Table of content
Glossary
Term |
Description |
|---|---|
CSN |
Change Sequence Number |
MMR |
Multi-Master Replication |
UUID |
Universally Unique IDentifier |
Replication analysis
Base operations
Replication is meant to transpose a modification done on one server into the associated servers. We should also insure that a modification done on an entry in more than one server does not lead to inconsistencies.
As the remote servers may not be available, due to network conditions, we also have to wait for the synchronization to be done before we can validate a full replication for an entry. For instance, if we delete an entry on server A, it can be deleted for real only when all the remote servers has confirmed that the deletion was successful.
Data structure
CSN and UUID
We will use two tags, stored within each entry, to manage the replication. The CSN (Change Sequence Number) stores when and where (which server) the entry was last modified. A replicated entry on 3 servers will have the same CSN. Before replication they may be different. The UUID (Universal Unique Identifier) is associated with an entry, and only one. So if we have an entry replicated on 3 servers, it will have one CSN (as the entry is at the same version for all servers) and only one UUID (as it's the same entry). The UUID is not currently used. The CSN stored in the entry is used to prevent older modifications overwriting newer ones. Unfortunately this leads to inconsistent servers (see DIRSERVER-894) - we need to check the CSN for each attribute instead. Once this is fixed the CSN stored on each entry will no longer be used.
CSN structure
A CSN is a composition of a timestamp, a replica ID and a operation sequence number. It's described in The LDAP Change Sequence Number. We have defined a simpler version, as the current RFC is still a draft, where we use a unique operationSequence instead of two integers (timeCount and changeCount) to disambiguate entries changed at the same time.
As the timestamp is computed using a System.currentTimeMillis() call, the accuracy is around 10 ms. We may have at hundreds of changes done in this interval. This is the reason we have a additional operationSequence number.
The CSN class structure is described by the following schema :

Basically, from the user POV, a CSN syntax is [timestamp:replicaId:operationSequence]
UUID structure
We use Java 5 UUID implementation, which is based on variant 2 of RFC 4122
Network
As Mitosis is a multi-master replication system, so each server has to be connected to the server it replicates with, and accept incoming connections from those servers.
We have two components :
- an Acceptor, for incoming replication operations
- N connectors, one per connected server.
The biggest problem we have is to connect to remote servers. As a starting server will have to reconnect to the remote servers, we will two problems :
- if the remote server is also starting, but has not yet established is listener, we won't be able to establish the connection
- if the servers are not time synchronized, we may not be able to correctly replicate a time based operation.
Network initialization
When a server starts, after having initialized the internal LDAP service, it has to start the network layer. The following algorithm is used :
start the Acceptor
set a retry interval to 2 seconds
until each remote server is connected do
for each not connected remote replica do
start a connector
if the connection is established
remove it from the list of disconnected server
done
if we have unconnected remote server
double the retry interval
else
exit
done
Basically, we try to connect to a remote server, and if we don't success, we wait for an increasing period of time before retrying. When we reach 60 seconds for this interval, we stop increasing the interval and simply try every minute.
Obviously, this is costly, and fragile, as a broken connection has to be detected and immediately restored, otherwise we can't replicate. Plus we don't manage scheduled downtime, as the server still tries to connect to the shutdown server even if it's on purpose.
Plus we have to store the pending operation until the connection is re-established.
Another approach would be to rely on a asynchronous system (Messages) to handle the server to server communication. The biggest advantage would be to rely on an proven system to manage connection and retries, instead of coding our own system inside ADS, with all the burden it brings. ActiveMQ could be a good option.
Store
We use a Database to store pending operations.
Database structure
We use 3 tables : REPLICATION_METADATA, REPLICATION_UUID and REPLICATION_LOG.
The "REPLICATION_" prefix can be configured, for instance if one want to define more than one ADS locally. It would make more sense to use the replicaID instead of this prefix, though.
REPLICATION_METADATA structure
field |
type |
Primary key |
description |
|---|---|---|---|
M_KEY |
VARCHAR(30) NOT NULL |
Yes |
|
M_VALUE |
VARCHAR(100) NOT NULL |
No |
|
REPLICATION_UUID structure
field |
type |
Primary key |
description |
|---|---|---|---|
UUID |
CHAR(36) NOT NULL |
Yes |
The entry UUID |
DN |
CLOB NOT NULL |
No |
The entry DN |
REPLICATION_LOG structure
field |
type |
Primary key |
description |
|---|---|---|---|
CSN_REPLICA_ID |
VARCHAR(16) NOT NULL |
Yes |
The replica ID |
CSN_TIMESTAMP |
BIGINT NOT NULL |
Yes |
The Timestamp |
CSN_OP_SEQ |
INTEGER NOT NULL |
Yes |
The op sequence |
OPERATION |
BLOB NOT NULL |
no |
The replication operation |
Operation storage
Each operation is logged into the REPLICATION_LOG table. It has to be serialized first to be put into the OPERATION field. The CSN is spread in three columns for a better search.
The serialized Operation structure will depend on the operation. In any case, its a triplet <OpType, CSN, [serialized op]>, where the [serialized op] can be composite. For instance, we may have something like <OpType, CSN, <OpType, CSN, entry> <Optype, CSN, entry>> if we deal with a composite operation.
The AddEntry operation is serialized as <OpType, CSN, Entry>
The XXXAttribute operations are serialized as <OpType, CSN, <dn, id, attribute>>
The composite operations are serialized as <OpType, CSN, list of serialized children>
The CSN is already a part of the entry for an Add operation, it's not necessary to serialize it.
The Id is already stored in the Attribute for every attribute operations, we can avoid serializing it.
We use a specific serialization, Java based, to store the operation. It would be way better to store a LDIF, assuming we always consider the CSN as a modified attribute.
Configuration
The replication system is a Multi-Master replication, ie, each server can update any server it is connected to. The way you tell a server to replicate to others is simple :
<replicationInterceptor>
<configuration>
<replicationConfiguration logMaxAge="5"
replicaId="instance_a"
replicationInterval="2"
responseTimeout="10"
serverPort="10390">
<s:property name="peerReplicas">
<s:set>
<s:value>instance_b@localhost:1234</s:value>
<s:value>instance_c@localhost:1234</s:value>
</s:set>
</s:property>
</replicationConfiguration>
</configuration>
</replicationInterceptor>
Here, for the server instance_a" we have associated two replicas : *instance_b and instance_c. Basically, you just give the list of remote server you want to be connected to.
The replication interceptor
The MITOSIS service is implemented as an interceptor in the current version (1.5.4). The following operations are handled :
- add
- delete
- hasEntry
- list
- lookup
- modify
- move
- moveAndRename
- rename
- search
The hasEntry, list, lookup and search operations are only handled to prevent tombstoned (deleted) entries being returned.
Interceptor initialization
When the interceptor is injected into the chain, its init() method is called, and it will initialize the full replication system. Here are the steps the init() method goes through :
- Validate the replication configuration
- Initialize the store
- Start the CSNFactory
- Start the networking sub-system
- Purge the aged data from the store
Then the service is ready to process new operations.
The purge of old data is not done atm unless the server is restarted. It has to be completed. We have a quartz job (ReplicationLogCleanJob) for this but it isn't scheduled by default - see Quartz Schedular Integration.
Operations classes
We are using Operation objects to manage replications inside the interceptor. Here is the Operation classes hierarchy :
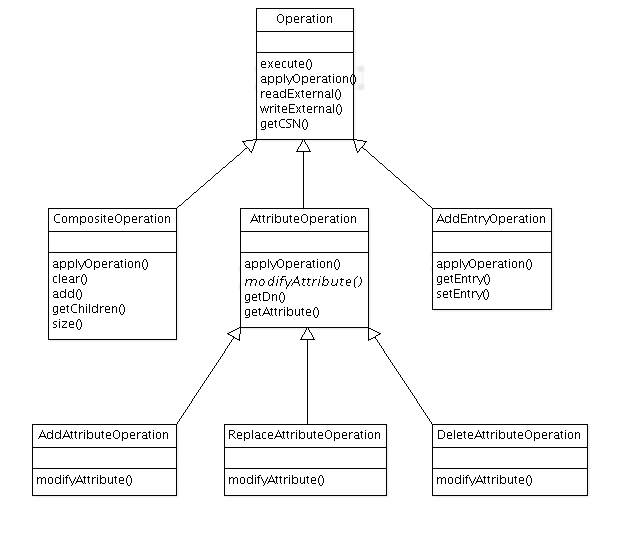
Each of the interceptor's method handling an entry modification will use one of those classes to store the resulting modification.
Operations
Add operation
It creates a AddEntryOperation object, with a ADD_ENTRY operation type (how useful is it, considering that we are already defined a specific class for such an operation ???), an entry and a CSN.
The newly created entry will contain two new AttributeType :
- an entryUUID with a newly generated UUID
- an entryDeleted set to FALSE
If the added entry already exists in the current server, then we should consider that the entry can't be added.
Currently, we check for more than the existence of the entry in the base. Either the entry is absent, and we can add it, or it's present, and we should discard the new entry, throwing an error.
Or another option is to consider that the entry has been created on more than one remote server, and then been created locally. We may have to replace the old entry by the new one, even if they are different. This is the current implementation.
What if the entry already exists, but with a pending 'deleted' state ? This has to be checked.
As we may receive a Add request from a remote server - per replication activation -, we currently create so called glue-entries. There are necessary if we consider that an entry is added when the underlaying tree is absent. This can happen in a MMR scenario where those missing entries have not been received yet, but the leaves have been.
Delete operation
It creates a CompositeOperation object, which contains a ReplaceAttributeOperation, as the entry is not deleted, but instead a entryDeleted AttributeType is added to the entry, and a ReplaceAttributeOperation containing the injection of a entryCSN AttributeType, with a newly created CSN.
So here are the operation content :
- ReplaceAttributeOperation
- entryDeleted, value TRUE
- ReplaceAttributeOperation
- entryCSN, with a new CSN
The delete operation should be a simple attribute Modification. Currently, two requests are sent to the backend (one for each added attribute), which is useless.