NOTE: The location of this document may be moved when IoTDB has a new document organization structure.
Status
Current state: Accepted
Discussion thread: https://lists.apache.org/thread.html/r6dd6afe4e8e4ca42e3ddfbc80609597788f90b214e7a81788c3b51b3%40%3Cdev.iotdb.apache.org%3E
JIRA:
IOTDB-560
-
Getting issue details...
STATUS
Released:
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
TsFile is a columnar storage file format in Apache IoTDB. It is designed for time series data and supports efficient compression and query and is easy to be integrated into big data processing frameworks.
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams and becoming more and more popular in IOT scenes. So, it would be great to integrate TsFlie of IoTDB and Flink.
In this proposal I would like to introduce the TsFile Flink Connector, i.e., allows Flink to read, write TsFile.

Public interfaces
Source Interface
TsFileInputFormat
The base interface for sources connector that produces records in Flink is InputFormat. If we want to support reading TsFile by Flink, we need to introduce a TsFileInputFormat as follows:
public class TsFileInputFormat<T> extends FileInputFormat<T> { public TsFileInputFormat(String path, QueryExpression expression, RowRecordParser<T> parser) {...} public TsFileInputFormat(String path, QueryExpression expression, RowRecordParser<T> parser, TSFileConfig config) {...} public TsFileInputFormat(QueryExpression expression, RowRecordParser<T> parser) {...} public TsFileInputFormat(QueryExpression expression, RowRecordParser<T> parser, TSFileConfig config) {...} public QueryExpression getExpression() {...} public RowRecordParser<T> getParser() {...} public TSFileConfig getConfig() {...} public TypeInformation<T> setTypeInformation(TypeInformation<T> typeInfo) {...} /*----------------------------- inherited from FileInputFormat ---------------------------*/ public void setFilePath(String filePath) {...} public void setFilePath(Path filePath) {...} public void setFilePaths(String... filePaths){...} public void setFilePaths(Path... filePaths){...} public Path[] getFilePaths(){...} } |
The description of parameter as follows:
Parameter | Description |
String path | Optional. The file path of the TsFile or the directory containing TsFiles, support both local file system and HDFS. Users could specify the file path in many ways e.g. constructor, setter methods, Flink ExecutionEnvironment API and configurations. |
QueryExpression expression | The query expression used to query the QueryDataSet. Users can create it via TsFile API. |
RowRecordParser<T> parser | Parse the RowRecord to user type T which is used in Flink. |
TSFileConfig config | Optional. The configuration of TsFile API. Flink will write its content to the global TsFile configuration before opening the TsFiles. |
RowRecordParser
RowRecordParser is a newly introduced interface.The raw data read from TsFile is a RowRecord object. Users need to implement this interface to parse the RowRecord to user type T which is used in Flink. The definition as follows:
public interface RowRecordParser<T> extends Serializable { T parse(RowRecord rowRecord, T reuse); } |
Sink Interface
The base interface that writes records to the external system in Flink is OutputFormat. As there are two APIs can be used to write data to TsFile i.e. TSRecord and RowBatch, for best performance and nice structure I propose two kind of OutputFormat:
- TSRecordOutputFormat
- RowBatchOutputFormat
TSRecordOutputFormat
public class TSRecordOutputFormat<T> extends FileOutputFormat<T> { public TsFileOutputFormat(String path, Schema schema, TSRecordConverter<T> converter) {...} public TsFileOutputFormat(String path, Schema schema, TSRecordConverter<T> converter, TSFileConfig config) {...} public TsFileOutputFormat(Schema schema, TSRecordConverter<T> converter) {...} public TsFileOutputFormat(Schema schema, TSRecordConverter<T> converter, TSFileConfig config) {...} public Schema getSchema() {...} public TSRecordConverter<T> getConverter() {...} public TSFileConfig getTsFileConfig() {...} /*----------------------------- inherited from FileOutputFormat ---------------------------*/ public void setOutputFilePath(Path path) {...} public Path getOutputFilePath() {...} } |
The description of parameter as follows:
Parameter | Description |
String path | Optional. The output path of which the TsFiles are written to. It would be treated as local directory, HDFS directory, or local file name (if the parallelism of the sink is 1) according to its scheme. Users could specify the file path in many ways e.g. constructor, setter methods, Flink ExecutionEnvironment API and configurations. |
Schema schema | The output Schema. Users can create it via TsFile API. |
TSRecordConverter<T> converter | TSRecordConverter is a newly introduced interface. Its structure will be shown later. The TsFileWriter API accepts TSRecord objects, see TsFile API. Users could implement the interface and Flink would use it to convert the upstream data to TSRecord type. |
TSFileConfig config | Optional. The configuration of TsFile API. |
TSRecordConverter
public interface TSRecordConverter<T> extends Serializable { void open(Schema schema) throws IOException; void covertAndCollect(T input, Collector<TSRecord> collector) throws IOException; void close() throws IOException; } |
Before starting process data, the "open" method will be called. For each upstream input, the "covertAndCollect" method will be called. If the upper OutputFormat object has reached the end of the life-cycle, the "close" method will be called.
As one input may produce multiple TSRecords, we provide a collector to collect the TSRecords. The structure of the Collector is as follows:
Collector
Users may construct multiple TSRecords from one input, and need to call the collect method for every TSRecords.
public interface Collector<TSRecord> { void collect(TSRecord record); } |
RowBatchOutputFormat
The TSRecordOutput supports write unaligned data to TsFile, but it writes the TSRecords one by one, which could be a performance bottleneck if the amount of data is large. If the upstream data is aligned (all measurements have value for each timestamp and each deviceId), users can use RowBatchOutputFormat to write in batches to increase throughput.
The interface of RowBatchOutputFormat is as follows:
public class RowBatchOutputFormat<T> extends FileOutputFormat<T> { public RowBatchOutputFormat(String path, Schema schema, RowBatchConverter<T> converter) {...} public RowBatchOutputFormat(String path, Schema schema, RowBatchConverter<T> converter, TSFileConfig config) {...} public RowBatchOutputFormat(Schema schema, RowBatchConverter<T> converter) {...} public RowBatchOutputFormat(Schema schema, RowBatchConverter<T> converter, TSFileConfig config) {...} public Schema getSchema() {...} public RowBatchConverter<T> getConverter() {...} public TSFileConfig getTsFileConfig() {...} /*----------------------------- inherited from FileInputFormat ---------------------------*/ public void setOutputFilePath(Path path) {...} public Path getOutputFilePath() {...} } |
The description of parameter as follows:
Parameter | Description |
String path | Optional. The output path of which the TsFiles are written to. It would be treated as local directory, HDFS directory, or local file name (if the parallelism of the sink is 1) according to its scheme. Users could specify the file path in many ways e.g. constructor, setter methods, Flink ExecutionEnvironment API and configurations. |
Schema schema | The output Schema. Users can create it via TsFile API. |
RowBatchConverter<T> converter | RowBatchConverter is a newly introduced interface. Its structure will be shown later. The TsFileWriter API also accepts RowBatch objects, see TsFile API. Users could implement the interface and Flink would use it to convert the upstream data to TSRecord type. |
TSFileConfig config | Optional. The configuration of TsFile API. |
The structure of the RowBatchConverter is as follows:
RowBatchConverter
public interface RowBatchConverter<T> extends Serializable { void open(Schema schema) throws IOException; void covertAndCollect(T input, RowBatchCollector collector) throws IOException; void close() throws IOException; } |
The structure of the Collector is as follows:
RowBatchCollector
Users just need to extract single records from the upstream input and pass to the collect method one by one. The framework will take over the work of batching and flushing.
public interface RowBatchCollector { void collect(String deviceId, long timestamp, Object… data) throws IOException; } |
New Module
We need to add a new module for TsFlie's Flink connector, “flink-tsfile”, the POM fragment is as follows:
<project xmlns="..."> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.apache.iotdb</groupId> <artifactId>iotdb-parent</artifactId> <version>0.10.0-SNAPSHOT</version> <relativePath>../pom.xml</relativePath> </parent> <artifactId>flink-tsfile</artifactId> <packaging>jar</packaging> <name>IoTDB Flink-TsFile</name> </project> |
Sequence Diagram
Read Sequence Diagram

Write Sequence Diagram
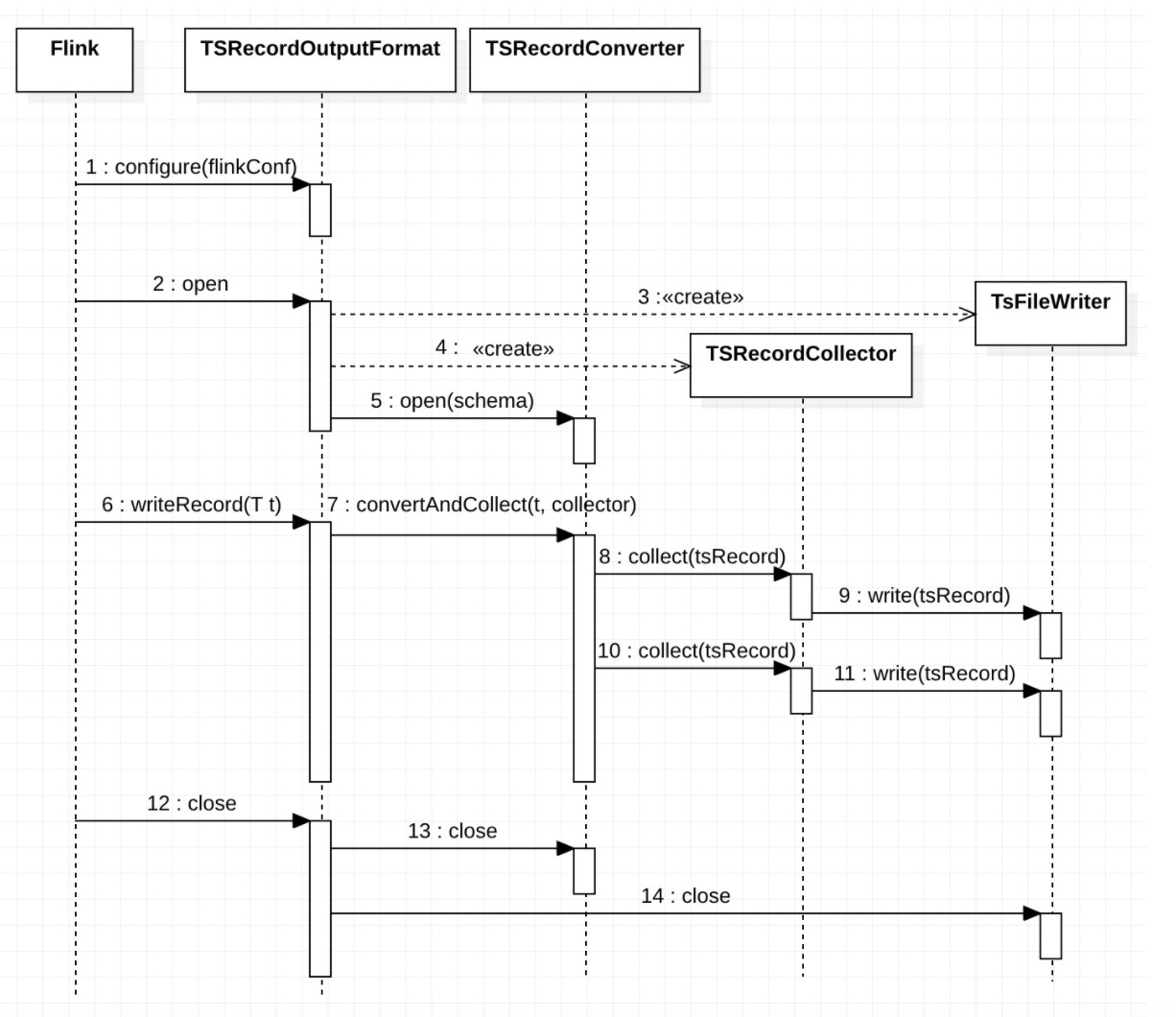
Batch Write Sequence Diagram

Examples
Read example
The example shows how to read the data of the two devices named "device_1" and "device_2" with three measurements named “sensor_1”, “sensor_2” and “sensor_3” from the TsFile.
String[] filedNames = { "time", "device_1.sensor_1", "device_1.sensor_2", "device_1.sensor_3", "device_2.sensor_1", "device_2.sensor_2", "device_2.sensor_3" }; Path[] paths =new Path[] { new Path("device_1.sensor_1"), new Path("device_1.sensor_2"), new Path("device_1.sensor_3"), new Path("device_1.sensor_1"), new Path("device_1.sensor_2"), new Path("device_1.sensor_3"), } TypeInformation[] typeInformations = new TypeInformation[] { Types.LONG, Types.FLOAT, Types.INT, Types.INT, Types.FLOAT, Types.INT, Types.INT }; RowTypeInfo rowTypeInfo = new RowTypeInfo(typeInformations, filedNames); QueryExpression queryExpression = QueryExpression.create(paths, null); TsFileInputFormat inputFormat = new TsFileInputFormat<Row>(sourceTsFilePath, queryExpression, new FlinkRowRecordParser(rowTypeInfo, queryExpression)); DataSet<Row> source = env.createInput(inputFormat, rowTypeInfo); List<String> result = source.map(Row::toString).collect(); |
Prototype of FlinkRowRecordParser,
public class FlinkRowRecordParser implements RowRecordParser<Row> { public FlinkRowRecordParser(RowTypeInfo rowTypeInfo, QueryExpression queryExpression) { this.rowTypeInfo = rowTypeInfo; this.paths = queryExpression.getSelectedSeries(); } @Override public Row parse(RowRecord rowRecord, Row reuse) { List<Field> fields = rowRecord.getFields(); for (int i = 0; i < rowTypeInfo.getArity(); i++) { String fieldName = rowTypeInfo.getFieldNames()[i]; if (QueryConstant.RESERVED_TIME.equals(fieldName)) { reuse.setField(i, rowRecord.getTimestamp()); } else { int pos = paths.indexOf(new Path(fieldName)); Field curField = null; if (pos != -1) { curField = fields.get(pos); } reuse.setField(i, toSqlValue(curField)); } } return reuse; } … ... } |
Write Example
The example shows how to write the upstream data to the TsFile which contains three measurements named “sensor_1”, “sensor_2” and “sensor_3”.
Schema schema = new Schema(); schema.registerMeasurement(new MeasurementSchema("sensor_1", TSDataType.FLOAT, TSEncoding.RLE)); schema.registerMeasurement(new MeasurementSchema("sensor_2", TSDataType.INT32, TSEncoding.TS_2DIFF)); schema.registerMeasurement(new MeasurementSchema("sensor_3", TSDataType.INT32, TSEncoding.TS_2DIFF)); TSRecordOutputFormat<Row> outputFormat = new TSRecordOutputFormat<>("test.tsfile", schema, new FlinkTSRecordConverter(rowTypeInfo)); source.output(outputFormat).setParallelism(1); env.execute(); |
Prototype of FlinkTSRecordConverter:
public class FlinkTSRecordConverter implements TSRecordConverter<Row> { public FlinkTSRecordConverter(RowTypeInfo rowTypeInfo) { this.rowTypeInfo = rowTypeInfo; } @Override public void open(Schema schema) throws IOException { this.schema = schema; tsRecordMap = new HashMap<>(); } @Override public void covertAndCollect(Row input, Collector<TSRecord> collector) throws IOException { …… /* convert logic is omitted */ tsRecordMap.forEach((key, value) -> { collector.collect(value); }); tsRecordMap.clear(); } @Override public void close() throws IOException { this.schema = null; tsRecordMap = null; } … ... } |
Batch Write Example
The example shows how to batch write the upstream data to the TsFile which contains three measurements named “sensor_1”, “sensor_2” and “sensor_3”.
RowTypeInfo rowTypeInfo = new RowTypeInfo(typeInformations, filedNames); Schema schema = new Schema(); schema.registerMeasurement(new MeasurementSchema("sensor_1", TSDataType.FLOAT, TSEncoding.RLE)); schema.registerMeasurement(new MeasurementSchema("sensor_2", TSDataType.INT32, TSEncoding.TS_2DIFF)); schema.registerMeasurement(new MeasurementSchema("sensor_3", TSDataType.INT32, TSEncoding.TS_2DIFF)); RowBatchOutputFormat<Row> outputFormat = new RowBatchOutputFormat<>("test.tsfile", schema, new FlinkRowBatchConverter(rowTypeInfo)); source.output(outputFormat).setParallelism(1); env.execute(); |
Prototype of FlinkRowBatchConverter:
public class FlinkRowBatchConverter implements RowBatchConverter<Row> { public FlinkRowBatchConverter(RowTypeInfo rowTypeInfo) { this.rowTypeInfo = rowTypeInfo; } @Override public void open(List<MeasurementSchema> measurements) throws IOException { this.measurements = measurements; recordMap = new HashMap<>(); } @Override public void convertAndCollect(Row input, RowBatchCollector collector) throws IOException { …… /* convert logic is omitted */ for (Map.Entry<String, Object[]> entry : recordMap.entrySet()) { collector.collect(entry.getKey(), timestamp, entry.getValue()); } recordMap.clear(); } @Override public void close() throws IOException { measurements = null; recordMap = null; } … ... } |
Implementation Plan
- Add Source Connector for TsFile
- Add Sink Connector for TsFlie
- Add Sink Connector with batch mode for TsFlie
4 Comments
Xiangdong Huang
Hi Jincheng,
As we have an IoTDBSink for integration Flink, which is quite different with this work, I think we can introduce the difference between them at the motivation chapter.
How do you think?
Jincheng Sun
Appreciate if you can share your thoughts about how to improve it
Xiangdong Huang
One more thing. I remember I saw the sequence diagrams on the GoogleDoc version. Do you forget to paste them here?
Jincheng Sun
Thanks for the reminder, add the diagrams .
.