that is making me uneasy that I have not yet managed to put in to words. (Not helpful, I know!) I will re-read this a few more times and see if I can articulate my worries.
Shubham Mehta
Ash Berlin-Taylor - Were you able to give time towards this to pen down your disagreements? I am very curious to hear about them.
Regarding the name - I don't want to stretch this argument, but I disagree with you here. I've talked with plenty of users to build this understanding that this meets expectations for a Multi-tenant Airflow deployment that our users have. Moreover, Jarek and others have done a Multi-tenancy talk every year, and this is more or less the idea that they have communicated, although not in this much detail. Changing it now will simply confuse the users. And regarding the statement "that should be reserved for a truly 'adversarial MT' system which from skimming," if we have it, and when we have it, we can always call it enhanced multi-tenancy or multi-tenancy 2.0. Jarek has given a strong example with the Kubernetes community, one of the largest open-source communities, being fine with using this term for multi-team deployment, so we should be okay with it. I don't see any benefit to causing more confusion for our users now.
Ash Berlin-Taylor
[Citation Needed] on "meets expectation for a MT Airflow"
on "meets expectation for a MT Airflow"
The difference between this solution and MT in Kubernetes is that Kube has all number of controls (network policies, requests/limits, taints+tolerations, Pod Security Policies, storage limits etc to name a few) that mitigate or reduce the risk from other tenants. Airflow has none of them.
In my view its like comparing apples to a deck of cards – it's just not a meaningful comparison.
Shubham Mehta
Regarding citations, I wish I could share without potential legal issues. We do have feedback from multiple users like Wealthsimple, which Jarek worked closely with, GoDaddy, a publicly known MWAA customer that I discussed with, and one other user on the mailing list. They have indicated that this proposal aligns with their multi-tenancy needs. On the other hand, I haven't seen any vocal opposition from users so far. Three data points in favor > zero user against. I did try to get more users to chime in on this, but given the complexity and size of the proposal, it hasn't been easy.
I actually think that your comparison to Kube controls like network policies and resource limits is an apples-to-deck-of-cards situation. We should be evaluating the core multi-tenancy principles of isolation, resource allocation, access control, and cost efficiency - which this proposal does provide, albeit tailored to Airflow's use case. Drawing direct feature parities with Kubernetes is missing the point.
All that said, I would love to hear your thoughts on what more this AIP should cover in terms of value addition to Airflow users to be termed a "true" multi-tenancy system. Again, I personally don't care about the final term that we end up using, but trying to understand the difference in our thinking.
Jarek Potiuk
I addressed the concern by updating the name to be "Multi-team" and decscription to match it explaining that while there are different ways of achieving multi-tenancy - this API focuses exclusively of multi-team setup.
Ash Berlin-Taylor
Okay I think I've worked out the crux of my problem.
This seems like a fairly big change billed as MT but to my mind it isn't it, and if we are only talking about a per-team boundary (crucially: the boundary is between groups/teams within one company) then could we instead meet these needs more directly and less ambiguously by adding Variable and Connection RBAC (I.e. think along the lines of team/dag prefix-X has permissions to these Secrets only?)
That is to my mind closer to what I feel the intent of this would be. Yes, that would mean conn names (et al) are a global namespace. I think for some users it would be a benefit – for example access to a central DWH would only need to be managed (and rotated) once, not once per team and then access given to specific teams. It also doesn't lead to overloading of MT meaning multiple things to multiple people.
This could build on all the same things already mentioned in this AIP (multiple executors per team, multiple dag parsers etc) but is a different way of approaching the problem.
This then also maintains the fact that some things are still going to be a global namespace, specifically users. There is one list of users/one IdP configured and users exist in one (or more) teams.
I think this might also be a smaller change overall, as the only namespacing we'd need would be on DAG ids and that could be enforced by policy (as in something like ", and everything else could be managed by RBAC etc. In fact you are in some ways already talking about adding this sort of thing for the allow list on who can trigger a dataset. So lets formalize that and expand it a bit.
The other advantage of approaching it this way is that it adds features that would be useful for people who are happy with the current "shared" infrastructure approach (i.e. happy with multiple teams in one Airflow, using existing DAG level rbac etc) but would like the ability to add Connection restriction without forcing them to (their mind) complicate their deployment story.
Jarek Potiuk
I split it into two phases. I also simplified the original concept by removing DB connections and variables out of the picture. Simply - in multi-team setup. we will disable both reading and UI management of connections and variables - that will simplify the implementation (als GRPC/API component) to only handle dag-related resources nothing else. In this sense adding "<team>:" prefix to the DAG makes a lot more sense. Limiting the number of changes needed to implement all this significantly - especialy Phase 1 that will not even need AIP-44 to complete..
Ash Berlin-Taylor
How much of the benefit/need of this AIP could be achieved by this instead:
I'm also not even sure that it makes sense to share the scheduler? Like why is that a component we decided to share when it's often the bottleneck as it is!
I understand that this fits the need of a few select users, but my concern is that the every user ends paying for the maintenance burden due to the added complexity, as I think this change would affect almost the entire code base, right?
Ash Berlin-Taylor
To quote yourself Jarek:
> It will come with a big implementation cost, but I have a feeling it will be used very rarely
Yes, this comes up in the Airflow survey, but I don't think this is the best means to achieve the need. We don't need seperate processors if each team/dag bundle can have separate python dependencies. (i.e. the Execution environment from AIP-66), coupled with some improvements to the UI to only show my teams dags, and then some RBAC/ACL on connections.
Jarek Potiuk
Not exactly sure where the quote comes from - likely out of the context in some specific subset of the changes or particular state of discussion.
I actually believe (but of course I have no hard data - only talking to a number of people and hearing a number of use cases people explained in their issues) that this is going to be indeed not an often case, but often enough to make people consider using Airflow where they are currently dragged out of Airflow because it has no way to easily handle they several teams and they'v heard and read how difficult it is. The AIP-66 execution enviroment is for now removed BTW, because of mutlitple potential issues including a potential security issue where binary (in whatever way) execution environment introduces huges security risks when it will be "per DAG" managed, so there have to be a "Deployment Manager" to manage all those. This one abstract away from "per dag" management to default "per team" management, which I personally think is way more sustainable and achievable, because in vast majority of cases the team needs to use some shared assumptions (otherwise it's not a team, just bunch of individuals).
Ash Berlin-Taylor
Quote was from Re: AIP-66: DAG Bundles & Parsing
Jarek Potiuk
Yep. it was "per DAG execution environment" not "per team execution environment" - I think "per DAG" execution environment will be an extremely rare bird (especially if users will be able to have separate "per team" environment).
Jedidiah Cunningham
It wasn't "per DAG", it was "per DAG Bundle" a.k.a likely many DAGs - way more analogous to a team than a single DAG.
Ash Berlin-Taylor
It wasn't proposing it as per dag bug per dag bundle .
Jarek Potiuk
And yes - we do need some way of separating processors. If we allow the same dag processor to parse (i.e. effectively execute arbitrary code in DAGS) on the same machine without even containerisation separation (even if we go for some form of "per DAG environment"), that does have a number of security riskk. Staring from shared /tmp files that can be owerwritten to potential memory dump issues from DAGs being parsed etc. etc. As long as DAG parsing for two different processses happen on the same machine, there is only a very limited isolation between them and it is a reason why we introduced standalone DAG file processor to allow to separate it.
Jarek Potiuk
With that said - if we find a way how we can have "bundles" becoming teams, have separate processeors and separate executors (to also separate execution of those tasks belonging to a bundle to a separate "security perimeter"), and auth manager that will be able to manage "bundle dags" separately and connect connection id management "per bundle" - then maybe this is the way to go, essentially merging the two AIPs. I have absolutely no problem in keepin "bundle_id" is an identifier there instead of team_id cc: Jedidiah Cunningham ash - maybe that is the right way to go? I am happy to adjust my AIP to build on yet-another-AIP and have "bundle_id" as an identifier. This would generally describe what I found missing when AIP-66 had execution environment - i.e. describe and explain how those execution environments should be defined. IMHO - if they could be "container images" as well (not only packaged virtualenvs), I nicely see how "Team = Bundle" could work.
Jedidiah Cunningham
I'll have to think and respond more fully later (preparing for a meetup talk in a few hours!), but my initial reaction is no. I can see way more use for "hey, get DAGs from this git repo and that git repo, run them in a single Airflow" which is what AIP-66 DAG bundles today would allow, than "hey, if you want to source DAGs from more than one git repo, go do the multi-team thing - deploy a whole separate Airflow minus scheduler and webserver" . The latter feels like way more work and complexity.
Maybe you didn't mean for it to be 1-to-1 like that?
Ash Berlin-Taylor
I think tying things to team_id makes the most sense, as that's how users would think about it, even if we have a 1:1 between team and bundle for now, having them be separate seems logically more correct.
For instance, roles/permissions in UI should be able apply to team (nee Group), and users belong to teams, not to bundles.
Jarek Potiuk
It's not only UI. It's more than that. It's also API and aggregation of statistics and anything that requires access to "whole" organisational data requires correlation and aggregation from multiple enpoints. And main reason whey single scheduler is used is that it allows to configure and manage common parts in a single place including cross team dataset correlation for example. Surely that all can be don as add-on for multiple instances of Airflow., But it will will require the whole new layer that will be even more complex I think. You will have to start managing access in a way that is shared between teams, the deployment and communication between those instansces (for example for dataset sharing requires the separate instance to talk to each other via pretty much artifficial credentials and it will make the whole on-premise installation way more complex if you ask me. Do you have experience and can tell how easy/complext it will be to build such a layer and tooling?
> I'm also not even sure that it makes sense to share the scheduler? Like why is that a component we decided to share when it's often the bottleneck as it is!
And i think we can make it super clear that it's not a full multi-tenant solution - initially there was a lot of debate about, it and we dialed it in, and we could even make people aware that if they want to do multi-tenant, they can use whatever managed services offer there.
The main reason is that having it all in single DB schema that allows to automatically use what we have when it comes to existing APIs and manged UI. Which also means that any future changes in the APIs and future UI will be covered and will evolve together, rather than having to remember that any new feature have to be also updated in the extra layer on top - which will undoubtedly have less attention from those who will implement new features. We saw precisely this happening when openlineage has been done separately from Airflow, and all the consequences of that (and that's why it's been integrated in). Surely as nicely described here https://www.astronomer.io/blog/airflow-infrastructure/ - when scheduler is a bottleneck, having separate instance and a management layer on top of it is great approach and actually I would not attempt it to make it a "community" feature - it is - indeed better to make it a "managed service" feature as there is a lot more complexity to it and a lot mor effort to connect all that. And I think we should be pretty clear in describing the feature that there are other ways.
Having it as part of the core airflow is all but guarantee that it will not only work fine for Airflow 3.0 but also for Airflow 3.9. And again - it does not exclude the option of having a way how to join several instances when it makes sense - for example when either higher resource requirements or criticality of some workflows is important. As mentioned in the docs - we are not aiming to icrease capacity of the scheduler. The main goal is to serve those users who already run multiple teams in their single airflow instance and go through many hoops and bounds and accept some difficulties it brings (for example only use Docker Operator for all their tasks because their teams have problems with different dependencies).
At the end I think we should ask the community whether they think this is really worth - and initial response to the vote on the devlist for previous versio of it (which achieved more or less the same goal - but with less complexity of the internal DB changes - because I wanted to avoid it in Airflow 2) was overhwelmingly positive (so I read it as - yes a lot of people needs and care about it) with the few voices that we should make it "properly" and make it part of the DB changes. Now it seems that the main argument is that changing DB and the ripple effect (which I wanted to avoid originally but with Airflow 3 seems inevitable anyway) is another reason why it's not a good idea, this does seem like a bit contradicting set of statements, I know in different circumstances. but the goals and "usfullnes" of the whole AIP has not changed since maybe 2 years ago when we started discussing it and had a few talks about it, and many times when I spoke to many users, they said they are doing a lot of "puting their left hand in their right pocket" to achieve precisely this in thier single instance, and they do not want to have multiple of these.
Ash Berlin-Taylor
Do you have any indication/idea of what level of code changes this will require? That is my main concern, that
a: it touches almost all of Airflow core, and
b: the proposed solution feels architecturally very complex to me.
(There are also things I disagree with, like connections being per team. I would say connections are global, but should have access controls to say which teams, or DAGs even, should be able to use them.)
I can see the desire for some of this sort of functionality, I'm not questioning that. I'm just not sure the complexity (in my view, of course) of this solution is worth it, or if a simpler solution would give us an 80% solution for 20% of the cost.
Jarek Potiuk
As described above - maybe then I can piggyback on bundles and presumably some "bundle_id" that will be already implementing those changes. If the other AIPs will define "per bundle" ACL controls, if they will be plugged in in the UI (so basically which bundle each user has access to) and if we keep introduction of separate processor and execution "security" perimeter (not only on the base of venv on the same machine but generally separating on which machines each bundle will be executing, that would be equivalently the same as we have now with team_id. I can easily call it "Multi-bundle secure deployment of Airflow". I have absolutely no problem with that, after so many tenant/team /team with tenant_id/ proposals and changes.
But the "execution environment" in the bundle being physically separated during DAG parsing and UI access to different "bundles" and UI-sepearation of connections is very much necessary for that to work. cc: Jedidiah Cunningham ash → Is that general idea ok? I would not like to redo the document again just to find out that the whole idea makes no sense and is questionable. It takes a lot of my time and mental effort, and seems that every time I address some concerns, there are others that could have been raised earlier, so I would definitely want to avoid doing it for the 4th time or abandon it completely,
Ash Berlin-Taylor
Yeah I'm not trying to create more work for you, sorry that was the result.
Ash Berlin-Taylor
Let me think on this some more and re-read it (again again).
I was trying to be upfront about my concerns so we can address them rather than me just voting against it entirely.
Jarek Potiuk
Basically the main point in the design is:
Basically I want to be able to tell our users - you can manage your environements separately and make sure that the code developed by one team member will not be able to leak to code executed by another team member. Which is not possible if those two are handled by the same process. I see a flood of CVE requests coming if we say "the bundle execution is isolated". Poking a hole if you don't isolate it so that it can run with seperate networking, security peremeter based on containarisation (minimum) or separate machines (better) is simply far too easy when you allow an arbitrary code to run there.
And this is REALLY what this AIP tries to achieve. And this is - again why I hesitated to get it in Airflow 2 knowing about many other changes coming in 3. If we not only base it on AIP-72, but also on AIP-66 - and turn bundle into full security isolation (option) with both execution and UI access, I am happy to do it this way and based all on "bundle_id" which undoubtedly will have to be stored in the DB already and will not result in "more" modifications that the bundle id already will require. For me really "bundle_id" is simply a bit more generic way of "team_id" defintion - and if we add secuity property + id the ACL can be based on bundle and available in the UI on top of it to achieve multi-team, I am all for it.
cc: Jedidiah Cunningham →
Ash Berlin-Taylor
Also it's probably not a 1:1 relationship between team and bundle (or it doesn't have to be) – a team could have many bundles without making things any more complex.
(so it's team 1:* bundle, and not a many-to-many)
Jarek Potiuk
Yes. Butif the ACL will work in the way that you will be able to attach many bundle_ids to connections and UI, users it is easily mappable. And we could start with 1 team = 1 bundle and expand it later.
Jedidiah Cunningham
I never intended for DAG bundles to be isolated from each other, at least to the extent that we could rely on it for security purposes. I was more envisioning them as "DAG sources", more like subfolders in todays DAG folder. I'm also not sure bundles are the right entity to use as the "team" (one team → many bundles), so I think it'd be more straightforward to have a separate entity to act as the team.