...
The virtual data connector (VDC) project is managed by
| Jira | ||||||
|---|---|---|---|---|---|---|
|
It supports two basic use cases:
- An end user wishes to find some interesting data by looking in the Apache Atlas Metadata Catalog.
- When they have found the data source they want, they wish to preview its data values to verify that it really is the data they need.
These use cases seem simple but they raise three very important questions that creates an explosion of requirements in Apache Atlas. The first question is:
What metadata is required to describe the data sources in such a way that the end user can accurately locate the data sources they need - assuming they are not familiar with the content and organization of the data sources?
Typically the end user would want to use meaningful business terms to describe the data they need, they may want so see related descriptions of the data and the profile of its data values and its lineage. Other information about the owners/stewards of the data and the organization they come from, and any license associated with the data would also be relevant. To provide this information, the VDC project needs to expand the types defined in Apache Atlas; expand out the capability of the glossary so it supports categories and other types of semantic relationships to help the end user locate the right data; provide a new catalog API and interface for discovery of data based on these values.
The second question is:
What is the security model that determines which metadata and data that each end user can see?
Specifically, how should access be controlled - particularly in a self-service, data exploration environment where data is sources from many different systems and organizations need to be access in order to discover new uses and interesting patterns in the data. In the VDC project we are providing a single endpoint for accessing data (this is the virtual data connector itself) that uses an Apache Ranger plugin to control access. This control expands on the tag-based security access introduced in Apache Atlas release 0.7 in order to provide security access based on both the confidentiality classification tags (eg PII and SPI tags) and the subject area of the data. There is an additional plug-in that is added to Apache Atlas to control access to metadata based on whether an end-user is allows to discover a data sources metadata.
Finally, the third question is:
Where is the metadata and the data actually stored?
Consider the case where the end user is searching for additional sources for their project and the data that they need has not been provisioned into HDFS - it is still on the source systems. However, these data sources are already catalogued in another metadata repository. To be valuable, Apache Atlas's Catalog search needs to be able to cast its search to reach data and metadata repositories beyond Hadoop in order to locate all available data. Once the end user has identified interesting sources, they may then request that the data is provisioned into HDFS for further analysis. The VDC project will introduce the frameworks, integration and adapter capability to allow a more enterprise view of the potential data sources, plus a metadata driven connector framework for connecting to both data and metadata repositories. These frameworks are part of the open metadata and governance story.
Walk-through of the VDC use case
In the initial MVP for VDC, we are focusing on metadata replication between open metadata repositories to support the catalog query request. Later in 2017, we will add in the federated queries across metadata repositories to broaden the catalog search and potentially reduce the replication of metadata between the repositories.
...
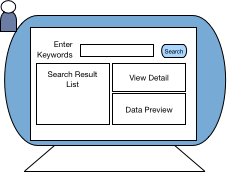
Figure 1: Catalog self service UI
...
Figure 1 shows a mock-up of the catalog search UI that the VDC supports. A person can enter search queries and a list of potential data sources are displayed on the left-hand side of the screen. Selecting one of the search results causes more details of the metadata for that entry to be displayed in the top right-hand side of the screen and underneath it, a preview of the data if the end user has permission to access the data.
...
At the start of the use case, details of the data repositories, the mappings to the business glossary terms and the security classifications are managed in IBM's Information Governance Catalog. This is shown in Figure 2.
The first step is to replicate the metadata from IGC to Apache Atlas so it can be extended to support the virtual views.
This is shown in Figure 3.
...

Figure 2: IBM's Information Governance Catalog (IGC) holding data lake metadata
...

Figure 3: Replicating metadata from IGC to Atlas
...
Since IGC remains the master copy of the original metadata, the replication must be ongoing so that Atlas remains up to date with the latest metadata from IGC.
Thus the replication capability listens for IGC events and converts them into OMRS events that can then be used to drive updates through the OMRS connector API to the Apache Atlas repository.
...
The virtualizer is an optional component of Atlas that receives notifications from Apache Atlas through the Information View OMAS event topic and builds logical tables in Gaian as well and information view metadata in Atlas.
Gaian is an open source information virtualization technology. The virtualizer is written to be modular so calls to a different virtualization technology can be made at this point with a small change to the virtualizer.
The aim at the MVP is to prove out the user of Apache Atlas as a manager for an information virtualization technology.
...

Figure 4: Building information views with the virtualizer
...
...

Figure 5: Configuring enforcement points in Gaian using Apache Ranger
...
...
...
VDC demo shows Apache Atlas operating as an open metadata repository and configuring Apache Ranger and a data virtualization engine for the data lake called Gaian.
The system is now configured. Changes to the IGC metadata will ripple through Atlas, Virtualizer, Ranger and Gaian so they are consistent and up-to-date.
When the end user makes a search request, or clicks on a search result to see more detail, the request and response comes through the Catalog OMAS to Apache Atlas. See Figure 6.
...

Figure 6: Requesting catalog information from Atlas
...

Figure 7: Requesting data from Gaian
...
When the data preview is requested, Gaian is called to extract the data. The Ranger plugins validate the access request allowing Gaian to retrieve the data from the data lake. See Figure 7.
...
Figure 8 summarizes the whole end-to-end flow
...

Figure 8: VDC end-to-end flow (MVP1)
...
...