In this page hierarchy, we explain the concepts, design and the overall architectural underpinnings of Apache Hudi. This content is intended to be the technical documentation of the project and will be kept up-to date with
In an effort to keep this page crisp for reading, any concepts that we need to explain are annotated with a def~ and hyperlinked off. You can contribute immensely to our docs, by writing the missing pages for annotated terms. These are marked in brown. Please mention any PMC/Committers on these pages for review. |
Apache Hudi (Hudi for short, here on) allows you to store vast amounts of data, on top existing def~hadoop-compatible-storage, while providing two primitives, that enable def~stream-processing on def~data-lakes, in addition to typical def~batch-processing.
Specifically,

These primitives work closely hand-in-glove and unlock stream/incremental processing capabilities directly on top of def~DFS-abstractions. If you are familiar def~stream-processing, this is very similar to consuming events from a def~kafka-topic and then using a def~state-stores to accumulate intermediate results incrementally.
It has several architectural advantages.
Streaming Reads/Writes : Hudi is designed, from ground-up, for streaming records in and out of large datasets, borrowing principles from database design. To that end, Hudi provides def~index implementations, that can quickly map a record's key to the file location it resides at. Similarly, for streaming data out, Hudi adds and tracks record level metadata via def~hoodie-special-columns, that enables providing a precise incremental stream of all changes that happened.
Self-Managing : Hudi recognizes the different expectation of data freshness (write friendly) vs query performance (read/query friendliness) users may have, and supports three different def~query-types that provide real-time snapshots, incremental streams or purely columnar data that slightly older. At each step, Hudi strives to be self-managing (e.g: autotunes the writer parallelism, maintains file sizes) and self-healing (e.g: auto rollbacks failed commits), even if it comes at cost of slightly additional runtime cost (e.g: caching input data in memory to profile the workload). The core premise here, is that, often times operational costs of these large data pipelines without such operational levers/self-managing features built-in, dwarf the extra memory/runtime costs associated.
Everything is a log : Hudi also has an append-only, cloud data storage friendly design, that lets Hudi manage data on across all the major cloud providers seamlessly, implementing principles from def~log-structured-storage systems.
key-value data model : On the writer side, Hudi table is modeled as a key-value dataset, where each def~record has a unique def~record-key. Additionally, a record key may also include the def~partitionpath under which the record is partitioned and stored. This often helps in cutting down the search space during index lookups.
With an understanding of key technical motivations for the projects, let's now dive deeper into design of the system itself. At a high level, components for writing Hudi tables are embedded into an Apache Spark job using one of the supported ways and it produces a set of files on def~backing-dfs-storage, that represents a Hudi def~table. Query engines like Apache Spark, Presto, Apache Hive can then query the table, with certain guarantees (that will discuss below).
There are three main components to a def~table

Hudi provides the following capabilities for writers, queries and on the underlying data, which makes it a great building block for large def~data-lakes.
Hudi organizes a table into a folder structure under a def~table-basepath on DFS. If the table is partitioned by some columns, then there are additional def~table-partitions under the base path, which are folders containing data files for that partition, very similar to Hive tables. Each partition is uniquely identified by its def~partitionpath, which is relative to the basepath. Within each partition, files are organized into def~file-groups, uniquely identified by a def~file-id. Each file group contains several def~file-slices, where each slice contains a def~base-file (e.g: parquet) produced at a certain commit/compaction def~instant-time, along with set of def~log-files that contain inserts/updates to the base file since the base file was last written. Hudi adopts a MVCC design, where compaction action merges logs and base files to produce new file slices and cleaning action gets rid of unused/older file slices to reclaim space on DFS.
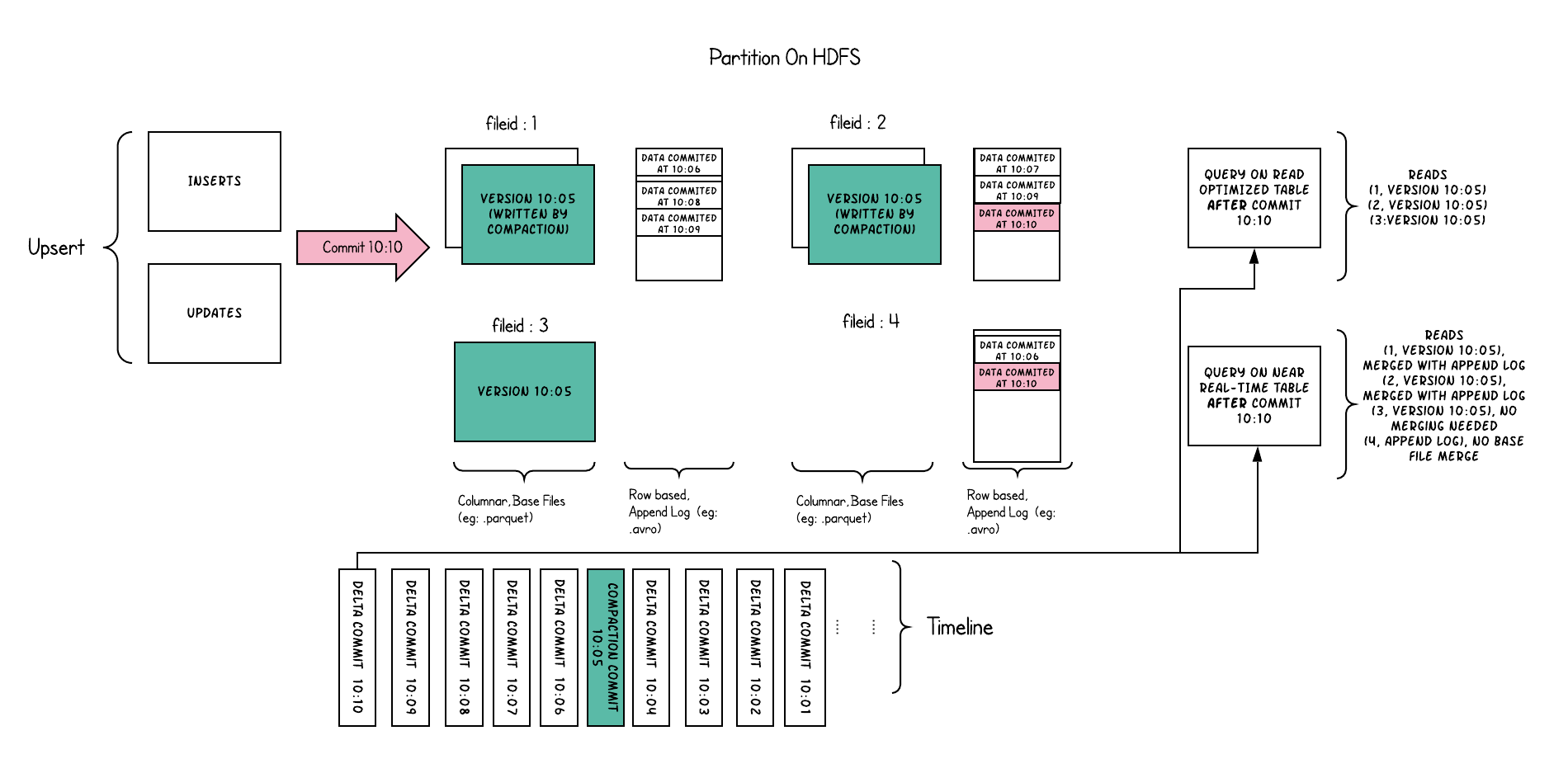 Fig : Shows four file groups 1,2,3,4 with base and log files, with few file slices each
Fig : Shows four file groups 1,2,3,4 with base and log files, with few file slices each
The implementation specifics of the two def~table-types are detailed below.


Hudi also performs several key storage management functions on the data stored in a def~table. A key aspect of storing data on DFS is managing file sizes and counts and reclaiming storage space. For e.g HDFS is infamous for its handling of small files, which exerts memory/RPC pressure on the Name Node and can potentially destabilize the entire cluster. In general, query engines provide much better performance on adequately sized columnar files, since they can effectively amortize cost of obtaining column statistics etc. Even on some cloud data stores, there is often cost to listing directories with large number of small files.
Here are some ways, Hudi writing efficiently manages the storage of data.