Page History
Following notation is used: words written in italics and wihout spacing mean class name without package without package name or method name, for example, GridCacheMapEntry
...
There are following file types used for persisting data: Cache pages or page store, Checkpoint markers, and WAL segments.
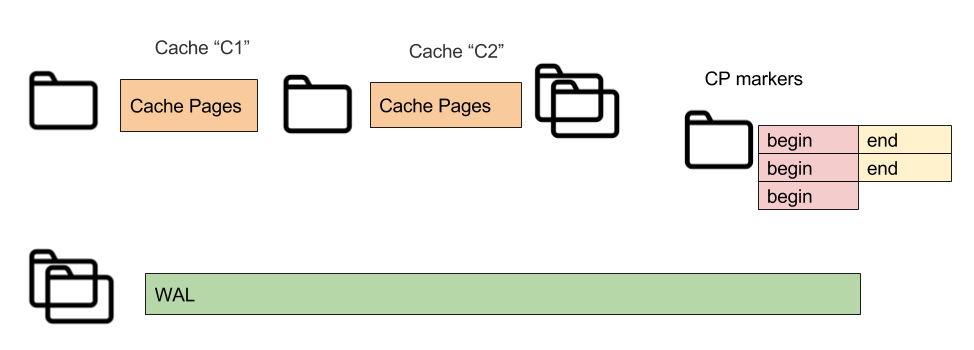
- Write Ahead Log (WAL) segments - constant size files (WAL work directory 0...9.wal; , WAL archive 0.wal…).
- CP markers - small files for events of starting and finishing checkpoints (UUID-Begin.bin, UUID-End.bin).
- Page store - constains cache contains cache parameters, page store for partitions and SQL indexes data (uses file a file per partition: cache-(cache_name)\part1,2,3.bin, and index.bin).
Folders Structure
Ignite with enabled persistence uses following folder stucturefolder structure:
| 2.3+ | Older versions (2.1 & 2.2) | ||
|---|---|---|---|
The Pst-subfolder name is same for all storage folders. A name is selected on start, may be based on node consistentId. |
|


Subfolders Generation
Subfolder The subfolder name is generated on start. By default new style naming is used, for example node00-e819f611-3fb9-4dbe-a3aa-1f6de4af5d02
- where 'node' is a constant prefix,
- '00' -is node index, it is an incrementing counter of local nodes under same PST root folder,
- remainig is remaining is string representation UUID, and this UUID became node's consistent ID.

PST subfolder naming options explained:
Option 1. For case ignite is started for clear persistence storage root folder, this (new style) naming is used.
Option 2. This option is used in case there is existing pst-subfolder with exact the same name with as for compatible consistent ID (loca local host IPs and ports list). If there is such folder, Ignite is started using this one, and consistent ID is not changed.
Option 3. This option is applied in case there is a preconfigured value from IgniteConfiguration.
In case there is an old style folder, but its name doesn't match with compatible consistent ID, following warning is generated.:
| No Format |
|---|
There is other non-empty storage folder under storage base directory [work\db\127_0_0_1_49999, 299718 bytes, modified 10/04/2017 04:33 PM ] |
There are two file locks used in folders selection.
First The first one is used to check if there is no up and running node which is using the same directory.
This lock is placed in work/db/{pst-subfolder}/lock (work/db may be still customized by storage folder property)Second
The second lock is placed in the storage root folder: work/db/lock. This lock is held for a short time when new pst-subfolder is being created. This protects from concurrent folder intialisation by initialization by nodes which are starting simultaneoulysimultaneously.
Exact generation algorithm and code references:
| Expand |
|---|
1) A starting node binds to a port and generates old-style compatible consistent ID (e.g. 127.0.0.1:47500) using DiscoverySpi.consistentId(). This method still returns ip:port-based identifier. 2) The node scans the work directory and checks if there is a folder matching the consistent ID. (e.g. work\db\127_0_0_1_49999). If such a folder exists, we start up with this ID (compatibility mode), and we get file lock to this folder. See PdsConsistentIdProcessor.prepareNewSettings. 3) If there are no matching folders, but the directory is not empty, scan it for old-style consistent IDs. If there are old-style db folders, print out a warning (see warning text above), then switch to new style folder generation (step 4). 4) If there are existing new style folders, pick up the one with the smallest sequence number and try to lock the directory. Repeat until we succeed or until the list of new-style consistent IDs is empty. (e.g. work\db\node00-uuid, node01-uuid, etc). 5) If there are no more available new-style folders, generate a new one with next sequence number and random UUID as consistent ID. (e.g. work\db\node00-uuid, uuid overrides uuid in GridDiscoveryManager). 6) Use this consistent ID for the node startup (using value from GridKernalContext.pdsFolderResolver() and from PdsFolderSettings.consistentId()). There is a system property to disable new-style generation and using old-style consistent ID (IgniteSystemProperties.IGNITE_DATA_STORAGE_FOLDER_BY_CONSISTENT_ID). |
Page store
Ignite Durable Memory is basis the basis for all data structures. There is no cache state saved on heap now.
To save the cache state to disk hard disk we can dump all its cache's pages to diska file. First prototypes used this simple approach: stop all updates and save all pages.
Page store is Let's define page store as the storage for all pages related to particual cache (a particular cache. And more precisely, cache's partitions and SQL indexes).
Using Let's introduce a page identifier. Our requirement it is should be possible to map from a page ID to a file, and to position in a particular file. Page ID can be defined as follows:
| No Format |
|---|
pageId = ... || partition ID || page index (idx) //pageId can be easily converted to file + offset in this file offset = idx * pageSize |
Partitions of each cache have corresponding file a corresponding file in the page store directory (the particular node may own not all partitions).
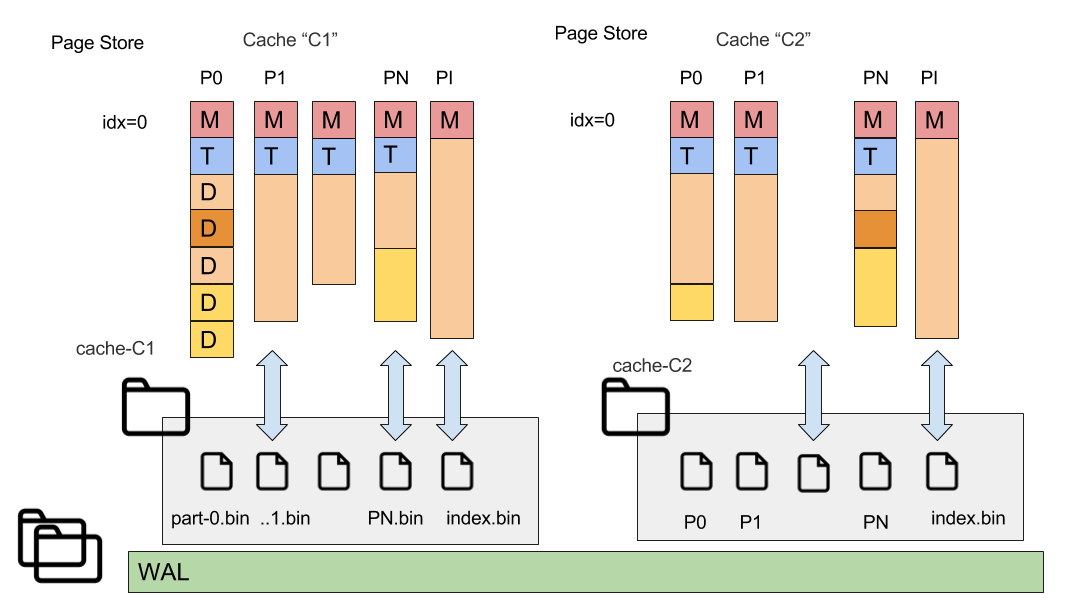
Each cache has a corresponding folder in the page store (named as 'cache-(cache-name)'). And each owning (or backup) partition of this cache has its related file.
Cache page storage contains following contains the following files:
- part-0.bin, part-1.bin, ..., part-1023.bin (shown as P1,P2,PN at picture) - Cache partition pages.
- index.bin - index partition data, special partition with number 65535 is used for SQL indexes and saved to index.bin.
- cache_data.dat - special file with stored cache data (configuration). A StoredCacheData includes more data than than the corresponding CacheConfiguration, e.g. Query entities, query entities are saved in addition.
Persistence
Checkpointing
Checkpointing can be defined as process of storing dirty pages from RAM on a disk, with results of consistent memory state is saved to disk. At the point of process end, page state is saved as it was for the time the process begins.
There are two approaches to implementation of checkpointing:
- Sharp Checkpointing - if checkpoint is completed all data structures on disk are consistent, data is consistent in terms of references and transactions.
- Fuzzy Checkpointing - means state on disk may require recovery itself
Approach implemented in Ignite - Sharp Checkpoint; F.C. - to be done in future releases.
To achieve consistency checkpoint read-write lock is used (see GridCacheDatabaseSharedManager#checkpointLock)
- Cache Updates - holds read lock
- Checkpointer, begin checlpoint - holds write lock for short time. Holding write lock means all state is consistent, updates are not possible. Usage of checkpoint lock allows to do sharp checkpoint
Under checkpoint write lock held we do the following:
- WAL marker is added: checkpoint (begin) record is added - CheckpointRecord - marks consistent state in WAL
- Collect pages were changed since last checkpoint
And then checkpoint write lock is released, updates and transactions can run.
Usage of checkpointLock provides following warranties
- 1 begin checkpoint, and 0 updates (tx'es commit()s) running
- 0 begin checkpoint and N updates (tx commit()s)
Checkpoint begin does not wait transactions to finish. That means transaction may start before checkpoint, but will be committed after checkpoint end or during its run.
Dirty pages is set, when page from non-dirty becomes dirty, it is added to this set.

Collection of pages (GridCacheDatabaseSharedManager.Checkpoint#cpPages) allows us to collect and then write pages which were changed since last checkpoint.
Checkpoint Pool
In parallel with process of writing pages to disk, some thread may want to update data in the page being written (or scheduled to being written).
For such case Checkpoint pool is used for pages being updated in parallel with write. This pool has limitation.
Copy on write technique is used. If there is modification required in page which is under checkpoint, we will create temporary copy of this page in checkpoint pool.

To perform write to a dirty page scheduled to be checkpointed followin is done:
- write lock is acquired to page to protect from inconsistent changes,
- then full copy of page is created in checkpoint pool (CP pool is latest chunk of durable memory segment),
- actual data is written to regular chunk after copy is created,
- and later copy of page from the CP pool will be written to disk.
was not involved into checkpoint initially, and is updated concurrenly with checkpointing process:
- it is updated directly in memory bypassing checkpoint pool.
- actual data will be stored to disk during next checkpoint.
Triggers
- Percent of dirty pages is trigger for checkpointing (e.g. 75%).
- Timeout is also trigger, do checkpoint every N seconds
...
- Local (most DB are able to do this)
- and distributed (whole cluster state is restored).
WAL records for recovery
Crash recovery involves following records writtent in WAL, it may be of 2 main types Logical & Physical
Logical records
- Operation description - which operation we want to do. Contains operation type (create, update, delete) and (Key, Value, Version) - DataRecord
- Transactional record - this record is marker of begin prepare, prepared, and committed, or rollback transactions - (TxRecord)
- Checkpoint record - marker of begin checkpointing (CheckpointRecord)
...
Page snapshots and related deltas are combined during WAL replay.
For particular cache entry update we log records in following order:
- logical record with change planned - DataRecord with several DataEntry (ies)
- page record:
- option: page changed by this update was initially clean, full page is loged - PageSnapshot,
- option: page was already modified, delta record is issued - PageDeltaRecord
Planned future optimisation - refer data modified from PageDeltaRecord to logical record. Will allow to not store byte updates twice. There is file WAL pointer, pointer to record from the beginning of time. This refreence may be used.
WAL structure
WAL file segments and rotation structure

See also WAL history size section below
Local Recovery Process
Let’s assume node start process is running with existent files.
- We need to check if page store is consistent.
- Or we need to find out if crash was while Checkpoint (CP) was running
Ignite manages 2 types of CP markers on disk (standalone files, includes timestamp and WAL pointer):
- CP begin
- CP end
If we observe only CP begin and there is no CP end marker that means CP not finished; we have not consistent page store.
No checkpoint process
For crash at the moment when there was no checkpoint process running restore is trivial, only logical record are applied.

Physical records (page snapshots and delta records) are ignored because page store is consistent.
Middle of checkpoint
Let’s suppose crash occurred at the middle of checkpoint. In that case restore process will discover markers for 1 CP1 and 2 start and CP 1 end.

Restore is split to 2 stages:
1st stage: Starting from previous completed checkpoint record CP1 till record of CP2 start (incompleted) we apply all physical records and ignore logical.
...
2nd stage: Starting from marker of incomplete CP2 we apply only logical records until end of WAL is reached.
When replay is finished CP2 end marker will be added.
If transaction begin record has no corresponding end, tx change is not applied.
Summary, limitations and performance
Limitations
Because CP are consistent we can’t start next CP until previous is not completed.
There is possible next situation:
- updates coming fast from worker threads
- CP pool (for copy on writes) may become full with new changes originated
For that case we will block new updates and wait running for CP to finish.
To avoid such scenario:
- increase frequency of checkpoints (to minimize amount of data to be saved in each CP)
- increase CP buffer size
WAL and page store may be saved to different devices to avoid its mutual influence.
Case if same records are updated many times may generate load to WAL and no significant load to page store.
To provide recovery guarantees each write (log()) to WAL should:
- call write() itself.
- but also require fsync (force buffers to be flushed by OS to the real device).
fsync is expensive operation. There is optimisation for case updates coming faster than disk write, fsyncDelayNanos (1ns-1ms, 1ns by default) delay is used. This delay is used to park threads to accumulate more than one fsync requests.
Future optimisation: standalone thread will be responsible to write data to disk. Worker threads will do all preparation and transfer buffer to write.
See also WAL history size section below.
WAL mode
There several levels of guarantees (WALMode)
Implementation | Warranties | |
|---|---|---|
| FSYNC | fsync() on each commit | Any crashes (OS and process crash) |
| LOG_ONY | write() on commit Synchronisation is responsibility of OS | Kill process, but no OS fail |
| BACKGROUND | do nothing on commit (records are accumulated in memory) write() on timeout | kill -9 may cause loss of several latest updates |
| NONE | WAL is disabled | data is persisted only in case of graceful cluster shutdown (Ignite.cluster().active(false)) |
But there is several nodes containing same data and there is possible to restore data from other nodes.
Distributed Recovery
Partition update counter. This mechanism was already used in continuous queries.
- Partition update counter is associated with partition
- Each update causes increment of partition update counter.
Each update (counter) is replicated to backup. If counter equal on primary and backup means replication is finished.
Partition update counter is saved with update recods in WAL.
Node Join (with data from persitence)
Consider partition on joining node was is owning state, update counter = 50. Existing nodes has update counter = 150
Node join causes partition map exchange, update counter is sent with other partition data. (Joining node will have new ID and from the point of view of dicsovery this node is a new node.)

Coordinator observes older partition state and forces partition to moving state. Moving force is required to setup uploading newer data.
Rebalance of fresh data to joined node now may be run in 2 modes:
- There is WAL on primary node. WAL includes checkpoint marker with partition update cntr = 45.
- We can send only WAL logical update records to backup
- If counter in WAL is too big, e.g. 200, we don’t have delta (can't sent WAL recods)
- joined node will have to clear partition data.
- Partition state is set to renting state
- When clean up finished partition goes to moving state.
- We can’t use delta updates because there is possible problem with keys deleted early. Can get stale key if we send only delta of changes.
Possible future optimisation: for full update we may send page store file over network.
Order of nodes join is not relevant, there is possible situation that oldest node has older partition state, but joining node has higher partition counter. In this case rebalancing will be triggered by coordinator. Rebalancing will be performed from the newly joined node to existing one (note this behaviour may be changed under IEP-4 Baseline topology for caches)
Advanced Configuration
WAL History Size
In corner case we need to store WAL only for 1 checkpoint in past for successful recovery (DataStorageConfiguration#walHistSize)
We can’t delete WAL segments considering only history size in bytes or segments. It is possible to replay WAL only starting from checkpoint marker.
WAL history size is measured in number of checkpoint.
Assuming that checkpoints are triggered mostly by timeout we can estimate possible downtime after which node may be rebalanced using delta logical WAL records.
By default WAL history size is 20 to increase probability that rebalancing can be done using logical deltas from WAL.
Estimating disk space
WAL Work maximum used size: walSegmentSize * walSegments = 640Mb (default)
...
If it's enabled, WAL archive segments that are older than 1 checkpoint in past (they are no longer needed for crash recovery) will be filtered from physical records and compressed to ZIP format. In case of demand (e.g. delta-rebalancing in case of topology change), they will be uncompressed back to RAW format. Experiments show that factor between compacted and RAW segments is 10x on usual data and 3x in worst case (secure random data in updates).
Please note that as long as ZIP segments don't contain any data needed for crash recovery, they can be deleted anytime in case of need for disk space (it will affect rebalancing though).
Setting input-output
I/O abstraction determines how disk features are accessed by native persistence.
Random Access File I/O
This type of I/O implementation opeate with files using standard Java inferface. java.nio.channels.FileChannel is used.
...
To switch to this implementation it is required to set factory in config (DataStorageConfiguration#setFileIOFactory) or change using system property: IgniteSystemProperties.IGNITE_USE_ASYNC_FILE_IO_FACTORY = "false".
This type of IO is always used for WAL files.
Async I/O
This option is default since 2.4.
It was introduced to protect IO module and underlying files from close by interrupt problem.
To set this implementation it is possible to set factory in config (DataStorageConfiguration#setFileIOFactory) or change using system property: IgniteSystemProperties.IGNITE_USE_ASYNC_FILE_IO_FACTORY = "true".
Direct I/O
Introduction and Requirements
...
Direct I/O still can be used for production in case of accurate configuration. But currently the Direct I/O mode is not enabled by default and provided as plugin.
Benefit of using Direct I/O is more predictable time of fdatasync (fsync) operation. As all data is not accumulated in RAM and goes directly to disk, each fsync of page store requires less time, than fsync'ing all data from memory. Direct I/O does not guarantee fsync(), immediately after write, so checkpoint writers still calls fsync at the end of checkpoint.
Overview
Content Tools
Apps