Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
As discussed in FLIP-131, Flink will make DataStream the unified API for processing bounded and unbounded data in both streaming and blocking modes. However, one long-standing problem for the streaming mode is that currently Flink does not support checkpoints after some tasks finished, which causes some problems for bounded or mixed jobs:
Therefore, we need to also support checkpoints even after some tasks are finished. Based on such an ability, the operators writing data to the external systems in 2pc style would be able to wait for one more checkpoint after tasks emitted all the records to commit the last piece of data. This is similar to the job terminated with stop-with-savepoint --drain, thus we would also like to unify the two processes so that the last piece of data could be committed in all the required cases. To achieve this target efficiently we would also like to adjust the operator API and the life cycle of the StreamTask.
There are multiple options to achieve this target. In this section we compare different options.
The first option is to prevent the tasks from finishing until the whole job is finished. Specially, tasks would never finish if the job also has unbounded sources. This option is not preferred due to that
Another option is allowing tasks to finish normally and checkpoints after tasks finished would only take snapshots for the running tasks. A core issue of this option is whether we need to include the final states collected when a tasks finish in the following checkpoints. Currently when failover happens after some tasks are finished, the job will fallback to a checkpoint taken when all the tasks are running. Including the final states of the finished tasks ensures the behavior unchanged compared with the current one since the finished tasks could be viewed as still running. However it also introduce some problems:
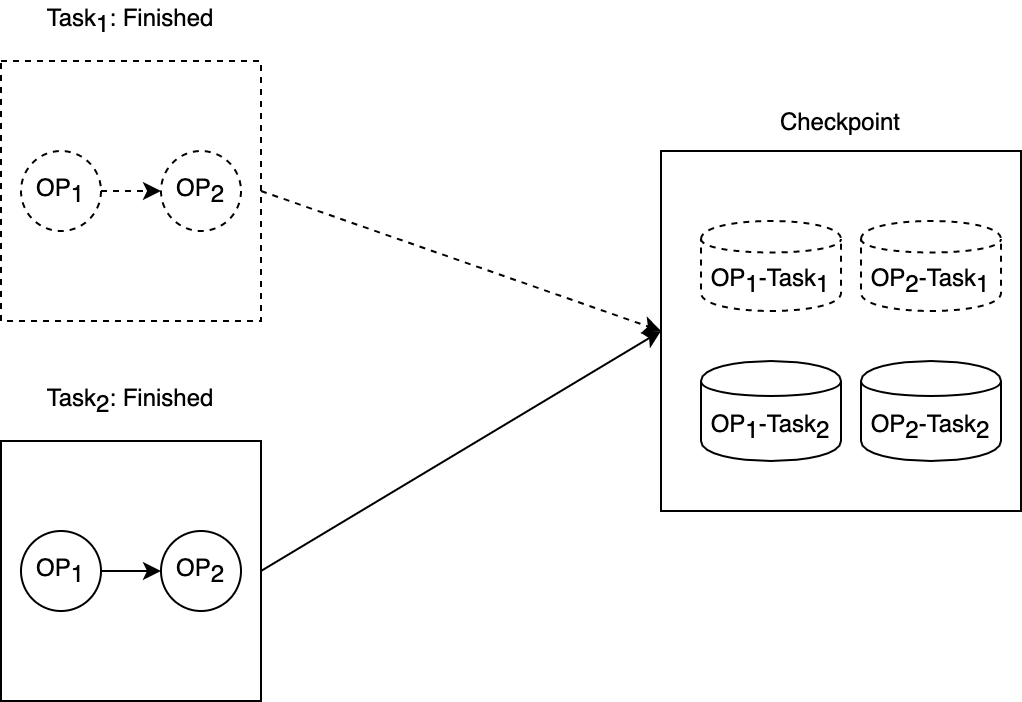
Figure 1. An illustration of the structure of the Checkpoint. One issue is that whether we need to keep the operator states collected from the finished tasks.
If we do not want to include the states from the finished tasks instead, we need to explore how it changes the current behavior. Although in a checkpoint the state is snapshotted in the unit of task, it is finally reorganized by the unit of operator since there might be topology changes or rescaling. In other words, we need to view the checkpoint as composed of the current working progress of each operator, and tasks are only stateless runtime units to execute the remaining work for the operators. If we do not include the state from the finished tasks, it is equivalent to some operator discarding a part of finished work’s state in the checkpoint. Let ΔR represents the state of running task and ΔF represents the final states of finished tasks when taking checkpoints, then the result (e.g., the records sent to the descendant operator) of the operator’s execution after failover is
g(I, ΔR+ ΔF)=g(IR, ΔR)+g(IF, ΔF)
where I is the input after failover, g represents the logic of this operator and the decomposition is due to the fact that the work could be distributed to the different subtasks. Ideally the result should be the same with the execution without the states from the finished tasks, namely g(I, ΔR+ ΔF)=g(I, ΔR), which is equivalent to
g(IF, ΔF)=Ø
Namely there should be no records sent due to ΔF no matter whether we keep it or not.
Source Operators
The source operator does not have input and the equation is further equivalent to g(ΔF)=Ø. The logic of the source operators could be modeled as reading each split from the external system and emitting the records to the pipeline. With legacy source API the source operators usually discover all the splits on startup and record the progress of each split in a union list state. Unfortunately with this pattern if we discard the state for the finished splits, we would re-read them after failover, which violates the condition if we do not keep ΔF. The new source API would overcome this issue since now the splits are discovered and recorded in the OperatorCoordinator, whose state is still kept after all the tasks are finished.
In consideration that we would finally migrate to the new source API, we could temporarily avoid the repeat records issue of the legacy source issue by
As a whole, the source operators could achieve the condition, and the temporary hack could be removed after we migrated to the new Source API.
Non-source Operators
The logic of a non-source operator could be split into processing the input records and the logic in initialize and endOfInput, namely the condition is equivalent to
g(IF, ΔF)=gp(IF, ΔF)+gc(ΔF)=Ø
For the first part, if in a checkpoint some subtask of a non-source operator is finished, then
Thus, we should always have IF=Ø and thus gp(IF, ΔF)=Ø no matter whether we save ΔF.
The situation of the second part is equivalent to the source operators. However, the non-source operators rarely have the similar logic as legacy source. Instead, the result related to ΔF is usually sent before finished and does not need to resent after failover. For example, the operators doing aggregation and sending the final result on endOfInput only need sending the remaining aggregation value after failover. Even if there are operators that does not satisfy the condition, the operators could push the states could not be discarded to OperatorCoordinator instead, like the new Source API does.
There are a few scenarios in which operator states are used in combination with an additional implicit contract on data distribution. Those implicit contracts might not hold in case we restore state with partially finished operators. Therefore we would like to discuss how we want to use the operator state in combination with finished tasks.
In case of broadcast state all operators snapshot their state. The assumption is that every such state is equal and can be used when restoring for any given subtask. We want to leverage that property and when restoring with some subtasks finished, we would use any of the non-empty state (taken for any running subtask).
The UnioinListState is more complex. A common usage pattern is to implement a "broadcast" state by storing state on a single subtask. Afterwards, when initializing subtasks the single copy of the state would be distributed to all subtasks. Another common pattern is to use a UnionListState to create a global view. It is used for example to share information about offsets of partitions which has been consumed so far. This lets us restart from the given offset if after restore a partition is assigned to a different subtask than originally. Such a logic can only be implemented with a merged state of all original subtasks If a part of subtasks are finished and we only keep the remaining state in the checkpoint. This can obviously loose important bit of information, or even the entire state in case of described implementation of broadcast state. However, since the UnionListState is on the way to be deprecated and replaced by the OperatorCoordinator.
For the time being, we will allow for a situation that if an operator checkpoints UnionListState, it can only finish all at once. We will decline checkpoints if not all of the tasks called finished and received notifyCheckpointComplete .
We want to make the contract of ListState more explicit that the redistribution may happen even in case there is no rescaling. This might have some sophisticated implications. Imagine a situation where you have a topology:
src 0 --> op 0 --> sink 0
src 1 --> op 1 --> sink 1
src 2 --> op 2 --> sink 2
We buffer records in operators op X. If src 1 finishes its state will be cleared. Than if after a restore the state of src 2 is assigned to src 1. Records from partitions originally assigned to src 2 will end up in both op1 and op2. Depending on the processing speed of the two operators, if the op 1 unbuffers records faster it may happen that later records from such partition will overtake earlier records in the pipeline. However, Flink never offered explicit guarantees that in case of recovery, non-keyed ListState will be assigned in the same order to subtasks before and after recovery, especially across multiple operators. As part of this FLIP, we want to document and clarify this.
Based on the above discussion discarding the final states of the finish tasks would only change behavior for a very little fraction of the possible existing jobs whose non-source operators have special logic on initialization or endOfInput, and these jobs could also be modified to keep the current behaviors. Therefore, we lean towards option 3, which simplify the implementation and leave more room for optimization in the future.
This section details the proposed changes for the options 3 chosen in the last section.
We want to introduce a feature flag to enable or disable the new feature:
@Documentation.ExcludeFromDocumentation("This is a feature toggle")
public static final ConfigOption<Boolean> ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH =
ConfigOptions.key("execution.checkpointing.checkpoints-after-tasks-finish.enabled")
.booleanType()
.defaultValue(false)
.withDescription(
"Feature toggle for enabling checkpointing after tasks finish."); |
For checkpoints involving finished tasks:
Currently CheckpointCoordinator only triggers the sources for new checkpoints and other tasks would receive barriers from the input channels. However, it would not work to only trigger the running sources after tasks finished. As exemplified in Figure 1, suppose Task A has finished if we only trigger B for a new checkpoint, then Task C would have no idea about the new checkpoint and would not report its snapshot.

Figure 2. An example execution graph with one task finished.
It might be argued that we could wait till the Task C to finish during this checkpoint, then we could not trigger task C in the checkpoints. However, this does not work if C is a two-phase commit sink and requires one successful checkpoint before finish, which will cause deadlock.
To find the new "root" of the current execution graph, we iterates all the tasks to find the tasks who are still running but have no running precedent tasks. A direct implementation would have O(n2) time complexity since it needs to check all the precedent tasks of each task. However, we could reduce the complexity to O(n) by exploiting the isomorphism of ALL_TO_ALL edges. The detail is described in Appendix 1.
To avoid the case that the tasks finished during the computation, the computation is done in the JobMaster's main thread. However, there might still be inconsistency due to:
In both cases, the checkpoint trigger would fail and the whole checkpoint would then fail due to timeout. Since checkpoint timeout would block the next checkpoint and cause failover by default, it would be better to detect the trigger failure as earlier as possible. The failure could be detected if a task finished before acknowledging the snapshot for this checkpoint. CheckpointCoordinator would listen to the event of task finish, when a task finish, it iterates all the pending checkpoints to do the detection.
For the task side, there are two cases regarding checkpoints with finished tasks:
All the Precedent Tasks are Finished
Currently tasks could be classified into two types according to how checkpoint is notified: the source tasks are triggered via the RPC from the JobManager, while the non-source tasks are triggered via barriers received from the precedent tasks. If checkpoints after some tasks are finished are considered, the non-source tasks might also get triggered via RPC if they become the new "root" tasks. The implementation for non-source tasks would be different from the source tasks: it would notify the CheckpointBarrierHandler instead of directly performing the snapshot so that the CheckpointBarrierHandler could deal with checkpoint subsuming correctly. Since currently triggerCheckpoint is implemented in the base StreamTask class uniformly and only be called for source StreamTask classes, we would refactor the class hierarchy to support different implementations of triggerCheckpoint method for the two types of tasks.
Some of the Precedent Tasks are Finished
If for one task not all its precedent tasks are finished, the task would still get notified via checkpoint barrier from the running precedent tasks. However, some of the preceding tasks might be already finished and the CheckpointBarrierHandler must consider this case. As a whole, EndOfPartition from one input channel would mark this channel as aligned for all the pending and following checkpoints. Therefore, when receiving EndOfPartition, we will insert a manually created CheckpointBarrier for all the pending checkpoints, and exclude the channel from the following checkpoints.
This is enough for aligned checkpoints, but unaligned checkpoints would introduce additional complexity. Since unaligned checkpoint barriers could jump over the pending records, if we instead wait for the EndOfPartition directly, since EndOfPartition could not jump over, the CheckpointCoordinator could not get notified in time and we might incur longer checkpoint periods during the finishing phase. This is similar for the aligned checkpoints with timeout. To cope with this issue, the upstream tasks would wait till the downstream tasks to process all the pending records before exit. The upstream tasks would emit a special event, namely EndOfData, after all the records and the downstream tasks would respond with another special event, and the upstream tasks only exit after all the response events are received. During this period, the unaligned checkpoints or checkpoints with timeout could be done normally. Afterwards the EndOfPartition could reach the downstream CheckpointAligner quickly since there are no pending records.
Currently when a task finish, all the pending checkpoints would be canceled. Since now we would support checkpoints after tasks finished, tasks finish should not fail the checkpoints and we would change the behavior to waiting for all the pending checkpoints to finish before task get finished.
Logically we could not restart the finished tasks on failover. We could only restart those tasks who have operators not fully finished. However, for the first version, we would still restart all the tasks and skip the execution of fully finished operators. This simplifies the implementation of the task side and scheduler.
Based on the ability to do checkpoint or savepoint after tasks finished, operators interacting with external systems in 2PC style could commit the last piece of data by waiting for one more checkpoint or savepoint. In general, for jobs to finish there are three cases:
For the first two cases, the job would not be expected to be restarted, thus we should flush all the records and commit all the records. But for the third case, the job is expected to be re-started from the savepoint, thus in this case we should not flush all the records. For example, for window operators using event-time triggers, it would be reasonable to trigger all the remaining timers if it is going to finish, but for the third case, the job would be restarted and process more records, triggering all the timers would cause wrong result after restarting.
To flush all the records on finished, we need to
However, currently we lack a clear method in the API to stop processing records and flush buffered records. We lack a clear method in the API to stop processing records and flush any buffered records. We do have the StreamOperator#close method which is supposed to flush all records, but at the same time, currently, it closes all resources, including connections to external systems. We need separate methods for flushing and closing resources because we might need the connections when performing the final checkpoint, once all records are flushed. Moreover, the logic for closing resources is duplicated in the StreamOperator#dispose method. Lastly, the semantic of RichFunction#close is different from StreamOperator#close . Having no direct access to any output the RichFunction#close is responsible purely for releasing resources. We suggest using this opportunity to clean up the semi-public StreamOperator API and:
dispose method close methodfinish methodEffectively it would modify the Operator lifecycle (https://ci.apache.org/projects/flink/flink-docs-master/docs/internals/task_lifecycle/#operator-lifecycle-in-a-nutshell) termination phase to be:
// termination phase
OPERATOR::endOfInput(1)
...
OPERATOR::endOfInput(n)
OPERATOR::finish
UDF(if available)::finish
OPERATOR::snapshotState()
OPERATOR::notifyCheckpointComplete()
OPERATOR::close() --> call UDF's close method
UDF::close() |
In case of failure, we will call the Operator#close → UDF#close method.
public interface StreamOperator<OUT> extends CheckpointListener, KeyContext, Serializable {
....
/**
* This method is called at the end of data processing.
*
* <p>The method is expected to flush all remaining buffered data. Exceptions during this
* flushing of buffered should be propagated, in order to cause the operation to be recognized
* as failed, because the last data items are not processed properly.
*
* <p><b>After this method is called, no more records can be produced for the downstream operators.</b>
*
* <p><b>NOTE:</b>This method does not need to close any resources. You should release external
* resources in the {@link #close()} method.
*
* @throws java.lang.Exception An exception in this method causes the operator to fail.
*/
void finish() throws Exception;
/**
* This method is called at the very end of the operator's life, both in the case of a
* successful completion of the operation, and in the case of a failure and canceling.
*
* <p>This method is expected to make a thorough effort to release all resources that the
* operator has acquired.
*
* <p><b>NOTE:</b>It should not emit any records! If you need to emit records at the end of
* processing, do so in the {@link #finish()} method.
*/
void close() throws Exception;
...
} |
The UDF that most often buffers data and thus requires a flushing/finishing phase is the SinkFunction where it could e.g. create transactions in an external system that can be committed during the final snapshot. Therefore we suggest introducing a finish method in the SinkFunction :
@Public
public interface SinkFunction<IN> extends Function, Serializable {
default void finish() throws Exception {}
} |
Currently there would be some duplication between endOfInput() and finish() for one input operators, for the long run we would like to unify them to finish() method and keep only endOfInput(int channelIndex) and finish().
The finish() method is tied to the lifecycle of an Operator and it is NOT tied to the lifecycle of State. It is possible that after recovery a state created after calling finish() might be restored to an operator that will receive more records. The operator implementation must be prepared for that. In particular it is generally not safe to write a finished flag into the state and check that you do not receive records if the flag is set. |
If we directly map the original close() to the new finish() method, based on the current StreamTask's implementation, it would call the finish() method after received EndOfPartitionEvent and emit EndOfPartitionEvent after the last checkpoint / savepoint is completed. This would cause the tasks to wait for the last checkpoint / savepoint one-by-one, which is inefficient.
Besides, currently stop-with-savepoint [--drain] uses a different process: it first triggers a savepoint and blocks the tasks till the savepoint is completed, then it finishes the tasks. There would cause duplication if we want to also flush the records for stop-with-savepoint --drain. Besides, currently there might still be records between the savepoint and finishTask, this would cause confusion, especially if these records affect external systems.
To deal with the above issues, we would like to adjust the lifecycle of the StreamTasks to avoid chained waiting and diverged processes:
The detail life cycle for the source stream tasks and the operators would become
| Event | Stream Task Status | Operator Status | Final Checkpoint | Stop with Savepoint with Drain | Stop with Savepoint |
|---|---|---|---|---|---|
| RUNNING | RUNNING | - | - | - | |
No more records or Received Savepoint Trigger | - | - | - | ||
| - | finish task (cancel source thread for legacy source and suspend the mailbox for the new source) | finish task (cancel source thread for legacy source and suspend the mailbox for the new source) | |||
| Advanced To MAX_WATERMARK and trigger all the event timers | Advanced To MAX_WATERMARK and trigger all the event timers | - | |||
| Emit MAX_WATERMARK | Emit MAX_WATERMARK | - | |||
| WAITING_FOR_FINAL_CP | FINISHED | call operator.endInput() & operator.finish() | call operator.endInput() & operator.finish() | - | |
| Emit EndOfData[finished = true] | Emit EndOfData[finished = true] | Emit EndOfData[finished = false] | |||
| when checkpoint triggered, emit Checkpoint Barrier | Emit Checkpoint Barrier | Emit Checkpoint Barrier | |||
| Wait for Checkpoint / Savepoint Completed | Wait for Checkpoint / Savepoint Completed | Wait for Checkpoint / Savepoint Completed | |||
| Wait for downstream tasks acknowledge EndOfData | Wait for downstream tasks acknowledge EndOfData | Wait for downstream tasks acknowledge EndOfData | |||
| Checkpoint Completed && EndOfData acknowledged | CLOSED | CLOSED | - | - | |
| Call operator.close() | Call operator.close() | Call operator.close() | |||
| Emit EndOfPartitionEvent | Emit EndOfPartitionEvent | Emit EndOfPartitionEvent |
Similarly, the status for the non-source tasks would become
| Event | Stream Task Status | Operator Status | Final Checkpoint | Stop with Savepoint with Drain | Stop with Savepoint |
|---|---|---|---|---|---|
| RUNNING | RUNNING | - | - | - | |
| - | - | - | |||
| - | - | - | |||
| Aligned on MAX_WATERMARK | Advanced To MAX_WATERMARK and trigger all the event timers | Advanced To MAX_WATERMARK and trigger all the event timers | N/A (MAX_WATERMARK is not emitted in this case) | ||
| Emit MAX_WATERMARK | Emit MAX_WATERMARK | N/A | |||
| Aligned On EndOfUserRecordsEvent | WAITING_FOR_FINAL_CP | FINISHED | call operator.endInput() & operator.finish() | call operator.endInput() & operator.finish() | - |
| Emit EndOfData[finished = true] | Emit EndOfData[finished = true] | Emit EndOfData[finished = false] | |||
| Aligned on Checkpoint Barrier | Emit CheckpointBarrier | Emit CheckpointBarrier | Emit CheckpointBarrier | ||
| Wait for Checkpoint / Savepoint Completed | Wait for Checkpoint / Savepoint Completed | Wait for Checkpoint / Savepoint Completed | |||
| Wait for downstream tasks acknowledge EndOfData | Wait for downstream tasks acknowledge EndOfData | Wait for downstream tasks acknowledge EndOfData | |||
| Wait for EndOfPartitionEvent | Wait for EndOfPartitionEvent | Wait for EndOfPartitionEvent | |||
| Checkpoint completed/EndOfData acknowledged/EndOfPartition received | CLOSED | CLOSED | |||
| Call operator.close() | Call operator.close() | Call operator.close() | |||
| Emit EndOfPartitionEvent | Emit EndOfPartitionEvent | Emit EndOfPartitionEvent |
We need to wait for a checkpoint to complete, that started after the finish() method. However, we support concurrent checkpoints. Moreover there is no guarantee the notifyCheckpointComplete arrives or the order in which they will arrive. It should be enough though to wait for notification for any checkpoint that started after finish(). |
Currently we have to deal with the case that tasks finished during triggering. Another option is to let the tasks synchronize with the CheckpointCoordinator on finishing: The tasks report finish status to CheckpointCoordinator, and CheckpointCoordinator cancels the pending checkpoints or replies with the pending checkpoints to wait for. The CheckpointCoordinator would maintains the finished status separately and use this status in computing of the following checkpoints.
Although this method could solve the inconsistency caused by tasks finished before get triggered, it would introduces additional complexity, and we would not apply this method present.
Another option for make CheckpointBarrierHandler support finished tasks is when received EndOfPartition from one channel, CheckpointBarrierHandler inserts the barriers for the pending checkpoints into this channel, right before the EndOfPartition event. These barriers would be processed the same as normal barriers received. The we could do not modify the CheckpointBarrierHandler logic.
However, this option could not support unaligned checkpoints before the EndOfPartition event has transferred to the downstream tasks, and it requires complex modification to the input channels, thus we do not use this option.
As discussed in the second section, the FLIP might change the behavior after failover if some operators have logic in initialization or endOfInput that relies on the state from the finished subtasks. However, such jobs would be rare and need to manually modify the job.
The FLIP would also modify the CompletedCheckpoint serialization format by also recording which operators are fully finished. However, this would not cause compatibility issues due to Java’s serialization mechanism supporting adding or deleting fields.
The target tasks to trigger are those who are still running but do not have any running precedent tasks. To avoid introducing large overhead to computing tasks to trigger for large jobs, we travel the JobGraph instead of traveling the ExecutionGraph directly. The algorithm is based on the following observation:
Based on the above observation, we could first do a fast check for each job vertex to see if it is possible to have some tasks to trigger. If the fast check fails, we know that for all the ALL_TO_ALL input edges, the upstream tasks must be finished, then we could only check if the tasks have running precedent tasks via POINTWISE edges. Therefore, the overall time complexity would be O(n).
each_jv:
for each job vertex JV;do
if all tasks of JV finished;then
continue;
endif
// The fast check
for each input job edge IJE;do
if (IJE is AlL_TO_ALL and some tasks are running) or (IJE is POINTWISE and all tasks are running);then
continue each_jv;
endif
endfor
for each task of JV;do
has_running_precedent_tasks = false;
for all the precedent tasks PT connected via POINTWISE edges;do
if PT is running;then
has_running_precedent_tasks = true;
break;
endif;
done
if task is running and !has_running_precedent_tasks;then
mark this task as need triggering;
endif
endfor
endfor |