个人介绍
2021开源之夏的小伙伴们大家好啊,我是来自广州的小伙伴陈政羽,所学方向主要是大数据计算 和 Java,目前是作为Flink中文社区志愿者的一员,协助社区整理大数据实时计算引擎相关知识点和文章。欢迎各位多多与我交流大数据技术(文章末尾有我的个人联系方式)2021开源之夏的小伙伴们大家好啊,我是来自广州的小伙伴陈政羽,所学方向主要是大数据计算和Java,目前是作为Flink中文社区志愿者的一员,协助社区整理大数据实时计算引擎相关知识点和文章。欢迎各位多多与我交流大数据技术(文章末尾有我的个人联系方式)
有幸在开源之夏选上课题基于CarbonData 之 Presto 优化课题,这个课题主要是针对Presto使用CarbonData查询上做更多的一些优化。这个课题对于我来说十分有挑战点,涉及大数据领域的组件十分多,首先CarbonData作为大数据的一种文件存储格式,在OLAP计算引擎上的查询加速实现有助于数据更快的查询和产出;其次大数据涉及的组件和版本比较广泛,在测试、兼容各种方面带来的挑战会很多,例如Hadoop、Spark、Presto(Trino)、Hive等多个开源大数据组件的协同运行和调试,给项目的协同运行带来十分多挑战,如何把这些组件兼容完美的运行在CarbonData上面也是我的其中挑战点之一;最后开发我们是以课题性能优化为目标,提升用户的查询速度为主要目的去实现相关代码。明确了开发目标后,我们开始动手,首先我们先从了解这2个主要组件开始入手。
...
CarbonData是一种新型的Apache Hadoop本地文件格式,使用先进的列式存储、索引、压缩和编码技术,以提高计算效率,有助于加速超过PB数量级的数据查询,可用于更快的交互查询。同时,CarbonData也是一种将数据源与Spark集成的高性能分析引擎。CarbonData作为Spark内部数据源运行,不需要额外启动集群节点中的其他进程,CarbonData Engine在Spark Executor进程之中运行,运行架构如下

CarbonData特性
- SQL功能:CarbonData与Spark SQL完全兼容,支持所有可以直接在Spark SQL上运行的SQL查询操作。
- 简单的Table数据集定义:CarbonData支持易于使用的DDL(数据定义语言)语句来定义和创建数据集。CarbonData DDL十分灵活、易于使用,并且足够强大,可以定义复杂类型的Table。
...
从以上上述描述可以发现,CarbonData作为大数据的一种文件格式,通过一些压缩算法和快速查询索引技术提升查询速度和加速Spark查询,在交互式查询上面具有十分大的优势,下面我自己也做了个表格,通过简单对比目前开源社区上面已有的文件格式(ORC和Parquet)进行对比这3者的一些功能异同点

Presto(Trino)是什么?
Presto是什么是Facebook开源的,完全基于内存的并⾏计算,分布式SQL交互式查询引擎.是一种Massively parallel processing (MPP)架构,多个节点管道式执⾏,⽀持任意数据源(通过扩展式Connector组件),数据规模GB~PB级使用的技术,如向量计算,动态编译执⾏计划,优化的ORC和Parquet Reader等 ,它的查询架构如下:
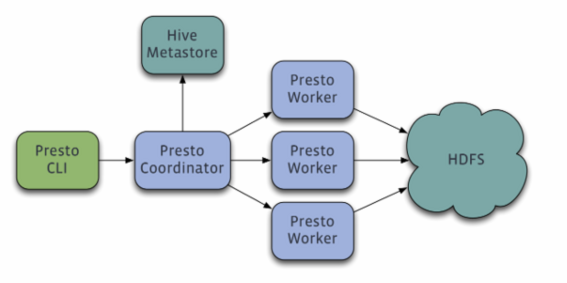

Presto查询引擎是一个Master-Slave的架构,由下面三部分组成:
...
Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息
一些数据模型划分的基本概念如下:


与hive的对比:
hive是一个数据仓库,是一个交互式比较弱一点的查询引擎,交互式没有presto那么强,而且只能访问hdfs的数据
presto是一个交互式查询引擎,可以在很短的时间内返回查询结果,秒级,分钟级,能访问很多数据源
与Spark对比的优缺点如下:
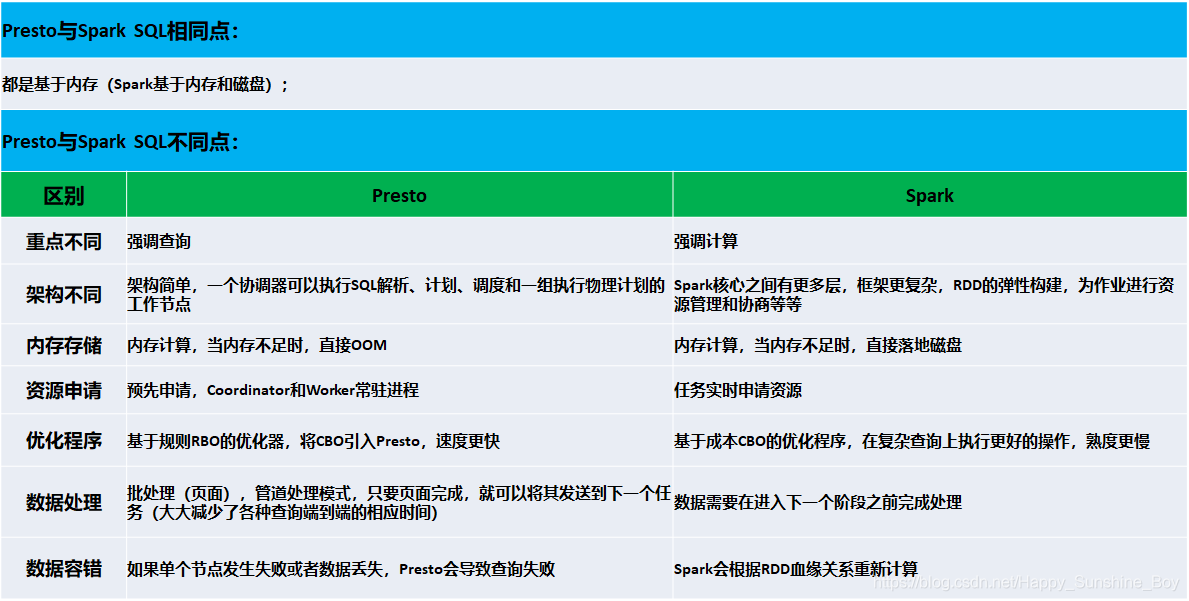

通过以上对比可以看出Presto擅长的领域主要在OLAP查询以及多数据的联邦查询上,可以进行跨库跨数据源查询
...
搭建Hadoop环境因为我是本地开发,所以我以伪分布式的模式去运行Hadoop,我这边选择使用的JDK版本是1.8,选择Hadoop版本是2.7.7。这个版本选择会影响后续使用Maven编译CarbonData,因为我们编译时候是需要指定编译的对应Hadoop版本的,我们尽量选择与其兼容版本。我们可以查看POM文件查看默认的版本
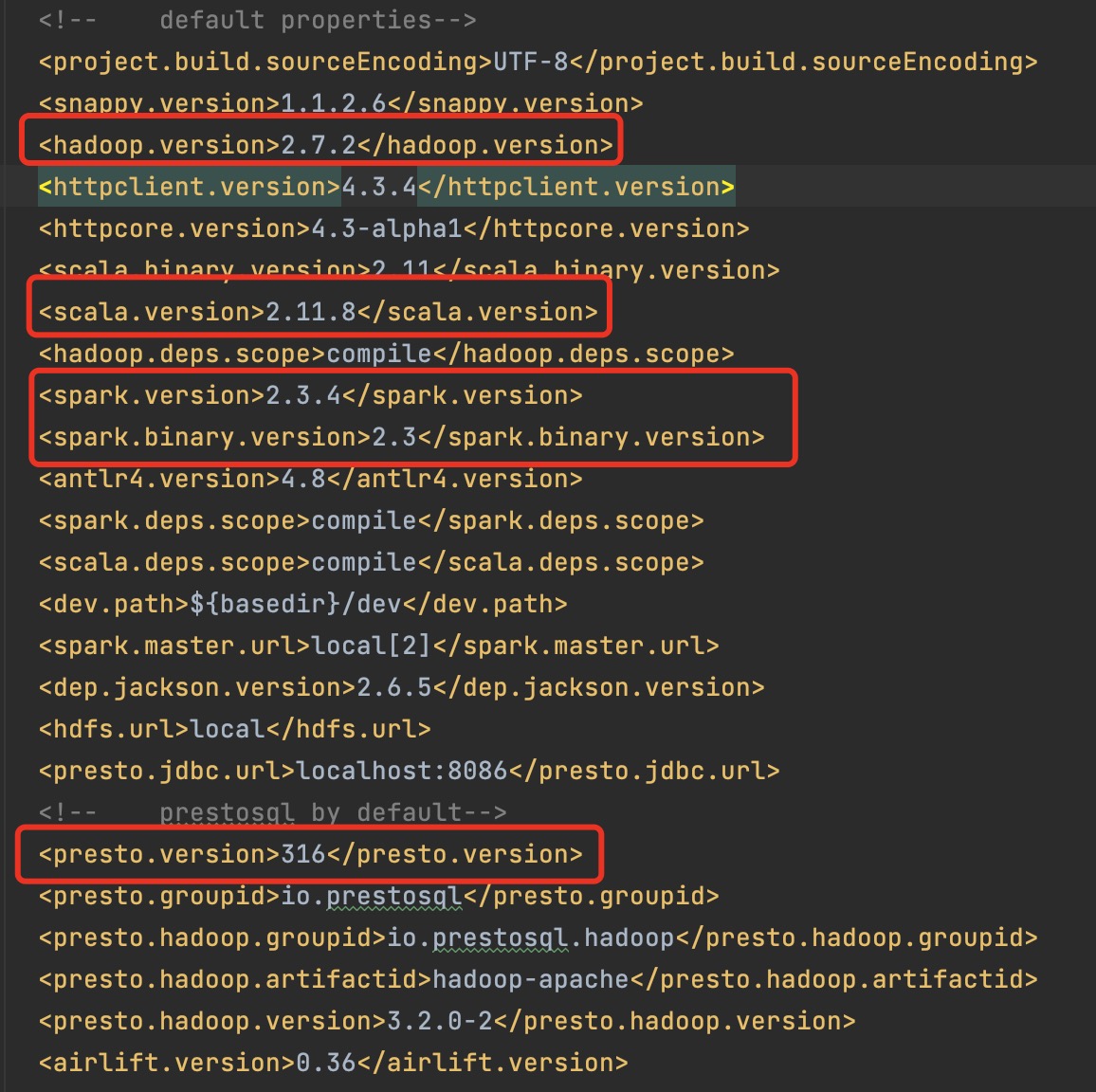

看以看到我红线框框的,我就基本上开始基于这些相近的版本进行开发。最终我选择的版本如下:
...
- 在Hive目录下启动 HiveServer2服务
- 在Spark目录下启动 ./sbin/start-all.sh 启动standalone
上面的组件我们都开启后,如下图

然后我们启动Spark-SQL-Cli查询时候
...
很明显这个是包缺乏的信息,根据思路,我们需要依赖Hive元数据进行查询,且观察Spark目录下已经有jackjson相关依赖,很明显就是Hive和Hadoop环境缺乏相关依赖。于是把相关jackjson依赖copy到hive的lib目录下面


然后重启所有组件,再次尝试查询,问题得以解决!!我们再次执行查询可以看到数据已经出来了


可以看到数据准确查询出来


创建表也没问题了~


Hive使用CarbonData
...
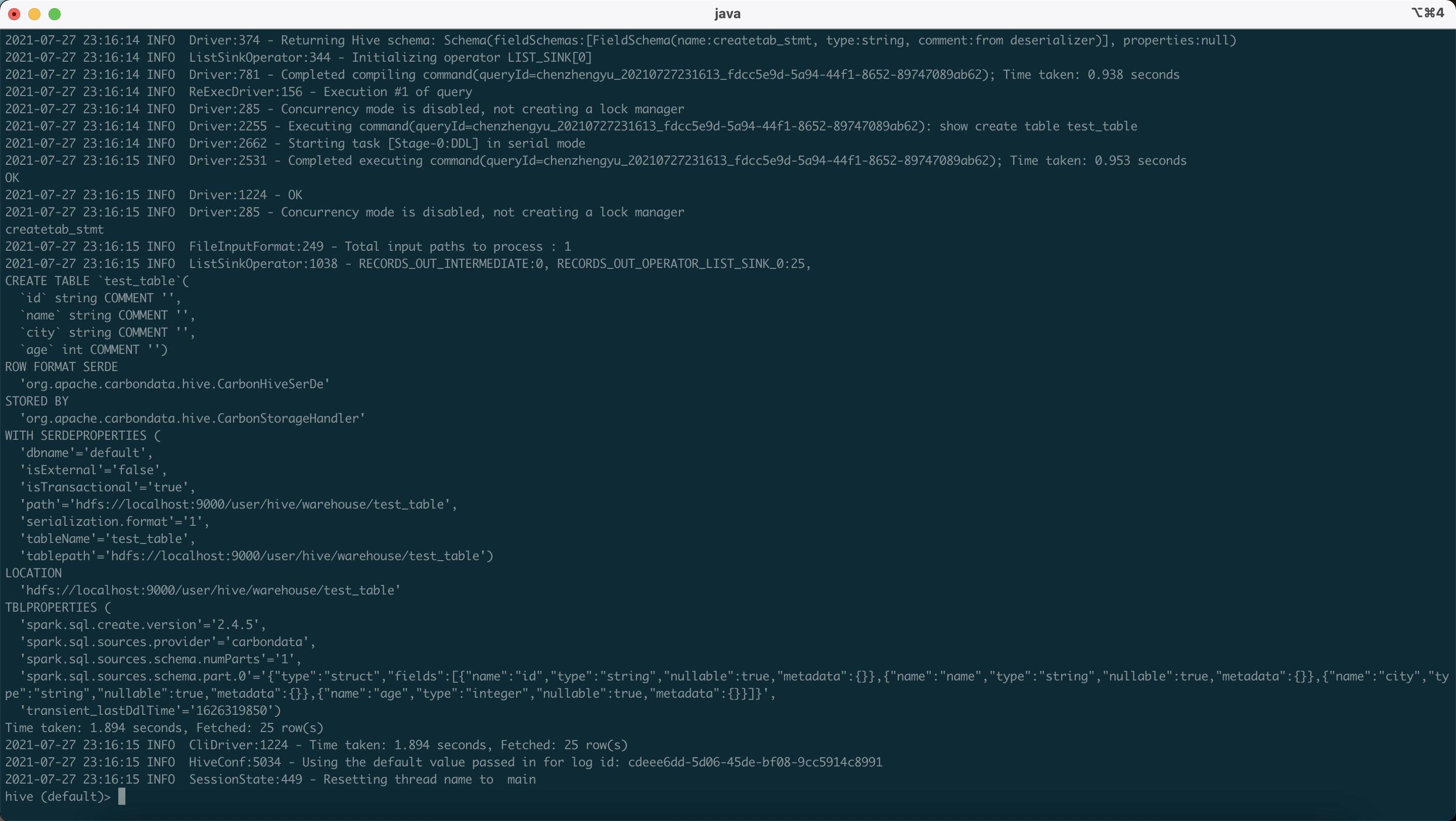
根据步骤我这边大概总结了一下步骤流程:因为使用Hive创建Carbondata表需要借助一些Spark-Api,故需要复制scala、Spark-catalyst*.jar 等相关依赖,并且把一个snappy文件复制到java安装目录下,以及将所有carbon开头的依赖复制到hive/lib和yarn/lib目录下,这样在提交yarn任务执行时候能够找到对应依赖。按照步骤操作后,最终在Hive上成功操作CarbonData表,结果如下:


运行建表语句查看表类型,我们可以看到是CarbonData表,然后对应创建的Spark版本号,路径等信息一一列举了出来

Presto使用CarbonData
...
把这个编译好之后的目录Jar包重命名后复制到Presto-316 的 Plugin 文件夹下面,Presto后面会借助Java SPI机制加载这个插件

于此同时我们配置好Presto 单节点的一些相关配置
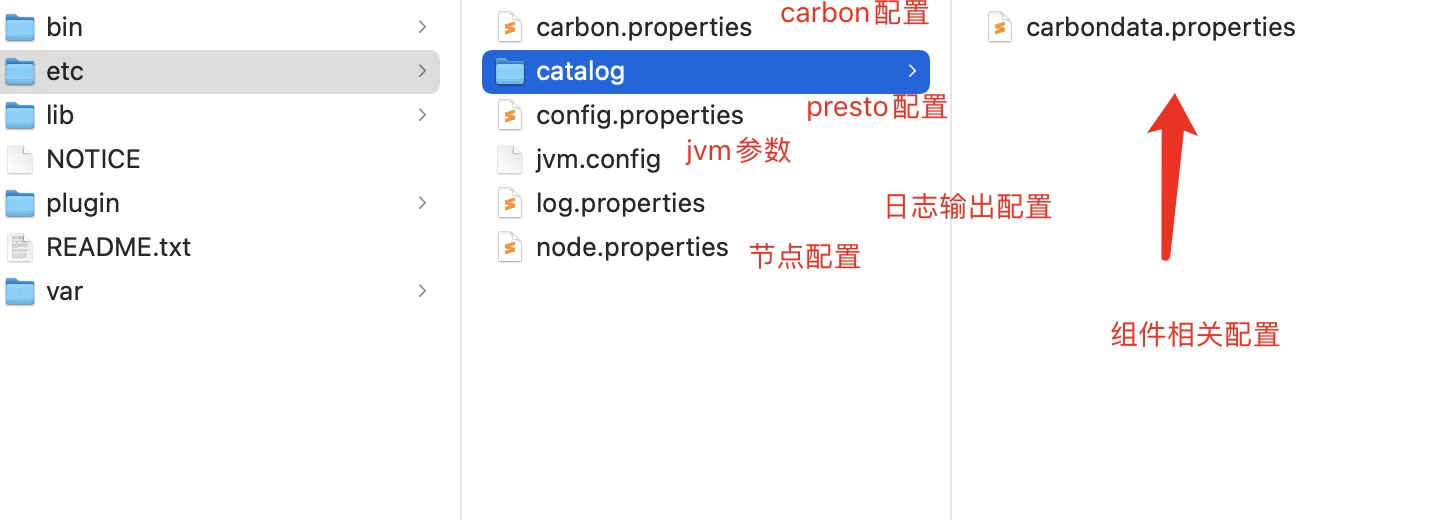

carbondata.properties
...
./bin/launcher run
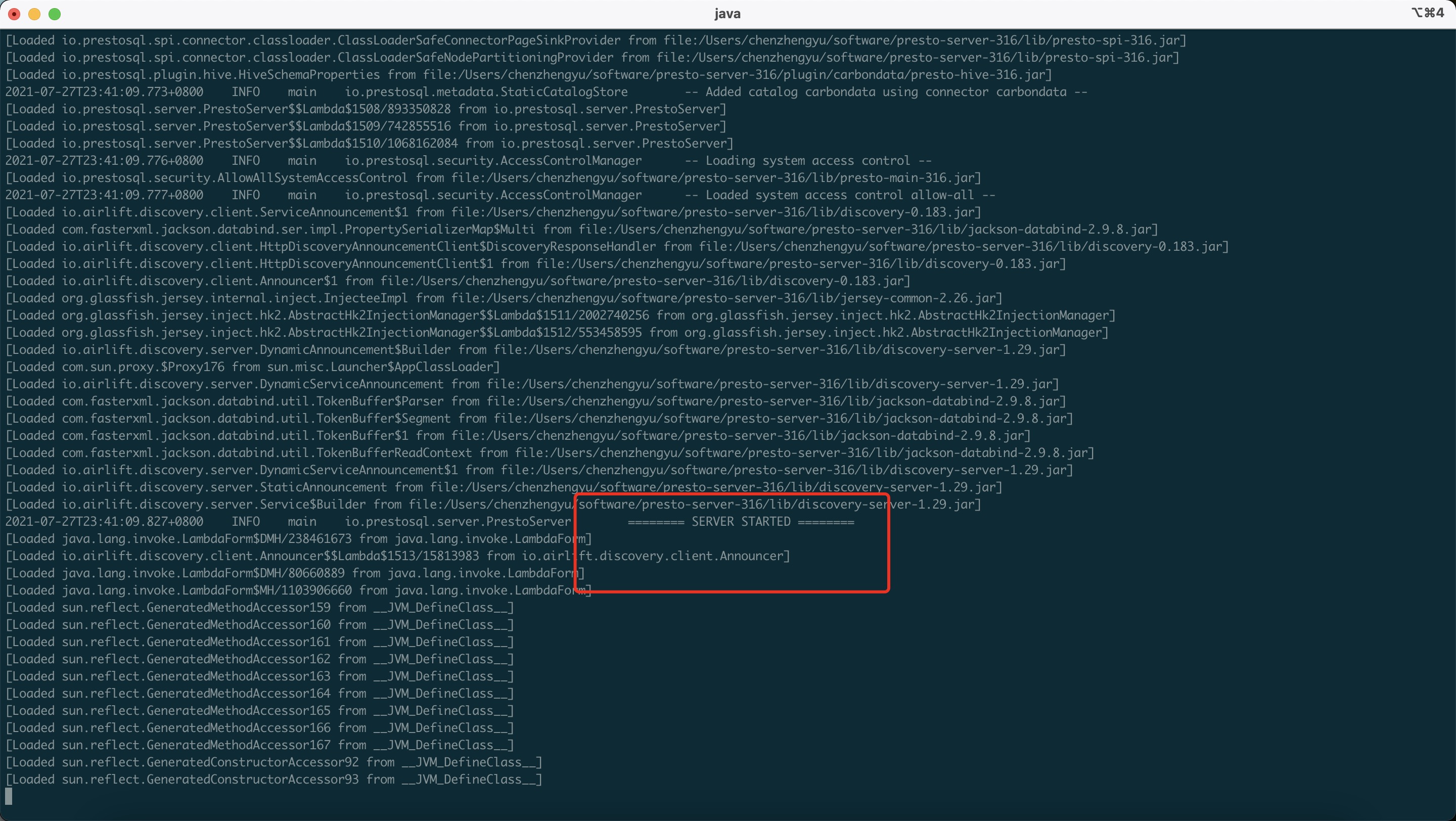
看到如下图字样证明已经启动成功了

然后我们使用客户端Jar启动进行查询
java -jar presto.jar --server localhost:8086 --catalog carbondata
查询结果如下:


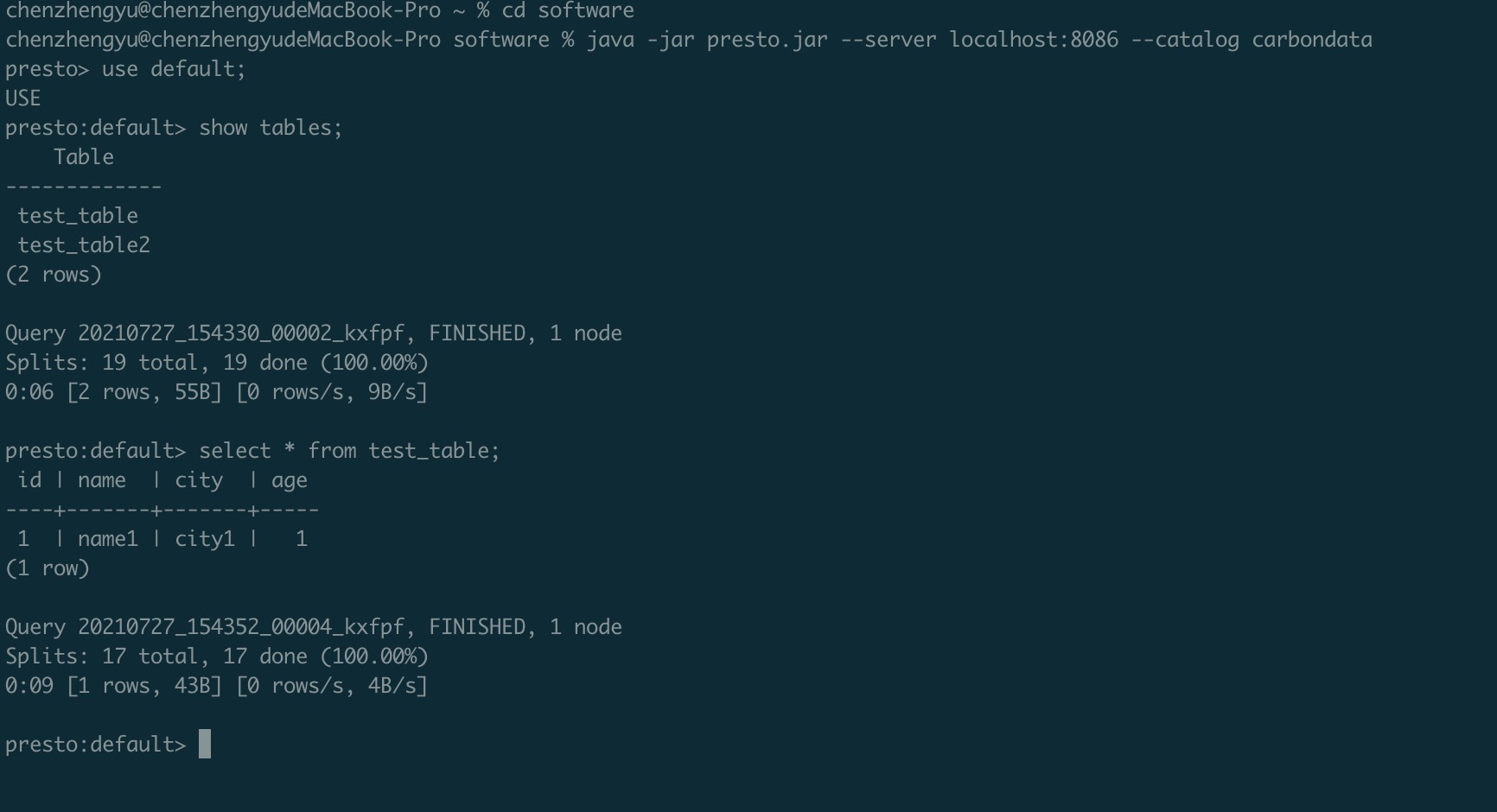

可以看到我们Presto已经成功查询了,并且能够正确的连接到Hive元数据
...
欢迎各位持续关注CarbonData,在Apache Asia Cron大会上,Apache CarbonData将有2个议题参与会议,关于 星展银行[新加坡发展银行]的数据平台如何利用Apache CarbonData推动实时洞察和分析 和 通过使用Apache CarbonData的索引加快大数据分析的速度 的相关演讲,也欢迎大家积极报名观看线上演讲,让更多人了解 Apache CarbonData。
我的Github:https://github.com/czy006