This page summarizes the detailed design of the new Kafka Streams runtime with the refactored threading model.
Goals and Key Ideas
Just a quick recap on the motivations of this new design
Improve cost-effectiveness with high utilization of allocated pod resources (CPU and memory primarily). E.g. we should be able to efficiently saturated the resources of the given pods before considering to scale and add more pods.
Optimize operational knobs that users need to learn about to make the runtime performant and stable. E.g. users should not need to worry about the embedded client’s configuration and stay with the default values most of the time.
Enable scheduling prioritization and isolation between query workloads within a cluster / app.
A better framework to integrate with cloud-native architectures, E.g. remote state management.
And the key ideas behind the design to tackle on the above goals:
Move from thread-dedicated Kafka clients to shared clients within an instance, with reduced num.connections and improved batching => goal 1).
Dedicated thread to interact with Kafka clients for blocking calls and misc workloads => goal 1), 2).
Dynamic task assignment with (optional) prioritized scheduling among processing threads => goal 1), 3).
Move state restoration workload from processing threads to a centralized state manager with dedicated threads => goal 2).
Move caching / state management into the centralized state managers as well, which may interact with a remote state service => goal 2), 4).
With the above key ideas in mind, below is the diagram of a single runtime instance (please compare it with the status-quo architecture of a single KS runtime), where:
Blue-boxes are modules that interact with each other and accessed by threads,
Yellow arrows indicate threads doing CPU work and move data between modules,
Dotted rectangles represent the unit of workload i.e. tasks,
Horizontal logs represent in-memory buffers, and
Vertical orange logs represent physical storage engines.
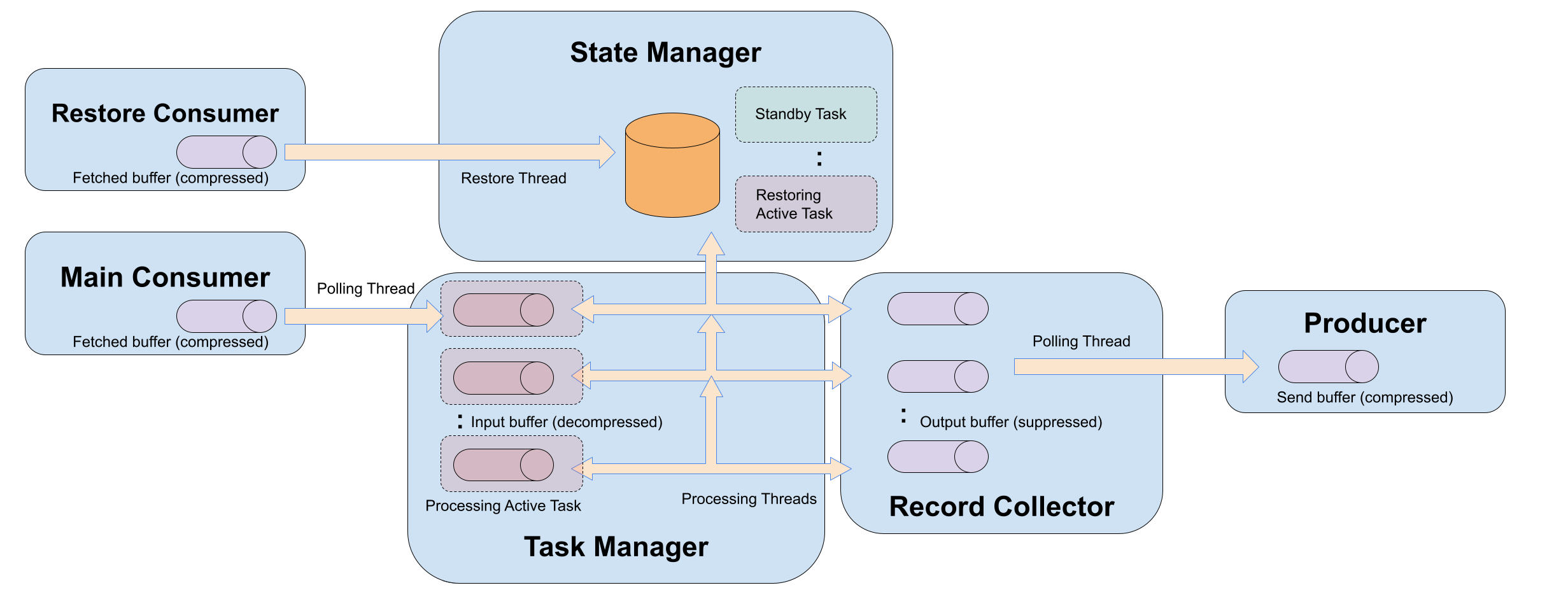
Modular Design Breakdowns
Each Kafka Streams runtime instance would contain the following modules:
One main consumer, used to fetch input partition records for assigned active tasks from the Kafka brokers. It has a fetched records buffer which contains the compressed record batches fetched by the consumer’s background thread. It is also used to participate in the rebalance protocol to assign tasks among instances.
One restore consumer, used to fetch changelog records for assigned standby tasks as well as restoring active tasks from the Kafka brokers. Similar as the main consumer it also has a buffer of compressed record batches that is fetched by the consumer’s background thread.
A task manager, which:
Maintains the list of assigned active tasks that are ready to be processed (i.e. have completed initialization and restoration).
For each of the maintained active tasks, keeps a decompressed input buffer for its fetched records polled from the main consumer. These records are polled and decompressed by the polling thread (see below).
Has a pool of processing threads along with a scheduler that determines dynamically which threads will process which assigned active tasks within the task manager. At any given time, each processing thread will process at most a single task, interact with the state manager to update the task’s states, and send result records as well as changelog records to the record collector. These threads will switch between active tasks periodically (see below).
A state manager, which:
Manages the state stores of all the assigned tasks. Logical states across multiple tasks can be maintained as consolidated physical stores.
Has a single restore thread that polls compressed record batches from the restore consumer and apply to the restoring standby and active tasks.
Interacts with the remote state management service to checkpoint local states to remote stores, and download state from remote storages upon restoration (see this doc for details.).
A record collector, which:
Maintains the output buffer per outgoing partition (both changelog as well as sink).
Suppress changelog records when possible before sending to the producer.
The same polling thread would drain from the output buffer and send to the producer.
A single producer that gets records from the polling thread, accumulates and compresses in its own send buffer, and finally send the compressed record batches to destination brokers.
Table of Threads
The following table summarizes all the threads in the new runtime. Within the Work column, the major resource consumption workload are highlighted.
Thread Type | Number | Interacting Modules | Work |
|---|---|---|---|
Processing thread | N (configurable) | Task Manager State Manager Record Collector | Runs in iterations until being shutdown. Periodically:
Within an iteration:
|
Polling thread | 1 (not configurable); | Main Consumer Task Manager Producer Record Collector | Runs in iterations until being shutdown. Within an iteration:
During the main consumer’s poll call, it may:
|
Consumer’s background thread | 2; one from the main consumer and one from the restore consumer | Main Consumer Restore Consumer |
|
Producer’s background thread | 1; from the producer | Producer |
|
Admin’s background thread | 1; from the admin | Admin |
|
Restoration thread | 1 (not configurable) | Restore Consumer State Manger |
|
Cleanup thread | 1 (not configurable) | State Manger |
|
RocksDB Metrics Triggering thread | 1 (not configurable) | State Manger |
|
Core Procedures
In this section we describe the procedures of certain core events.
New Task Creation
Polling thread gets the newly assigned tasks from the rebalance callback.
If the task does not exist at all, it will create and initialize the task. For standby tasks and active tasks that needs restoration, it will send them to the state manager.
During the initialization of the task, the local metadata checkpoint would be loaded first; if the checkpoint is not found, treat it as the metadata pointing at the beginning.
If the local state supports transactions, call the state to revert to the snapshot indicated by the loaded metadata.
If the task exist as an active task and now assigned as a standby task, try to recycle it as standby: if the task was not in task manager (which means it’s in the state manager), send a notification to the state manager to to let it stop restoring the state and send it back to the task manager, and then after recycling it into a standby task, send it back to the state manager; otherwise directly recycle it inside the task manager and then send the task to the state manager.
If the task exist as a standby task and now assigned as an active task, try to recycle it as active: the task has to be in the state manager for now, so send a notification event to the state manager to let it stop restoring the state and send it back to the task manager. The task manager would recycle it to an active task which would still be in the restoring state. The task would then be sent back to state manager to complete the restoration before it would be returned back to the task manager.
From the task’s point of view, it should be either at the task manager, accessed by the polling thread / processing threads; or at the state manager, accessed by the restoration thread, but never at both.
Existing Task Shutdown
Polling thread gets the revoked tasks from the rebalance callback.
If the task was not in the task manager (which means it’s in the state manager, either a standby, or an active task which’s still restoring), send a CLOSE event to the state manager. The tasks closure inside the state manager does not require committing the task, but only updating the state checkpoint.
Otherwise, close the processing active task inside the task manager directly after committing them.
Active Task Scheduling
Active tasks inside the task manager are ready to be processed, and there is a stream thread pool that grabs those tasks dynamically and process them. Each task inside the task manager has an exclusive lock that can be grabbed by at most one thread at a time.
The scheduling algorithm can be extensible with new requirements such as the new to assign priorities among queries (and hence their corresponding tasks). For example, A simple scheduling algorithm would work in the following way:
Each stream thread would periodically look into the task manager looking for tasks to process. The tasks would be sorted by the number of buffered input records, so that tasks with more buffered records would be picked first.
The thread would grab the lock on the task so that no other threads would be process this selected task. It would then move on to process the task’s records continuously, until 1) a pre-defined period of time has elapsed, or 2) the buffered input records have been exhausted. After that it will release the lock of the task and try to pick the next “high-priority“ tasks.
State Management for Active Processing Tasks
The state management procedure would be “extracted“ out of the tasks themselves and be handled within a consolidated module, a.k.a. the State Manager. Each task’s processing still interacts with the “state store“ APIs to read from/write into, and flush the states. But the actual implementations are provided by this State Manager which could optionally maintain multiple logical state stores (even from different tasks) into the same physical store engines.
The state store APIs are still layere but the layering would be slightly changed as “metered → change-logged → cached“ where the caching layer is managed by the state manager. More specifically:
Stream thread would touch on the metered layer to trigger the recording of the state store metrics.
Stream thread would touch on the change-logged layer to send the changelog record into the record collector (note it would not call on the producer, as it’s done by the polling thread).
Stream thread would touch on the state manager to finally update the state, and it’s abstracted away from the thread whether it only reaches the cache or get to the persistent layer at all. Nevertheless, reads from the state should be able to return uncommitted states.
Committing Active Tasks
Any task’s progress are tracked by the running metadata including “position“ and “time“, which is also used to identify the state snapshot of the task.
For standby tasks and restoring active tasks that are maintained in the state manager, they do not need to execute a full committing process. Instead, the state manager only need to periodically persist the advanced task metadata locally (when we have remote state management services, we may still need to persist the task’s metadata which would guide the state local cache warmup process).
As for those active processing tasks within the task manager, since we only have a single producer/consumer pair to execute the committing process, we need to always commit all the tasks at once. More specifically, we need to execute the following steps when we want to commit:
Flush the state of all active tasks within the task manager. If the state supports transactional updates, let the flush return a token which would be written as part of the task metadata to be persisted.
Write the changelog record of the metadata into the record collector.
Drain all the records inside the record collector and flush the producer.
Trigger the corresponding producer / consumer API depending on the processing mode (EOS or ALOS) to complete the commit.
Persist the advanced task metadata locally. NOTE this step can be done outside the EOS committing process and not be atomic, since even if we failed before this last step, we can still either 1) revert the local state to the last checkpoint and complete the restoration of the latest snapshot, or 2) bootstrap from the beginning to the latest snapshot.
Implementation Milestones
Here’s a proposal for achieving the above architecture in a step-by-step manner, where each step still leaves the architecture as a workable state.
Step | Scope | Benefits | |
|---|---|---|---|
Move restoration out of processing thread |
| Restoration would not impact processing thread from being kicked out of the group and triggering rebalance | KAFKA-10199 - Getting issue details... STATUS |
Introduce the processing threads |
| Reduce the likelihood of long blocking due to record processing | KAFKA-15326 - Getting issue details... STATUS |
Complete KIP-588 |
| Let the Streams to be more resilient with EOS error handling | KAFKA-9803 - Getting issue details... STATUS |
Consolidate the polling threads into a single thread NOTE: this is a major upgrade barrier and would be better included in a major release. |
| Reduce the number of embedded clients as stated above | |
Refactor the task committing procedure and exception handling logic |
| Make the runtime more resilient to errors. | |
Move state stores into the state manager |
| Efficient IO and less footprint in physical state stores. Integration with proposed cloud state storage. |