BytePS is a high-performance, cross-framework architecture for distributed training. In various hardware settings, it has shown performance advantages compared with Horovod+NCCL. In addition, it supports asynchronous training that Horovod (and all other all-reduce based distributed framework) cannot support. It works for MXNet, TensorFlow and PyTorch, and can run on TCP and RDMA network. The code repository is at https://github.com/bytedance/byteps.
BytePS implementation is a close relative to MXNet. It largely reuses ps-lite and MXNet kvstore_dist_server implementation for network communication and summing up gradients. However, it also adds its own optimization, which is not backward compatible with upstream MXNet’s ps-lite and kvstore implementation.
Consequently, to use MXNet+BytePS, although users are free to choose any MXNet versions as MXNet workers, they have to use a dedicated MXNet version (provided by BytePS team) as BytePS servers. This often causes confusion because sometimes users have to install two versions of MXNet to use MXNet+BytePS.
Hence, the BytePS team proposes to integrate the changes BytePS made to ps-lite and kvstore_dist_server into upstream MXNet. Ideally, upstream MXNet can work as BytePS servers directly.
BytePS now relies on ps-lite as its third party communication library.
Below are the benefits of this proposed integration.
For example, right now the possible setups are like this:
After the integration, the setups will be:
All BytePS users will be converted into (partly) MXNet users.
Below are the benefits of using BytePS. Proposed integration will make these benefits more accessible.
For now, we have a dedicated MXNet (for BytePS servers only) and ps-lite (for the networking functionalities of workers/servers/scheduler) for BytePS. They basically reuse the interfaces of the original code. Specifically, we reuse the MXNet KVstore interfaces to implement gradient summation on BytePS servers, and reuse the ps-lite interfaces to implement RDMA and optimized-TCP (based on ZeroMQ). However, the original functionalities of MXNet-KVstore and ps-lite are broken.
Therefore, we plan to make the following code changes to adapt to existing MXNet and ps-lite repositories:
There is no additional 3rd party dependency required.
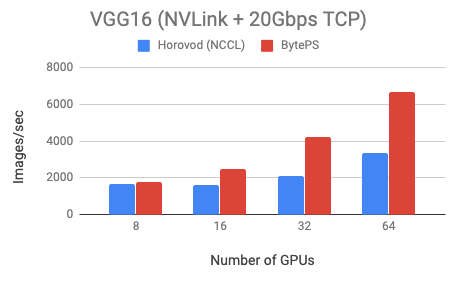
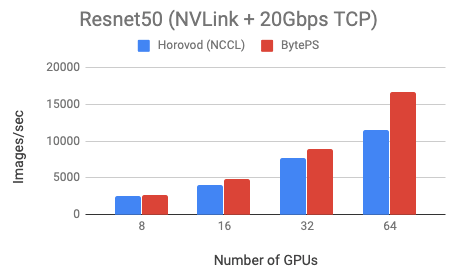
To demo MXNet+BytePS performance, we test two models: VGG16 (communication-intensive) and Resnet50 (computation-intensive). Both models are trained using fp32.
We use Tesla V100 16GB GPUs and set batch size equal to 64 per GPU. The machines are in fact VMs on a popular public cloud. Each machine has 8 V100 GPUs with NVLink-enabled. Machines are inter-connected with 20 Gbps TCP/IP network.
BytePS outperforms Horovod (NCCL) by 44% for Resnet50, and 100% for VGG16.
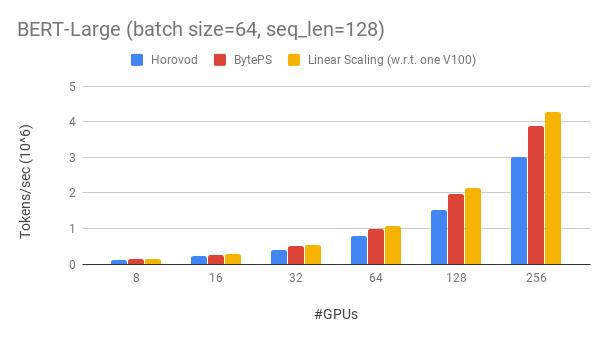
We also test the BERT-large model using fp16 on with RDMA network. The model is implemented using the gluon-nlp toolkit.
We use Tesla V100 32GB GPUs and set batch size equal to 64 per GPU. Each machine has 8 V100 GPUs with NVLink-enabled. Machines are inter-connected with 100 Gbps RoCEv2 network.
BytePS achieves ~90% scaling efficiency for BERT-large with 256 GPUs. As a comparison, Horovod+NCCL has only ~70% scaling efficiency even after expert parameter tunning.
BytePS currently has the following limitations:
BytePS can help you train DNN models in distributed manner (i.e., with at least 2 GPUs) with higher performance than any other existing architectures (native PS or Horovod). If you find your distributed training does not give you satisfying performance, then BytePS is your best choice. That said, there are some cases where you may not see evident improvement with BytePS:
This page explains why BytePS outperforms Horovod (and other existing Allreduce or PS based frameworks) in details: https://github.com/bytedance/byteps/blob/master/docs/rationale.md
For the above, "we" stand for the BytePS team. The primary developers of BytePS team now are Yibo Zhu, Yimin Jiang and Chang Lan. They can be reached via the following email address. We also thank other developers as well.