The data of Point is encoded in a block KD-tree structure described with three index files:
.kdd

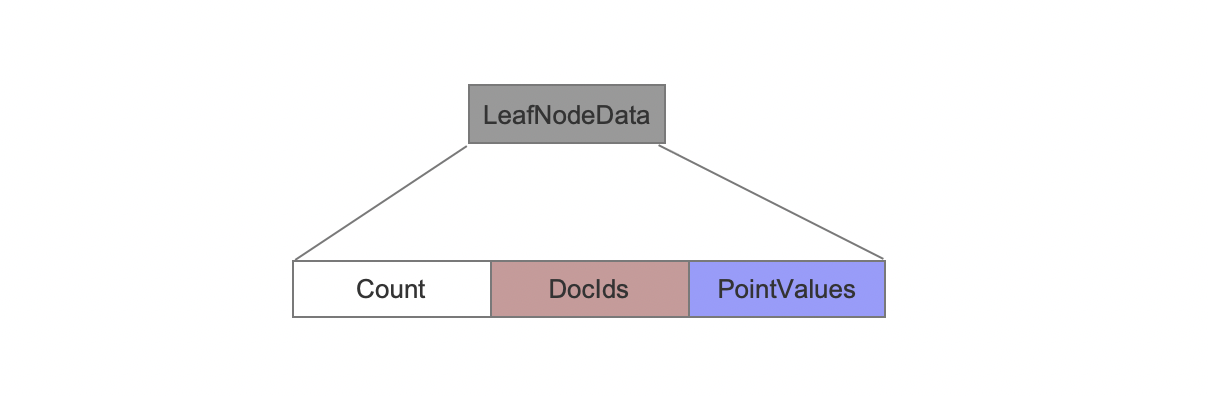
Count
Count describes the number of points in a LeafNodeData.
DocIds
DocIds describes a set of document IDs which a point in a LeafNodeData belongs to.
PointValues
PointValues describes a set of point values, each point value is split into two parts: CommonPrefixes and BlockPackedValues.
CommonPrefixes
CommonPrefixes describes a set of common prefixes with each dimension.

Fig.3
length Value
Value describes the common prefix value with byte and Length means the length of common prefix value (number of bytes).
BlockPackedValues
BlockPackedValues describes the suffix of point value. BlockPackedValues has two types of data structure according to the suffix. Due to the length of this article, it is not appropriate to extend it, we just need to known the suffix of point value was stored under compression by run-Length Encoding.
.kdi
The data structure of .kdi file as below:
 Fig.4
Fig.4
PackedIndexValue
PackedIndexValue describes the informations of all inner nodes(also known as branch node). inner node has four types of data structures according to the position in KD-tree and its sub node.
- RightNodeHasLeafChild: the inner node is the right node of its parent node and its child nodes are leaf nodes
- RightNodeHasNotLeafChild: the inner node is the right node of its parent node and its child nodes are not leaf nodes
- LeftNodeHasLeafChild: the inner node is the left node of its parent node and its child nodes are leaf nodes
- LeftNodeHasNotLeafChild: the inner node is the left node of its parent node and its child nodes are not leaf nodes
Root node as a inner node and it belongs to RightNodeHasNotLeafChild.
RightNodeHasNotLeafChild

Fig.5
LeftLeafBlockFP
LeftLeafBlockFP describes a pointer where the position of the leftmost leaf node of current inner node in .kdd file is.
Code
Code describes the metadata about inner node, such as spilt dimension or bytes per dimension(How many bytes each value in each dimension takes).
SplitValue
In the stage of constructing a KD-tree, the set of points in a inner node will be split into two sub nodes according to SpiltValue which is a value of one of the dimension.
LeftNumBytes
LeftNumBytes describes the total size of one inner node's left sub tree.
RightNodeHasNotLeafChild

Fig.6
LeftNumBytes, Code and SplitValue describes the same meaning as above.
RightLeafBlockFP
RightLeafBlockFP describes a pointer where the position of the right leaf node of current inner node in .kdd file is.
LeftNodeHasLeafChild
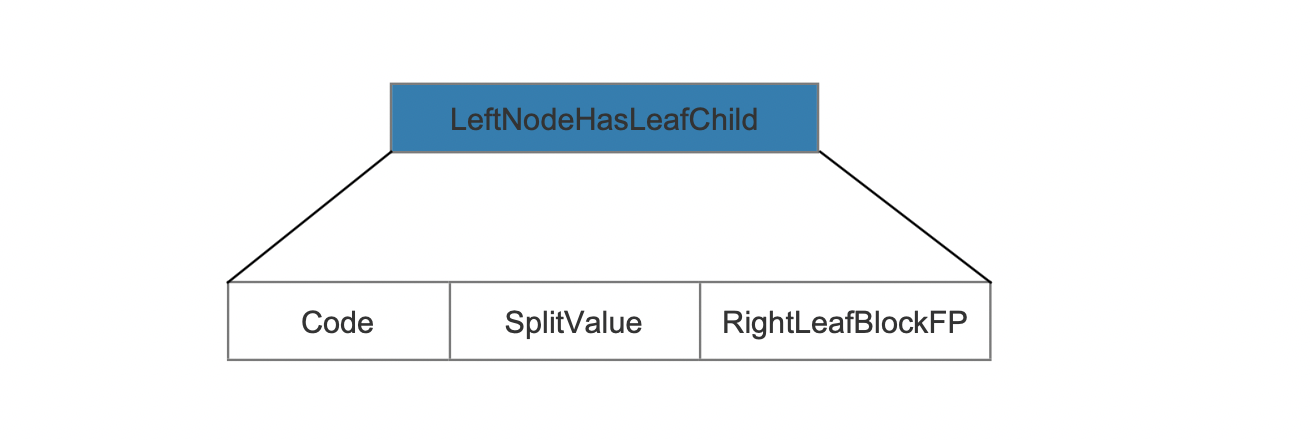
Fig.7
Code, SplitValue and RightLeafBlockFP describe the same meaning as above.
LeftNodeHasNotLeafChild

Fig.8
Code, SplitValue and LeftNumBytes describe the same meaning as above.
KD-tree and Index File
Inner node in a KD-tree would be stored in .kid file as blow:

Fig.9
Leaf node in a KD-tree would be stored in .kdd file as blow:

Fig.10
LeftNumBytes

Fig.11
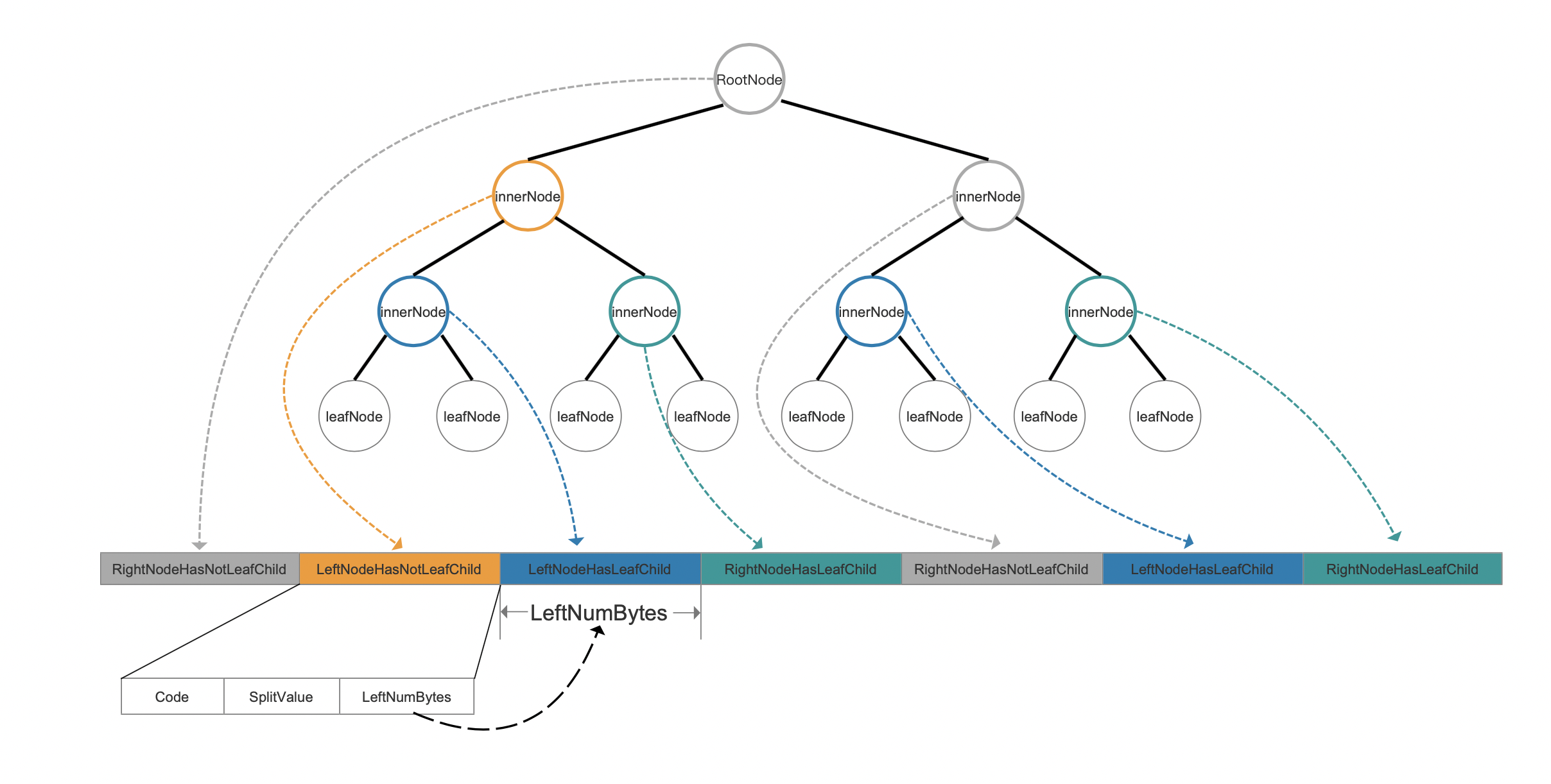
Fig.12
As above said, LeftNumBytes describes the total size of one inner node's left sub tree, it makes a reader can skip to the position of inner node's right node in .kid file and its left node is just in the next position.
LeftLeafBlockFP RightLeafBlockFP
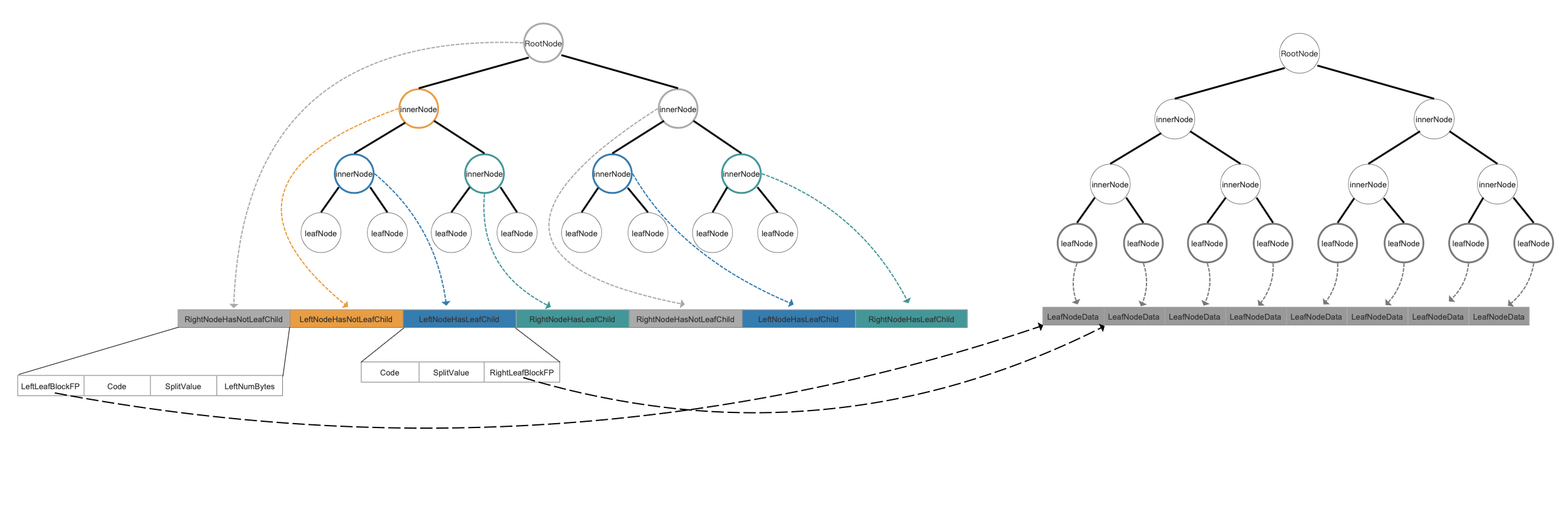
Fig.13

Fig.14
The data structure of .kdm file as below:

Fig.15
- 1
-1 is a fix padding value, In the stage of reading .kdm file, it as a mark means all the Fields has been read.
KdiFileLength KddFileLength
In the stage of reading .kdm index file , KdiFileLength and KddFileLength used to validate .kdi and .kdd files, such as truncated file or file too long.

Fig.16
FieldNumber
FieldNumber uniquely represents a Field.
Index
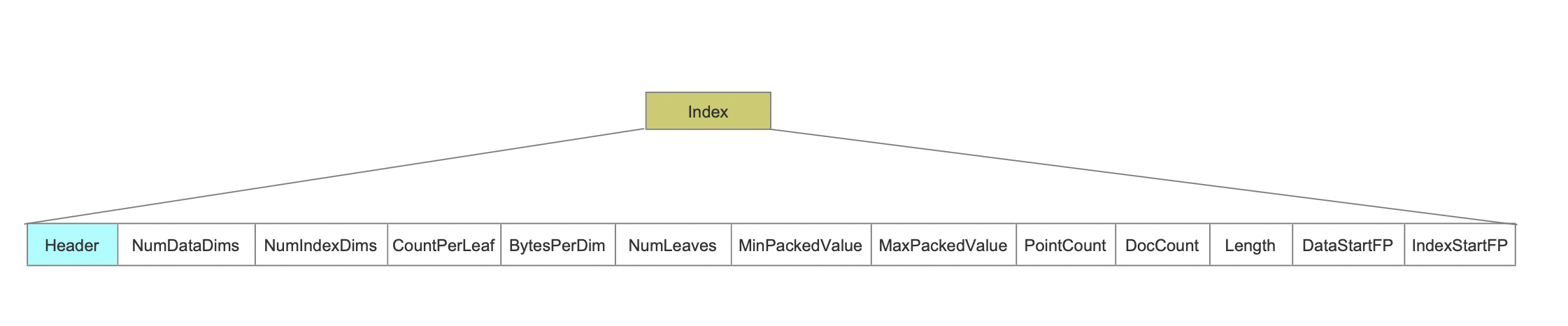
Fig.17
NumDataDims describes how many dimensions we are storing at the leaf (data) nodes.
NumIndexDims
NumIndexDims describes how many dimensions we are indexing in the internal nodes.
CountPerLeaf
CountPerLeaf describes the maximum number of points in each leaf node.
BytesPerDim
BytesPerDim describes the number of bytes per dimension.
NumLeaves
NumLeaves describes the number of leaf nodes.
MinPackedValue MaxPackedValue
MinPackedValue describes minimum value for each dimension and MaxPackedValue describes maximum value for each dimension values.
PointCount
PointCount describes the total number of indexed points across all documents.
DocCount
DocCount describes the total number of documents that have indexed at least one point.
Length
Length describes the size of PackedIndexValue in Fig.4.
DataStartFP
DataStartFP describes a pointer where the beginning position of current field data in .kdd file is.
IndexStartFP
IndexStartFP describes a pointer where the beginning position of current field data in .kdi file is.

Fig.18
Complete data structure

Fig.19
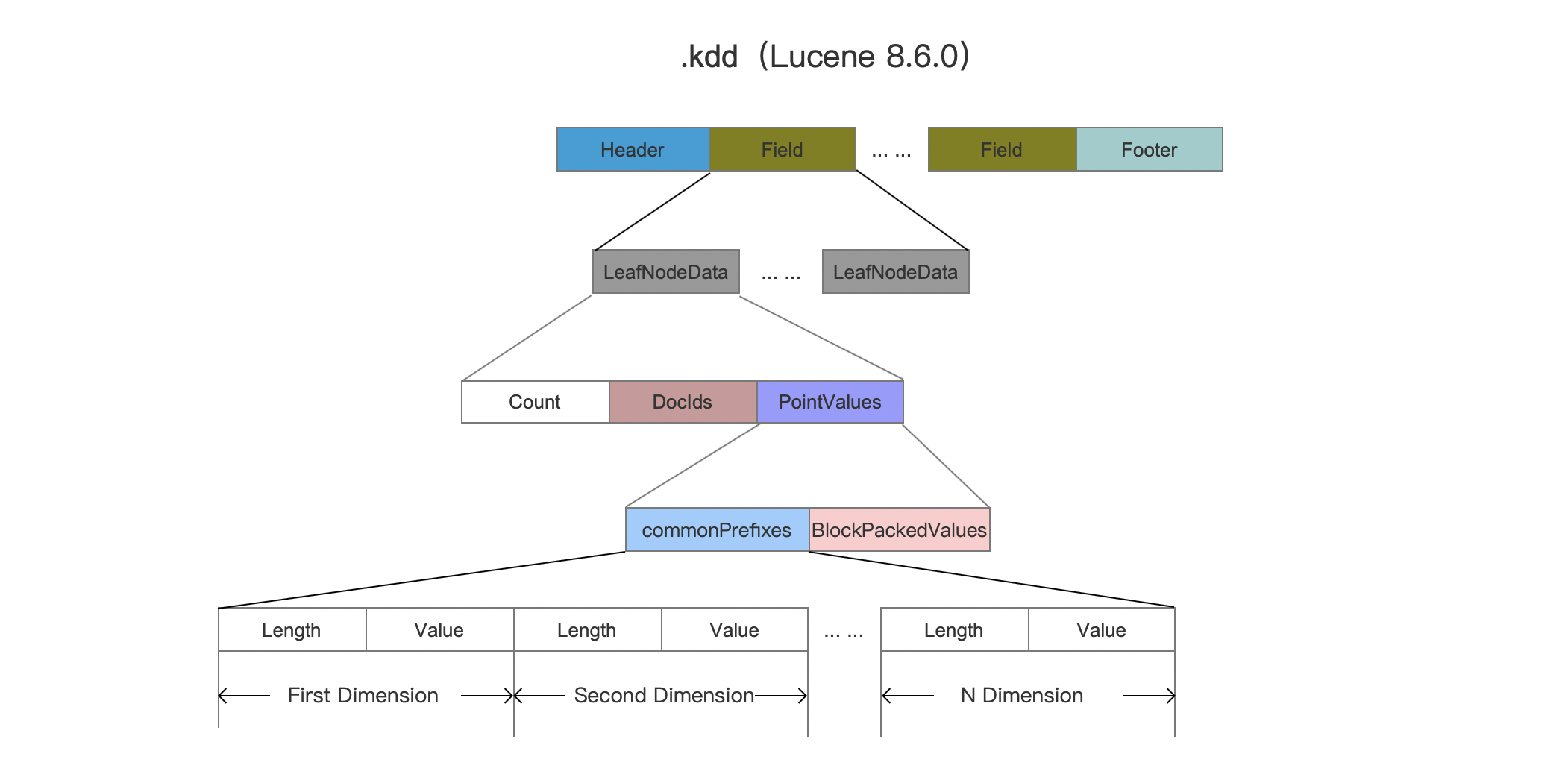
Fig.20

Fig.21