Page History
...
To save cache state to disk we can dump all its pages to disk. First prototypes used this simple approach: stop all updates and save all pages.
WAL
We can’t control moment when node crashes. Also we can’t save all memory pages to disk each time - it is too slow. Updates should be incremental.
Let's suppose we have saved tree leafs, but didn’t save tree root (during pages allocation they may be reordered because allocation is multithread). In this case all updates will be lost.
Technique to solve this named write ahead logging: Before doing actual update, we append planned change information into cyclic file named WAL log (operation name - WAL append/WAL log).
After crash we can read and replay WAL using already saved page set. We can restore to state, which was last committed state of crashed process. Restore bases on pages set + WAL. See also WAL structure section below
Practically we can’t replay WAL from the beginning of times, Volume(HDD)<Volume(full WAL), and we need procedure to throw out oldest part of changes in WAL.
Consistent state comes only from pair of WAL and page store.
This procedure is named checkpointing
Checkpointing
Can be of two types
...
- Percent of dirty pages is trigger for checkpointing (e.g. 75%).
- Timeout is also trigger, do checkpoint every N seconds
WAL
We can’t control moment when node crashes.
Let's suppose we have saved tree leafs, but didn’t save tree root (during pages allocation they may be reordered because allocation is multithread). In this case all updates will be lost.
In the same time we can’t translate each memory page update to disk each time - it is too slow.
Technique to solve this named write ahead logging: Before doing actual update, we append planned change information into cyclic file named WAL log (operation name - WAL append/WAL log).
After crash we can read and replay WAL using already saved page set. We can restore to state, which was last committed state of crashed process. Restore is based on pages store + WAL.
Practically we can’t replay WAL from the beginning of times, Volume(HDD)<Volume(full WAL), and we need procedure to throw out oldest part of changes in WAL, and this is done during checkpointing.
Consistent state comes only from pair of WAL and page store.

Operation is acknowleged after operation was logged, and page(s) update was logged. Checkpoint will be started later by its triggers.
WAL records for recovery
Crash recovery involves following records writtent in WAL, it may be of 2 main types
- Logical record
- Operation description - which operation we want to do. Contains operation type (put, remove) and (Key, Value, Version) - DataRecord
- Transactional record - this record is marker of begin, prepare, commit, and rollback transactions - (TxRecord)
- Checkpoint record - marker of begin checkpointing (CheckpointRecord)
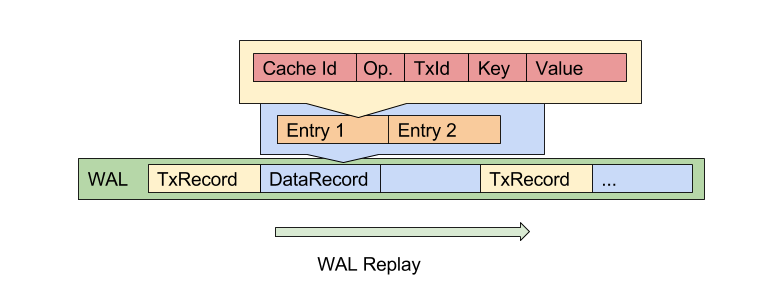
Structure of data record:
- Physical records
- Full page snapshot - record is issued for first page update after successfull checkpointing. Record is logged when page state changes from 'clean' to 'dirty' state (PageSnapshot)
- Delta record - describes memory region change, page change. Subclass of PageDeltaRecord. Contains bytes changed in the page. e.g bytes 5-10 were changed to [...,]. Relatively small records for B+tree records
- Full page snapshot - record is issued for first page update after successfull checkpointing. Record is logged when page state changes from 'clean' to 'dirty' state (PageSnapshot)
Page snapshots and related deltas are combined during WAL replay.
For particular cache entry update we log records in follwowing order:
- logical record with change planned - DataRecord with several DataEntry (ies)
- page record:
- option: page changed by this update was initially clean, full page is loged - PageSnapshot,
- option: page was already modified, delta record is issued - PageDeltaRecord
Possible Planned future optimisation - refer data modified from PageDeltaRecord to logical record. Will allow to not store byte updates twice. There is file WAL pointer, pointer to record from the beginning of time. This refreence may be used.
...
Overview
Content Tools
Apps