Status
Current state: Under discussion
Discussion thread:
JIRA:
KAFKA-8587
-
Getting issue details...
STATUS
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
Exactly once semantics (EOS) provides transactional message processing guarantees. Producers can write to multiple partitions atomically so that either all writes succeed or all writes fail. This can be used in the context of stream processing frameworks, such as Kafka Streams, to ensure exactly once processing between topics.
In Kafka EOS, we use the concept of a "transactional Id" in order to preserve exactly once processing guarantees across process failures and restarts. Essentially this allows us to guarantee that for a given transactional Id, there can only be one producer instance that is active and permitted to make progress at any time. Zombie producers are fenced by an epoch which is associated with each transactional Id. We can also guarantee that upon initialization, any transactions which were still in progress are completed before we begin processing. This is the point of the initTransactions() API.
The problem we are trying to solve in this proposal is a semantic mismatch between consumers in a group and transactional producers. In a consumer group, ownership of partitions can transfer between group members through the rebalance protocol. For transactional producers, assignments are assumed to be static. Every transactional id must map to a consistent set of input partitions. To preserve the static partition mapping in a consumer group where assignments are frequently changing, the simplest solution is to create a separate producer for every input partition. This is what Kafka Streams does today.
This architecture does not scale well as the number of input partitions increases. Every producer come with separate memory buffers, a separate thread, separate network connections. This limits the performance of the producer since we cannot effectively use the output of multiple tasks to improve batching. It also causes unneeded load on brokers since there are more concurrent transactions and more redundant metadata management.
Proposed Changes
We argue that the root of the problem is that transaction coordinators have no knowledge of consumer group semantics. They simply do not understand that partitions can be moved between processes. Let's take a look at a sample exactly-once use case, which is quoted from KIP-98:
public class KafkaTransactionsExample {
public static void main(String args[]) {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerConfig);
KafkaProducer<String, String> producer = new KafkaProducer<>(producerConfig);
producer.initTransactions();
while(true) {
ConsumerRecords<String, String> records = consumer.poll(CONSUMER_POLL_TIMEOUT);
if (!records.isEmpty()) {
producer.beginTransaction();
List<ProducerRecord<String, String>> outputRecords = processRecords(records);
for (ProducerRecord<String, String> outputRecord : outputRecords) {
producer.send(outputRecord);
}
sendOffsetsResult = producer.sendOffsetsToTransaction(getUncommittedOffsets());
producer.endTransaction();
}
}
}
}
Currently transaction coordinator uses the initTransactions API currently in order to fence producers using the same transactional Id and to ensure that previous transactions have been completed. We propose to switch this guarantee on group coordinator instead.
In the above template, we call consumer.poll() to get data, but internally for the very first time we start doing so, we need to know the input topic offset. This is done by a FetchOffset call to group coordinator. With transactional processing, there could be offsets that are "pending", I.E they are part of some ongoing transaction. Upon receiving FetchOffset request, broker will export offset position to the "latest stable offset" (LSO), which is the largest offset that has already been committed. Since we rely on unique transactional.id to revoke stale transaction, we believe any pending transaction will be aborted when producer calls initTransaction again. During normal use case such as Kafka Streams, we will also explicitly close producer to send out a EndTransaction request to make sure we start from clean state.
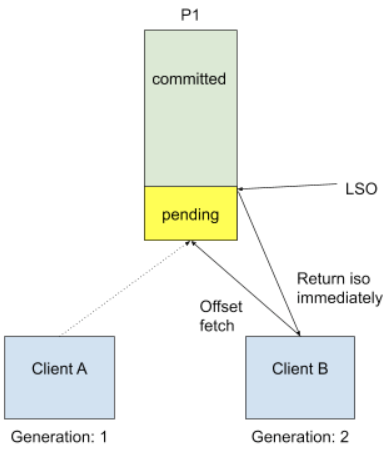
It is no longer safe to do so when we allow topic partitions to move around transactional producers, since transactional coordinator doesn't know about partition assignment and producer won't call initTransaction again during its lifecycle. The proposed solution is to reject FetchOffset request by sending out PendingTransactionException to new client when there is pending transactional offset commits, so that old transaction will eventually expire due to transaction.timeout, and txn coordinator will take care of writing abort markers and failure records, etc. Since it would be an unknown exception for old consumers, we will choose to send a COORDINATOR_LOAD_IN_PROGRESS exception to let it retry. When client receives PendingTransactionException, it will back-off and retry getting input offset until all the pending transaction offsets are cleared. This is a trade-off between availability and correctness, and in this case the worst case for availability is just waiting transaction timeout.
Below is the new approach we introduce here.

Note that the current default transaction.timeout is set to one minute, which is too long for Kafka Streams EOS use cases. It is because the default commit interval was set to 100 ms, and we would first hit session timeout if we don't actively commit offsets during that tight window. So we suggest to shrink the transaction timeout to be the same default value as session timeout (10 seconds), to reduce the potential performance loss for offset fetch delay.
Public Interfaces
The main addition of this KIP is a new variant of the current initTransactions API which gives us access to the consumer group states, such as member.id and generation.id.
interface Producer {
/**
* This API shall be called for consumer group aware transactional producers.
*/
void initTransactions(Consumer<byte[], byte[]> consumer); // NEW
/**
* No longer need to pass in the consumer group id in a case where we already get access to the consumer state.
*/
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets); // NEW
}
Here we introduced an intermediate data structure `GroupAssignment` just to make the evolvement easier in case we need to add more identification info during transaction init stage. There are two main differences in the behavior of this API and the pre-existing `initTransactions`:
- The first is that it is safe to call this API multiple times. In fact, it is required to be invoked after every consumer group rebalance or dynamic assignment.
- The second is that it is safe to call after receiving a `ProducerFencedException`. If a producer is fenced, all that is needed is to rejoin the associated consumer group and call this new `initTransactions` API.
The new thread producer API will highly couple with consumer group. We choose to define a new producer config `transactional.group.id`.
public static final String TRANSACTIONAL_GROUP_ID = "transactional.group.id";
This config value will be automatically set to consumer group id on Kafka Streams app. For plain EOS user, you need to manually configure that id to the consumer group id if you are not following the recommend practice below by calling `initTransaction(consumer)`.
We could effectively unset the `transactional.id` config in Kafka Streams because we no longer use it for revoking ongoing transactions. Instead we would stick to consumer group id when we rely on group membership. To enable this, we need to extend the InitProducerId API to support consumer group aware initialization.
Below we provide the new InitProducerId schema:
InitProducerIdRequest => TransactionalId TransactionTimeoutMs ConsumerGroupId AssignedPartitions TransactionalId => NullableString TransactionTimeoutMs => Int64 TransactionalGroupId => NullableString // NEW InitProducerIdResponse => ThrottleTimeMs ErrorCode ProducerId ProducerEpoch ThrottleTimeMs => Int64 ErrorCode => Int16 ProducerId => Int64 ProducerEpoch => Int16
The new InitProducerId API accepts either a user-configured transactional Id or a transactional group Id. When a transactional group is provided, the transaction coordinator will honor transactional group id and allocate a new producer.id every time initTransaction is called. Here a small optimization to help us reuse producer.id is to piggy-back consumer member.id as the transactional.id field during the first time rebalance and keep it unchanged. One more optimization is to use `group.instance.id` if it's set on the consumer side, which is guaranteed to be unique.
The main challenge when we choose a random transactional.id is authorization. We currently use the transaction Id to authorize transactional operations. In this KIP, we could instead utilize the transactional.group.id(consumer group id) for authorization. The producer must still provide a transactional Id if it is working on standalone mode though.
Fencing zombie
A zombie process may invoke InitProducerId after falling out of the consumer group. In order to distinguish zombie requests, we need to leverage group coordinator to fence out of generation client.
A new generation id field shall be added to the `TxnOffsetCommitRequest` request:
TxnOffsetCommitRequest => TransactionalId GroupId ProducerId ProducerEpoch Offsets GenerationId TransactionalId => String GroupId => String ProducerId => int64 ProducerEpoch => int16 Offsets => Map<TopicPartition, CommittedOffset> GenerationId => int32 // NEW
If the generation.id is not matching group generation, the client will be fenced immediately. An edge case is defined as:
1. Client A tries to commit offsets for topic partition P1, but haven't got the chance to do txn offset commit before a long GC. 2. Client A gets out of sync and becomes a zombie due to session timeout, group rebalanced. 3. Another client B was assigned with P1. 4. Client B doesn't see pending offsets because A hasn't committed anything, so it will proceed with potentially `pending` input data 5. Client A was back online, and continue trying to do txn commit. Here if we have generation.id, we will catch it!
We also need to apply a new on-disk format for transaction state in order to persist both the transactional group id and transactional id. We propose to use a separate txn key type in order to store the group assignment. Transaction state records will not change.
Key => TransactionalId, TransactionalGroupId TransactionalId => String TransactionalGroupId => String
And here is a recommended new transactional API usage example:
Set<String> topics = buildSubscription();
KafkaConsumer consumer = new KafkaConsumer(buildConsumerConfig(groupId));
KafkaProducer producer = new KafkaProducer();
consumer.subscribe(topics, new ConsumerRebalanceListener() {
void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// Will access consumer internal state. Only called once in the app's life cycle after first rebalance.
producer.initTransactions(consumer);
}
});
while (true) {
// Read some records from the consumer and collect the offsets to commit
ConsumerRecords consumed = consumer.poll(Duration.ofMillis(5000)); // This will be the fencing point if there are pending offsets for the first time.
Map<TopicPartition, OffsetAndMetadata> consumedOffsets = offsets(consumed);
// Do some processing and build the records we want to produce
List<ProducerRecord> processed = process(consumed);
// Write the records and commit offsets under a single transaction
producer.beginTransaction();
for (ProducerRecord record : processed)
producer.send(record);
try {
producer.sendOffsetsToTransaction(consumedOffsets);
} catch (IllegalGenerationException e) {
throw e; // fail the zombie member if generation doesn't match
}
producer.commitTransaction();
}
The main points are the following:
- Consumer group id becomes a config value on producer.
- Generation.id will be used for group coordinator fencing.
- We no longer need to close the producer after a rebalance.
Compatibility, Deprecation, and Migration Plan
This is a server-client integrated change, and it's required to upgrade the broker first with `inter.broker.protocol.version` (IBP) to the latest. Any produce request with higher version will automatically get fenced because of no support. For the case of Kafka Streams, we will apply an automated approach. Upon application initialization, we use admin client to send out an ApiVersionRequest to bootstrap servers to know their current version. If all members' responses indicates that they do support 447 features, we shall initialize the application with thread producer when EOS is on; otherwise we shall use the old producer per task semantics.
In a tricky case user attempts to downgrade, we shall throw exception and ask application user to restart their clients to use old API.
A minor thing to take care here is that we haven't implemented the ApiVersion request under KIP-117. We shall fulfill this API gap during the implementation.
Rejected Alternatives
- Producer Pooling:
- Producer support multiple transactional ids:
- Tricky rebalance synchronization:
- We could use admin client to fetch the inter.broker.protocol on start to choose which type of producer they want to use. This approach however is harder than we expected, because brokers maybe on the different versions and if we need user to handle the tricky behavior during upgrade, it would actually be unfavorable. So a hard-coded config is a better option we have at hand.
- We have considered to leverage transaction coordinator to remember the assignment info for each transactional producer, however this means we are copying the state data into 2 separate locations and could go out of sync easily. We choose to still use group coordinator to do the generation and partition fencing in this case.