Status
Current state: [ UNDER DISCUSSION ]
Discussion thread:
JIRA: SAMZA-TBD
Released:
Problem
Kinesis is the fully managed publish subscribe message broker service offering from Amazon Web Service (AWS). This document covers the high level design of Kinesis system consumer for Samza.
Motivation
With the popularity of AWS and the rise in adoption of Samza for processing real-time data, it is essential that Samza integrates with Kinesis. There has been an increasing number of requests in Samza open source recently for Kinesis integration with Samza.
Proposed Changes
Kinesis streams pricing is based on the following factors:
Number of shards (at hourly rate)
Number of PUT records
Extended retention beyond default of 1 day (up to 7 days with hourly increments)
To make it cost effective, applications producing to Kinesis, instead of over-provisioning the shards, typically start with a small number of shards and increase the shard count (by dynamic re-sharding) based on the rate of data flow through the stream. Due to this re-sharding behavior of Kinesis, 1:1 association of Kinesis shards to Kafka partitions is not possible.
To marry Kinesis with Samza for re-partitioning purposes, we will use Kinesis Client Library (KCL) which has the following behavior:
Creates a new KinesisRecordProcessor for processing the records for each shard. Processing of records for different shards happens on different threads.
Dynamically load-balances the KinesisRecordProcessors across the containers.
Automatically handles dynamic re-sharding by creating a new KinesisRecordProcessor for the newly created child shards and load-balances them across the containers. KCL ensures that the processors for the new child shards are created only when all the records for the parent shard(s) are processed and checkpointed.
While Samza has the following behavior:
Number of partitions in the stream is determined by JobCoordinator in Samza ApplicationMaster (or JobCoordinator leader in the case of Samza stand-alone) during job startup which remains immutable until the job restart in the case of Samza on Yarn -or- until partition re-assignment happens as a result of container(s) being added/removed in the case of Zk based Samza stand-alone. SystemAdmin getSystemStreamMetadata() API returns the number of partitions.
ApplicationMaster (or JC leader) via JobModelManager determines the Task model (Ssp to Task assignment) and Container model (Task to Container assignment) based on the number of containers, number of partitions, SystemStreamPartition grouper and TaskName grouper. Job model does not change during the course of the job run until the job restart in the case of Yarn -or- until partition re-assignment in the case of Zk based Samza stand-alone.
As we can see, KCL load-balancing and Kinesis dynamic re-sharding behavior is not a natural fit for Samza as Samza expects the partition assignment to remain static through the course of the job run. However, we could make them work together just for stateless processing purposes.
KCL load-balancing
Samza has introduced AllSspToSingleTaskGrouper to tackle the partition management done by Kafka. This grouper assigns all partitions (ssps) to a single task. However, this was done for embedded Samza. Currently, this grouper won’t work as is for Samza on Yarn as only one task name is created irrespective of the number of containers. To fix this, we will modify AllSspToSingleTaskGrouper to create a unique task per container. The number of tasks created will be equivalent to the number of containers and each task will be assigned all the partitions.
SystemConsumer will maintain an in-memory ShardPartitionMapper which has a mapping of shards to ssps. When the above AllSSpToSingleTaskGrouper grouper is used, each container is assigned slots for ssps equivalent to the total number of shards (at the time of job startup) in the input stream. Whenever a shard is assigned to a container, system consumer assigns a free ssp slot to the shard and when that shard is re-assigned to a different container, the associated ssp slot is freed. As long as shard splits do not happen (shard merges are fine), there is always a free ssp slot to map to a shard. Since we support only stateless processing, this map need not be durable across container/job restarts. Both AllSspToSingleTaskGrouper and ShardPartitionMapper together should take care of dynamic load-balancing aspect of KCL. For Samza stand-alone, either PassthroughJobCoordinator or ZkJobCoordinator could be used.
Checkpointing
Let’s talk about checkpointing first before talking about dynamic re-sharding as checkpointing would have a say on how re-sharding needs to be solved.
KCL expects checkpointing to be done via KCL API to the dynamoDB table accompanying a Kinesis stream. KCL, on restarts, processes records from the shard sequence number (analogous to Kafka offset) that is committed to this table. For each Kinesis Streams application, the KCL uses a unique Amazon DynamoDB table to keep track of the application's state. Because the KCL uses the name of the Amazon Kinesis Streams application to create the name of the table, each application name (equivalent of Kafka consumer groupId) must be unique. Please note that the KCL does not let the applications to consume from any arbitrary point. IOW, it does not provide an equivalent of seek API if a checkpoint entry already exists for that application. Hence, “samza.reset.offset” config option won’t work with Kinesis System Consumer. If an application wants to reset offset, we can let KCL ignore the checkpoints by providing a different applicationName and then let it start from the oldest, latest or from a particular time-stamp. A config option will be introduced to specify where to start in the Kinesis stream, if there is no checkpoint.
While checkpointing frequency is driven by Samza’s OffsetManager, the checkpoint itself will be written via KCL to Kinesis. KinesisSystemConsumer implements CheckpointListener interface and writes the checkpoints to Kinesis for the given shards and offsets.
There could be a race between partition re-assignment and committing checkpoints. KCL throws an exception when a checkpoint is written to a shard that is not owned by the container. We will handle such an exception.
When a record is read from KinesisRecordProcessor, we create the IncomingMessageEnvelope offset with the following information:
Pair<ShardId, sequenceNumber>: ShardId and the sequenceNumber corresponding to the record that is being read. As part of Samza commit, SystemConsumer checkpoints the sequenceNumber to the corresponding shard through KCL. KCL, on restart, reads from the position next to the checkpointed sequenceNumber.
The above offset format works for 1:1 association of ssps to shards but to handle dynamic re-sharding, we will need to have 1:n mapping of ssps to shards. This requires maintaining a list of the last positions processed for all the shards that are mapped to this ssp, which is explained in next section.
Dynamic Re-sharding
There are two re-sharding operations to consider: splits and merges. Shard splits result in shutting down the parent shard and creating two new child shards while shard merges result in shutting down the two adjacent parent shards and creating a new child shard. Shard split poses a problem as it results in net addition of one shard.
When a shard split happens, ShardPartitionMapper could end up not having any free ssp slots to map a shard. We will then map the resulting new shard to an already mapped ssp. With 1:n mapping of ssps to shards, we will have to ensure that checkpointing is done for all these shards, as offsetManager calls checkpoint API per ssp with the last processed offset, which would be only one of the n shards that are mapped to that ssp. To account for all the n mapped shards, IncomingMessageEnvelope for the overloaded ssp should be created with an offset which tracks the lastOffset inserted into BlockingEnvelopeMap for all the shards that are mapped to the ssp.
Let’s take an example of shard split of a kinesis stream with 2 shards and samza processor with 2 containers.
- Initial state of Kinesis stream with two shards: Shard-0 and Shard-1. Two tasks, each with two ssps, are assigned across two containers. ShardPartitionMapper maps free ssp to each shard as below.
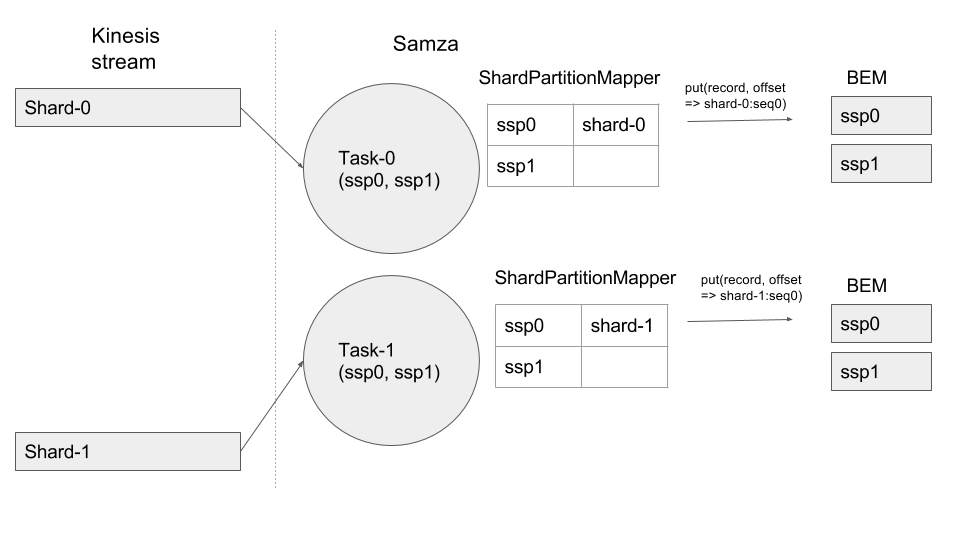
2. Shard-0 is split into Shard-2 and Shard-3. ShardPartitionMapper unmaps Shard-0 and maps new shards to free ssps as below.
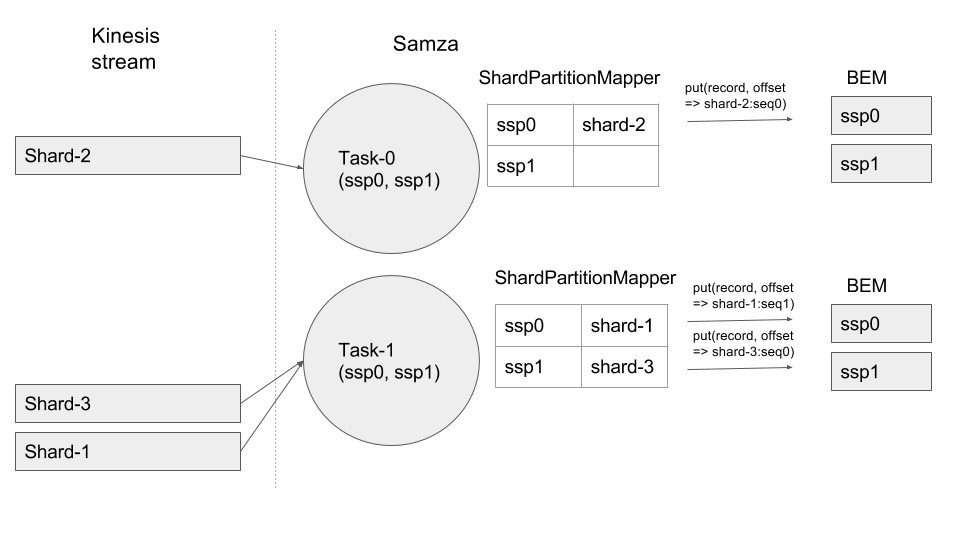
3. Shard-1 is split into Shard-4 and Shard-5. ShardPartitionMapper unmaps Shard-1 and maps new shards to free ssps as below.
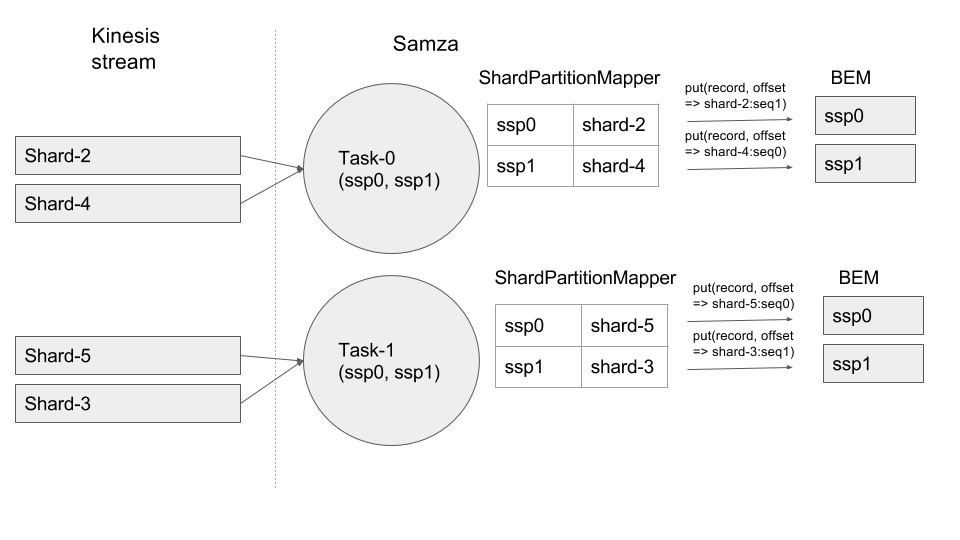
4. Shard-2 is split into Shard-6 and Shard-7. ShardPartitionMapper unmaps Shard-2 and since there are no free ssp slots to map the resulting new shards, it will map one of the new shards to an ssp which is already mapped to another shard. The offset of the record read from any of these shards mapped to the same ssp should now contain a list of all the sequence numbers of the latest records for all the other shards that are inserted into BEM, along with the sequence number for the current shard record that is going to be inserted into BEM. Please take a look at Task1:ssp1 below where a record for shard-3 arrives first followed by a record for shard-6.
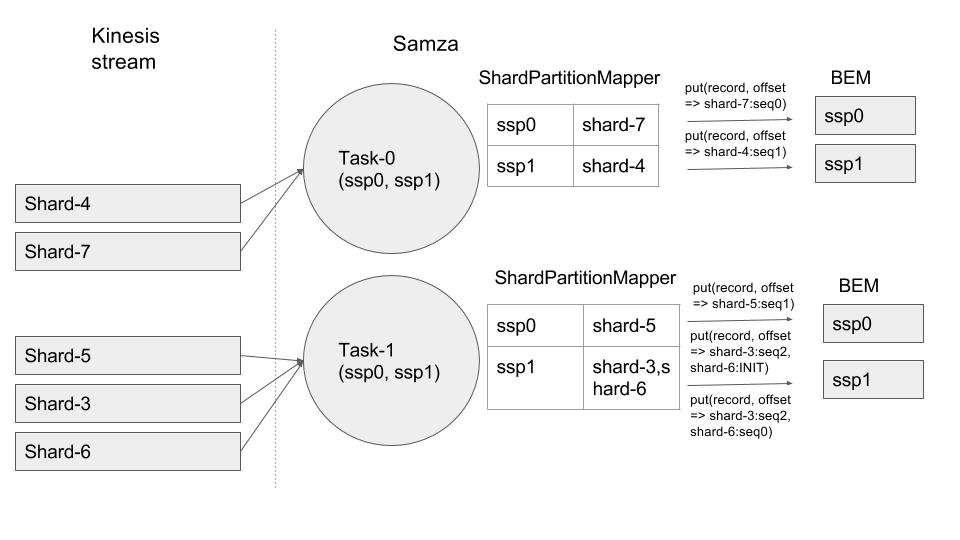
5. When a job is restarted, the number of ssps in each task will become equal to the shard count and the mapping between ssps and shards willl be 1:1.
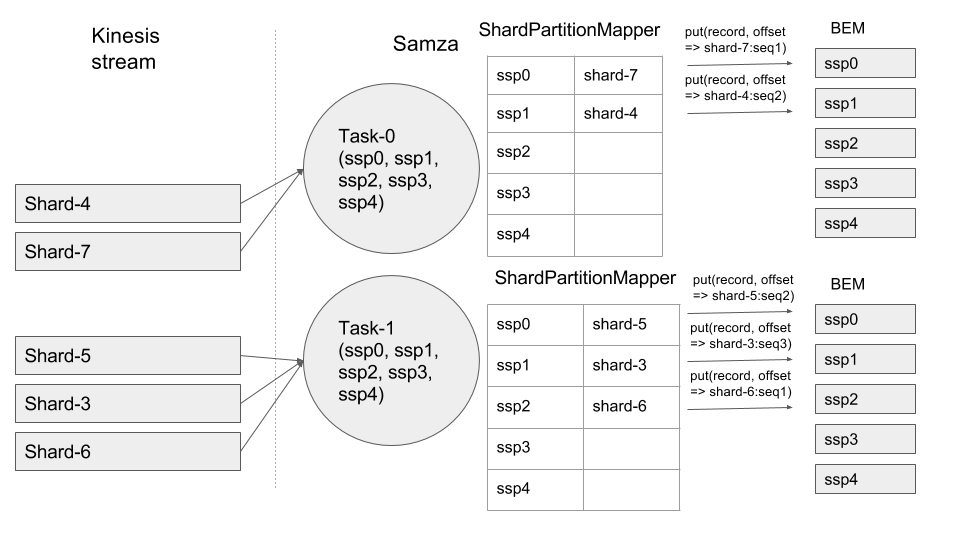
6. Let’s take the scenario where we add a container to keep up with the Kinesis stream throughput. On Yarn, one needs to make yarn container count config change and restart the job with the new config. This would result in recalculating job model. On stand-alone, adding a container would result in JobCoordinator leader to redo the job model.
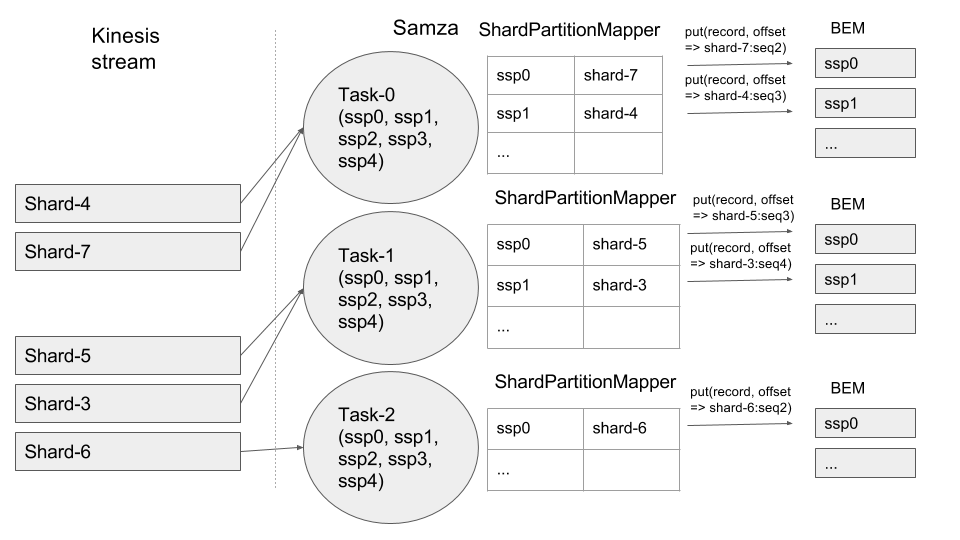
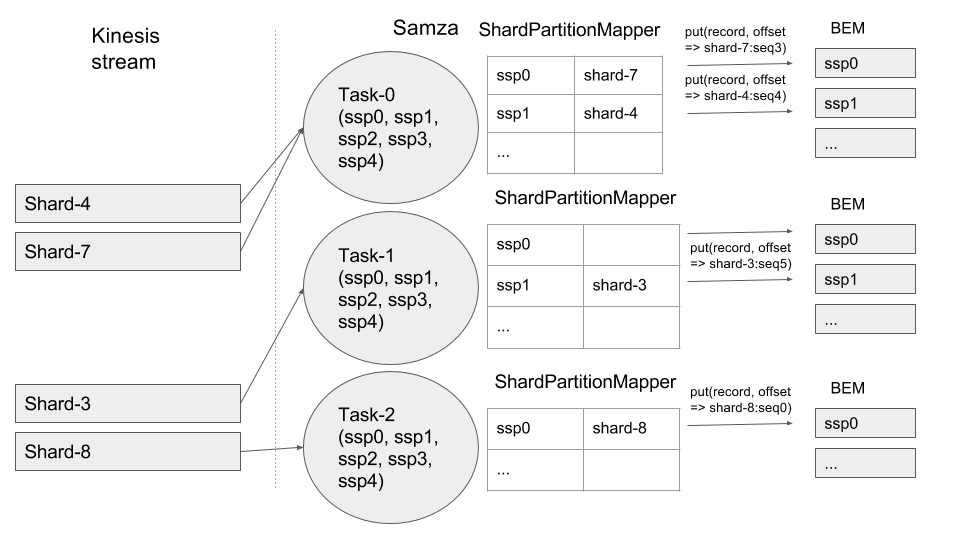
7. Shard-5 and Shard-6 are merged into Shard-8. ShardPartitionMapper unmaps Shard-5 and Shard-6 and maps the new shard to free ssp as below.
Limitations
The following limitations apply for Samza jobs consuming from Kinesis streams using the proposed consumer:
No support for stateful processing: It could be done as a second stage job after repartitioning to kafka in the first stage.
No support for broadcast streams.
Kinesis streams cannot be configured as bootstrap streams.
SystemStreamPartitionGroupers other than AllSspToSingleTaskGrouper are not supported.
A single Samza job cannot be configured to consume from a combination of Kinesis and Kafka inputs.
Using KCL needs IAM user R/W access to dynamoDB table and hence subject to costs associated with the table, in addition to the costs associated with the Kinesis stream itself. Since it is used only for periodic checkpointing, pricing should fall within the free tier bounds.
Public Interfaces
No changes to public interface.
Implementation and Test Plan
To be added.
Compatibility, Deprecation, and Migration Plan
As this is a new feature, no plans are required for compatibility, deprecation and migration.
Rejected Alternatives
Kinesis Streams API with 1:1 shard to ssp mapping
In Kafka parlance, KCL would be high-level API while Kinesis Streams API would be low-level API. With Kinesis Streams API and going with 1:1 association of shards to ssps, we would not have the problem of handling load-balancing problem as the partition management will be done by Samza. This has an advantage that we could use the default Ssp Grouper. But, we still have to handle the new shards that come up as a result of dynamic re-sharding. We need to ensure that all the records from the parent shard are processed before the child shards.
Option 1: Handle re-sharding transparently without any job/container restarts:
Since Samza does not support dynamic creation of partitions (ssps), this is not a viable option.
Option 2: Restart Samza Containers on detecting dynamic reshard:
The idea is for Job Coordinator (JC on ApplicationMaster in case of Yarn and leader JC in case of Samza standalone) to detect the change in number of shards and restart the containers. Today, JC has a partition monitoring thread which periodically calls SystemAdmin to get the stream metadata. We can add logic to restart all the containers when there is a change in the number of partitions. Restarting would result in creating the right number of partitions (ssps) to accommodate the new child shards and recomputing the job model. This still does not solve the problem completely. Consider the scenario where JC detects reshard and restarts containers before SystemConsumer processes/commits the last record from the parent shard. After restart, we still need to process records from the parent shard before processing child shards. Now, this coordination between parent and child shards would become really complicated if parent shard and child shards end up on different containers.
Kinesis Streams API by dividing the MD5 hash space
This proposal tries to handle stateful processing as well. The basic idea of this approach is to divide the Kinesis stream MD5 hash space as summerized in SAMZA-489.
We haven’t chosen this option for the following reasons:
Assumption that the output partitions are given.
Very complicated to implement.
Issues with checkpointing.
KCL with 1:1 shard to ssp mapping
The below options assume AllSspToSingleTask Grouper to handle load-balancing of partitions by KCL.
Option 1: Restart Samza Containers and re-compute job model on detecting dynamic reshard
JC as part of it's existing partition monitor thread will query SystemAdmin API to get shard count and stops all containers on detecting change in shard count, re-computes the job model and starts the containers.
Pros:
The same solution would work for Kafka repartitioning as well.
Cons:
This approach has the downside of restarting the containers on every re-shard, either it be split or merge.
Number of restarts will be more than the number of re-shard operations since the Kinesis API to get the shard count accounts for the parent shard as well until the last record in the parent shard expires. This will result in change in shard count once during the re-shard operation and then again when the parent shard(s) expires. We could choose to restart containers only when the shard count goes up from the previous count.
Option 2: Let Samza Container go down when 1:1 shard to ssp mapping is not possible
When System Consumer cannot find a free ssp to map a new shard, it will result in throwing an exception on the next poll in the runloop which eventually leads to restarting Samza Container. Just restarting the container would not take care of creating additional partitions(ssps) to handle new shards as job model is not re-computed. This approach will eventually lead to stopping the job. The job needs to be bounced to get it going with the new set of partitions.
Pros:
Shard merges won’t result in container restarts.
Container restarts also won’t happen when the parent shards expire and on every shard split.
Cons:
This approach has the downside of the job being stopped after certain number of container restarts on a shard split that it cannot handle. It needs to manually restarted.
KCL without Container restarts
Option 1: Make AllSspToSingleTask grouper to accept dynamic addition of ssps
Make AllSspToSingleTask grouper to allow dynamic addition of virtual partitions (ssps). This will involve changes to some of the core Samza classes: SystemConsumers poll() API to consider the dynamically added ssps as well and similar changes to BlockingEnvelopeMap to add a blocking queue for the new ssps. Due to the invasive nature of the changes, this option has not been considered.
Option 2: Introduce physicalPartition in SystemStreamPartition
Introduce physicalPartition concept in SystemStreamPartition in addition to the existing virtual partition. This physicalPartition could be a string (shardId) or an integer (parsed integer from shard). System Consumer creates ssps with the physicalPartition and only offsetManager will interpret the physicalPartition and uses it as key for the lastProcessedOffsets map. This will make sure that offsetManager maintains the checkpoint for each shard (physicalPartition) and calls commit on all the shards. This approach is again very invasive and would mean changes to the current semantics of SystemStreamPartition.