This page discusses the implementation of Flink's distributed communication via Akka, which has been adopted in version 0.9. With Akka, all remote procedure calls are now realized as asynchronous messages. This mainly affects the components JobManager, TaskManager and JobClient. In the future, it is likely that even more components will be transformed into an actor, allowing them to send and process asynchronous messages.
Akka and the Actor Model
Akka is a framework to develop concurrent, fault-tolerant and scalable applications. It is an implementation of the actor model and thus similar to Erlang's concurrency model. In the context of the actor model, all acting entities are considered independent actors. Actors communicate with other actors by sending asynchronous messages to each other. The strength of the actor model arises from this asynchronism. It is also possible to explicitly wait for a response which allows you to perform synchronous operations. Synchronous messages are strongly discouraged, though, because they limit the scalability of the system. Each actor has a mailbox in which the received messages are stored. Furthermore, each actor maintains its own isolated state. An example network of several actors is given below.
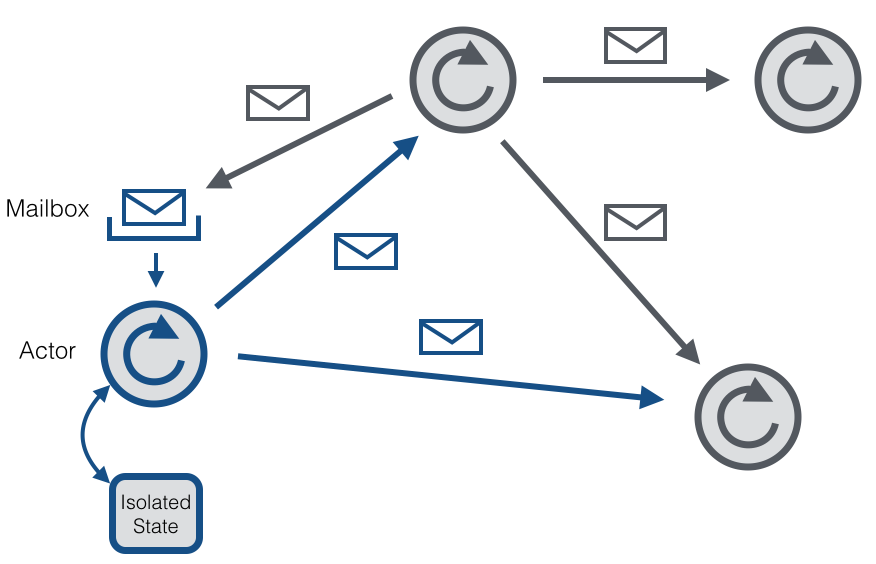
An actor has a single processing thread which polls the actor's mailbox and processes the received messages successively. As a result of a processed message, the actor can change its internal state, send new messages or spawn new actors. If the internal state of an actor is exclusively manipulated from within its processing thread, then there is no need to make the actor's state thread safe. Even though an individual actor is sequential by nature, a system consisting of several actors is highly concurrent and scalable, because the processing threads are shared among all actors. This sharing is also the reason why one should never call blocking calls from within an actor thread. Such a call would block the thread from being used by other actors to process their own messages.
Actor Systems
An actor system is the container in which all actors live. It provides shared services such as scheduling, configuration and logging. The actor system also contains the thread pool from where all actor threads are recruited.
Multiple actor system can coexist on a single machine. If the actor system is started with a RemoteActorRefProvider, then it can be reached from another actor system possibly residing on a remote machine. The actor system automatically recognises whether actor messages are addressed to an actor living in the same actor system or in a remote actor system. In case of local communication, the message is efficiently transmitted using shared memory. In case of remote communication, the message is sent through the network stack.
All actors are organized in a hierarchy. Each newly created actor gets its creating actor as parent assigned. The hierarchy is used for supervision. Each parent is responsible for the supervision of its children. If an error occurs in one of its children, then he gets notified. If the actor can resolve the problem, then he can resume or restart his child. In case of a problem which is out of his scope to deal with, he can escalate the error to his own parent. Escalating an error simply means that a hierarchy layer above the current one is now responsible for resolving the problem. Details about Akka's supervision and monitoring can be found here.
The first actors created by the system are supervised by the guardian actor /user which is provided by the system. The actor hierarchy is explained in depth here. For more information about actor systems in general look here.
Actors in Flink
An actor is itself a container for state and behaviour. It's actor thread sequentially processes the incoming messages. It alleviates the user from the error prone task of locking and thread management because only one thread at a time is active for one actor. However, one must make sure that the internal state of an actor is only accessed from this actor thread. The behaviour of an actor is defined by a receive function which contains for each message some logic which is executed upon receiving this message.
The Flink system consists of three distributed components which have to communicate: The JobClient, the JobManager and the TaskManager. The JobClient takes a Flink job from the user and submits it to the JobManager. The JobManager is then responsible for orchestrating the job execution. First of all, it allocates the required amount of resources. This mainly includes the execution slots on the TaskManagers.
After resource allocation, the JobManager deploys the individual tasks of the job to the respective TaskManagers Upon receiving a task, the TaskManager spawns a thread which executes the task. State changes such as starting the calculation or finishing it are sent back to the JobManager. Based on these state updates, the JobManager will steer the job execution until it is finished. Once the job is finished, the result of it will be sent back to the JobClient which tells the user about it. The job execution process is depicted in the figure below.

JobManager & TaskManager
The JobManager is the central control unit which is responsible for executing a Flink job. As such it governs the resource allocation, task scheduling and state reporting.
Before any Flink job can be executed, one JobManager and one or more TaskManager have to be started. The TaskManager then registers at the JobManager by sending a RegisterTaskManager message to the JobManager. The JobManager acknowledges a successful registration with an AcknowledgeRegistration message. In case that the TaskManager is already registered at the JobManager, because there were multiple RegisterTaskManager messages sent, an AlreadyRegistered message is returned by the JobManager. If the registration is refused, then the JobManager will respond with a RefuseRegistration message.
A job is submitted to the JobManager by sending a SubmitJob message with the corresponding JobGraph to it. Upon receiving the JobGraph, the JobManager creates an ExecutionGraph out of the JobGraph which serves as the logical representation of the distributed execution. The ExecutionGraph contains the information about the tasks which have to be deployed to the TaskManager in order to be executed.
The JobManager's scheduler is responsible for allocating execution slots on the available TaskManagers. After allocating an execution slot on a TaskManager, a SubmitTask message with all necessary information to execute the task is sent to the respective TaskManager. A successful task deployment is acknowledged by TaskOperationResult. Once the sources of the submitted job are deployed and running, also the job submission is considered successful. The JobManager informs the JobClient about this state by sending a Success message with the corresponding job id.
State updates of the individual task running on the TaskManagers are sent back to the JobManager via UpdateTaskExecutionState messages. With these update messages, the ExecutionGraph can be updated to reflect the current state of the execution.
The JobManager also acts as the input split assigner for data sources. It is responsible for distributing the work across all TaskManager such that data locality is preserved where possible. In order to dynamically balance the load, the Tasks request a new input split after they have finished processing the old one. This request is realized by sending a RequestNextInputSplit to the JobManager. The JobManager responds with a NextInputSplit message. If there are no more input splits, then the input split contained in the message is null.
The Tasks are deployed lazily to the TaskManagers. This means that tasks which consume data are only deployed after one of its producers has finished producing some data. Once the producer has done so, it sends a ScheduleOrUpdateConsumers message to the JobManager. This messages says that the consumer can now read the newly produced data. If the consuming task is not yet running, it will be deployed to a TaskManager.