| Scrollbar |
|---|
| Section | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| Info |
|---|
A paper on rare word indexing is currently in progress. |
Overview of Fast Dictionary Lookup
The fast dictionary lookup annotator performs the same basic function as the original dictionary lookup annotator - it identifies terms in text and normalizes them to codes in an ontology: UMLS CUI, Snomed-CT, RxNorm, etc.
The fast dictionary lookup module comes with multiple possible pre-packaged configurations and is also customizable and extendable.
Implementation of Fast Dictionary Lookup
One of the keys to the lookup speed of the module is its use of a rare word index. This is different from the original module's use of a term index that used the first word in each term. As we are in the process of publishing a paper on the rare word indexing, I will not go into detail on its exact implementation or performance in speed and accuracy comparison tests.
As an overview, the Fast Dictionary Lookup module has six basic processes performed by three components, as well as a parser that can configure the actual Dictionaries.
Process Overview
A. Parse Dictionary Descriptor file
B. Create Dictionaries and Concept Factories
- Get Lookup Windows from CAS
- For each Lookup window, get candidate Lookup Tokens
- For each Lookup Token, get matches in Dictionary Index
- For each Token match, check Lookup Window for Full Text match
- For each Full Text match, create Concepts
- Store appropriate Concepts in CAS as Annotations

Structure
I am not a huge fan of UML, but here you go ... The images here may not be legible, but you can copy and paste in an image viewer to read the text.

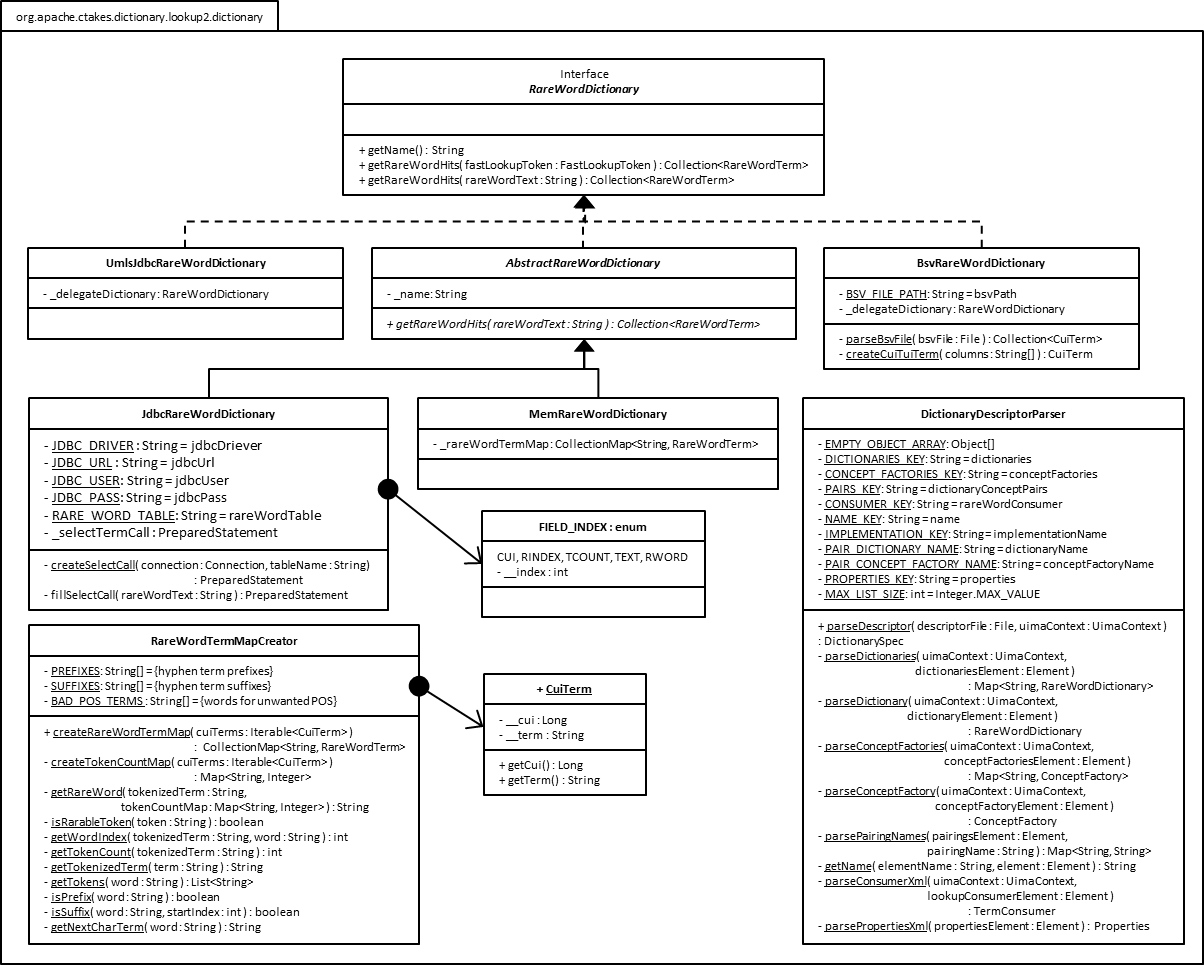





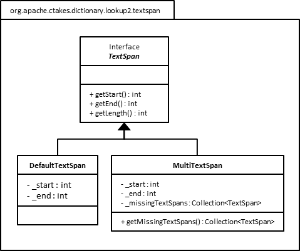
Configuration
There are options available to change the type of term matching used as well as the persistence of terms. Changes in configuration are made in two places:
- The main descriptor ...-fast/desc/analysis_engine/UmlsLookupAnnotator.xml
- The resource (dictionary) configuration file resources/.../fast/cTakesHsql..xml
Text Exact Match
Because the UMLS dictionary contains rows with different combinations of lexical elements per term, using a direct string match of text in note to text of term is a valid candidate for term matching. This is different from the complex mechanism in the current (first word) lookup, and makes for simpler code and greater accuracy. This precise specification (and improved lookup speed) enables the use of an entire sentence as a lookup window rather than just a noun phrase. Usage of Sentence as a lookup window allows all possible tokens to be used for not only lookup keys, but also for term matching. For proper accuracy, custom dictionaries should also contain multiple entries for variations of term syntax. Note that term matching is attempted using the actual text in the note and also per-token cTAKES-generated lexical variants of the text in the note. This is the behavior of the DefaultJCasTermAnnotator class, which is the one used in the UmlsLookupAnnotator.xml descriptor
Text Overlap Match
To better approximate the original lookup annotator, one lookup method finds overlapping terms in addition to exact matching terms. This allows matches on discontiguous spans. For instance, for the text “blood, urine test” the exact match will find only one procedure: “urine test”. The overlap match will find both “urine test” and “blood test”. This is the behavior of the OverlapJCasTermAnnotator class, which is the one used in the UmlsOverlapLookupAnnotator.xml descriptor.
All Terms Persistence
All terms discovered by the matchers can be stored in the CAS by a consumer, regardless of any property of the term. This means that for the text “lung cancer” the specific disease term “lung cancer” and broader term “cancer”. This can be useful for future searches on general concepts, e.g. searching via the CUI for “cancer” and getting all instances of “cancer” found in texts “lung cancer”, “skin cancer”, “stomach cancer”, etc. This is the behavior of the DefaultTermConsumer class.
Most Precise Terms Persistence
Matched terms can be stored only by the longest overlapping span discovered for a semantic group. This keeps, for instance, the disease “lung cancer” but not “cancer”. Using semantic groups means that both the disease “lung cancer” and the anatomical site “lung” are persisted even though the spans overlap. When using the overlap matching method, any discontiguous spans are accounted for. So, for “blood, urine test” both the discontiguous spanned term “blood test” and the contiguous spanned term “urine test” are valid. To persist only the most precise terms, edit the cTakesHsql.xml in the section <rareWordConsumer> and change the selected implementation. By default it is DefaultTermConsumer, but you will want to use the commented-out PrecisionTermConsumer.
Dictionary Stores
The default configuration uses a dictionary that contains a subset of the UMLS in an hsql database. Custom dictionaries can be added using another hsql database, or using a bar-separated value (BSV) (a.k.a. pipe-separated) flat file. If you use a BSV file you do not need to tokenize the terms. Tokenization will be done automatically at runtime.
Lookup Window
By default the new lookup uses Sentence as the lookup window. The primary reasons for this are: 1. Not all terms are within Noun Phrases, 2. Some Noun Phrases overlapped, causing repeated lookups (in my 3.0 candidate trials), and 3. Not all cTakes Noun Phrases are accurate. Because the lookup is fast, using a full Sentence for lookup doesn't seem to hurt much. However, you can always switch it back to see if precision is increased enough to warrant the decrease in recall. This is changed in UmlsLookupAnnotator.xml
| Info | ||
|---|---|---|
| ||
Specific options for the matchers, example BSV schema, role of Concept Factories |