Proposers
Approvers
- Shaofeng Li
- Vinoth Chandar
- Gary Li Approved
Status
Current state:
| Current State | |
|---|---|
UNDER DISCUSSION | |
IN PROGRESS | |
ABANDONED | |
COMPLETED | |
INACTIVE |
Discussion thread: here
JIRA: Hudi-841
Released: <Hudi Version>
Abstract
Now we want to use Aliyun DataLake analytics service to analytics hudi dataset. So we need to sync the meta to Aliyun DataLake analytics , but the hudi-hive-sync just support hive. Hudi as open datalake engine, will support more meta service and analytics engine.
So, I am proposing to support for abstract the common hudi-sync. Then other service like aws glue、aliyun datalake analytics can implement.
Background
Currently Hudi only supports sync dataset metadata to Hive through hive jdbc and IMetaStoreClient. When you need to sync to other frameworks, such as aws glue, aliyun DataLake analytics, etc.
You need to copy a lot of code from HoodieHiveClient, which creates a lot of redundant code. So need to redesign the hudi-hive-sync module to support other frameworks and reuse current code as much as possible. Only the interface is provided by Hudi, and the implement is customized by different services as hive 、aws glue、aliyun DataLake analytics.
Implementation
To solve the above problems, we need to refactor the current module organization and code implementation.
2.1 module organization
2.1.1 Option1
- Added hudi-common-sync module, which is used to place common interface implementation
- The hudi-hive-sync module remains unchanged and depends on the hudi-common-sync module
2.1.2 Option2
- Keep the current module unchanged, that is, no new module is added;
The organizational form of Option1 will be clearer, and user dependence will be clearer; but an additional module will be added.
Option2 has no changes to the current module organization, but the general interface implementation is placed in the hudi-hive-sync module. The user-defined implementation depends on this module, which is a bit semantically strange.
I personally prefer Option1.
2.2 Code (class) structure
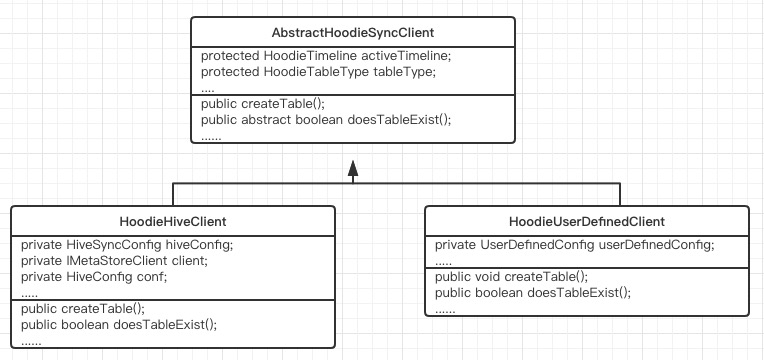
Among them, AbstractHoodieSyncClient is an abstract synchronization client, the default implementation is HoodieHiveClient; users can customize to implement Client.
The abstract methods in AbstractHoodieSyncClient are below
public abstract void createTable(String tableName, MessageType storageSchema,
String inputFormatClass, String outputFormatClass, String serdeClass);
public abstract boolean doesTableExist(String tableName);
public abstract Option<String> getLastCommitTimeSynced(String tableName);
public abstract void updateLastCommitTimeSynced(String tableName);
public abstract void addPartitionsToTable(String tableName, List<String> partitionsToAdd);
public abstract void updatePartitionsToTable(String tableName, List<String> changedPartitions);
If option1 is used, then AbstractHoodieSyncClient will be put into the hudi-common-sync module; if option2 is used, then AbstractHoodieSyncClient will be put into hudi-hive-sync.
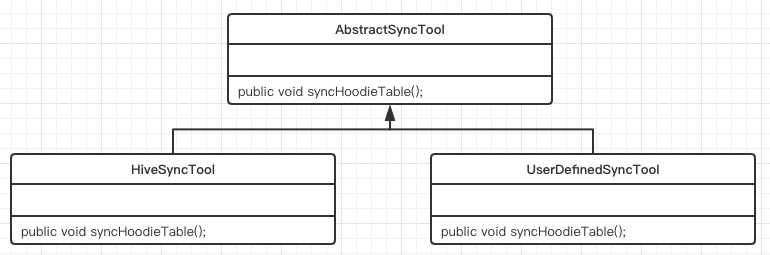
AbstractSyncTool is an abstract synchronization tool. All synchronization tools must inherit this class, and the default implementation is HiveSyncTool.
Rollout/Adoption Plan
- No impact on the existing users because the existing HoodieHiveClient implement not changed
- New meta client can implement
Test Plan
- Unit tests
- Integration tests
- Test on the cluster for a larger dataset.
5 Comments
Vinoth Chandar
Udit Mehrotra Could you review this as well?
Udit Mehrotra
Overall this refactoring with Option 1 does make sense to me. It will help customers who want to bring in there own catalog implementations and sync hudi tables.
liwei
Thanks,we will implement as option 1. Added hudi-common-sync module.
Vinoth Chandar
I know I am a bit late to the game here.. do you all feel very strongly about a new module? (rest looks good to me)...
Shaofeng Li
I am incline to introduce a new module since it is more clear. please let me know what's your concern here? Vinoth Chandar