In this page hierarchy, we explain the concepts, design and the overall architectural underpinnings of Apache Hudi. This content is intended to be the technical documentation of the project and will be kept up-to date with
"def~" annotations
In an effort to keep this page crisp for reading, any concepts that we need to explain are annotated with a def~ and hyperlinked off. You can contribute immensely to our docs, by writing the missing pages for annotated terms. These are marked in brown. Please mention any PMC/Committers on these pages for review.
Introduction
Apache Hudi (Hudi for short, here on) allows you to store vast amounts of data, on top existing def~hadoop-compatible-storage, while providing two primitives, that enable def~stream-processing on def~data-lakes, in addition to typical def~batch-processing.
Specifically,
- Update/Delete Records : Hudi provides support for updating/deleting records, using fine grained file/record level indexes, while providing transactional guarantees for the write operation. Queries process the last such committed snapshot, to produce results.
- Change Streams : Hudi also provides first-class support for obtaining an incremental stream of all the records that were updated/inserted/deleted in a given table, from a given point-in-time, and unlocks a new def~incremental-query category.

These primitives work closely hand-in-glove and unlock stream/incremental processing capabilities directly on top of def~DFS-abstractions. If you are familiar def~stream-processing, this is very similar to consuming events from a def~kafka-topic and then using a def~state-stores to accumulate intermediate results incrementally.
It has several architectural advantages.
- Increased Efficiency : Ingesting data often needs to deal with updates (resulting from def~database-change-capture), deletions (due to def~data-privacy-regulations) and enforcing def~unique-key-constraints (to ensure def~data-quality of event streams/analytics). However, due to lack of standardized support for such functionality using a system like Hudi, data engineers often resort to big batch jobs that reprocess entire day's events or reload the entire upstream database every run, leading to massive waste of def~computational-resources. Since Hudi supports record level updates, it brings an order of magnitude improvement to these operations, by only reprocessing changes records and rewriting only the part of the def~table, that was updated/deleted, as opposed to rewriting entire def~table-partitions or even the entire def~table.
- Faster ETL/Derived Pipelines : An ubiquitous next step, once the data has been ingested from external sources is to build derived data pipelines using Apache Spark/Apache Hive or any other data processing framework to def~ETL the ingested data for a variety of use-cases like def~data-warehousing, def~machine-learning-feature-extraction, or even just def~analytics. Typically, such processes again rely on def~batch-processing jobs expressed in code or SQL, that process all input data in bulk and recompute all the output results. Such data pipelines can be sped up dramatically, by querying one or more input tables using an def~incremental-query instead of a regular def~snapshot-query, resulting once again in only processing the incremental changes from upstream tables and then def~upsert or delete the target derived table, like above.
- Access to fresh data : It's not everyday, that you will find that reduced resource usage also result in improved performance, since typically we add more resources (e.g memory) to improve performance metric (e.g query latency) . By fundamentally shifting away from how datasets have been traditionally managed for may be the first time since the dawn of the big data era, Hudi, in fact, realizes this rare combination. A sweet side-effect of incrementalizing def~batch-processing is that the pipelines also much much smaller amount of time to run, putting data into hands of organizations much much quickly, than it has been possible with def~data-lakes before.
- Unified Storage : Building upon all the three benefits above, faster and lighter processing right on top of existing def~data-lakes mean lesser need for specialized storage or def~data-marts, simply for purposes of gaining access to near real-time data.
Design Principles
Streaming Reads/Writes : Hudi is designed, from ground-up, for streaming records in and out of large datasets, borrowing principles from database design. To that end, Hudi provides def~index implementations, that can quickly map a record's key to the file location it resides at. Similarly, for streaming data out, Hudi adds and tracks record level metadata via def~hoodie-special-columns, that enables providing a precise incremental stream of all changes that happened.
Self-Managing : Hudi recognizes the different expectation of data freshness (write friendly) vs query performance (read/query friendliness) users may have, and supports three different def~query-types that provide real-time snapshots, incremental streams or purely columnar data that slightly older. At each step, Hudi strives to be self-managing (e.g: autotunes the writer parallelism, maintains file sizes) and self-healing (e.g: auto rollbacks failed commits), even if it comes at cost of slightly additional runtime cost (e.g: caching input data in memory to profile the workload). The core premise here, is that, often times operational costs of these large data pipelines without such operational levers/self-managing features built-in, dwarf the extra memory/runtime costs associated.
Everything is a log : Hudi also has an append-only, cloud data storage friendly design, that lets Hudi manage data on across all the major cloud providers seamlessly, implementing principles from def~log-structured-storage systems.
key-value data model : On the writer side, Hudi table is modeled as a key-value dataset, where each def~record has a unique def~record-key. Additionally, a record key may also include the def~partitionpath under which the record is partitioned and stored. This often helps in cutting down the search space during index lookups.
Table Layout
With an understanding of key technical motivations for the projects, let's now dive deeper into design of the system itself. At a high level, components for writing Hudi tables are embedded into an Apache Spark job using one of the supported ways and it produces a set of files on def~backing-dfs-storage, that represents a Hudi def~table. Query engines like Apache Spark, Presto, Apache Hive can then query the table, with certain guarantees (that will discuss below).
There are three main components to a def~table
- Ordered sequence of def~timeline-metadata about all the write operations done on the table, akin to a database transaction log.
- A hierarchical layout of a set of def~data-files that actually contain the records that were written to the table.
- An def~index (which could be implemented in many ways), that maps a given record to a subset of the data-files that contains the record.

Hudi provides the following capabilities for writers, queries and on the underlying data, which makes it a great building block for large def~data-lakes.
- upsert() support with fast, pluggable indexing
- Incremental queries that scan only new data efficiently
- Atomically publish data with rollback support, Savepoints for data recovery
- Snapshot isolation between writer & queries using def~mvcc style design
- Manages file sizes, layout using statistics
- Self managed def~compaction of updates/deltas against existing records.
- Timeline metadata to audit changes to data
- GDPR, Data deletions, Compliance.
Timeline
At its core, Hudi maintains a timeline of all def~instant-action performed on the def~table at different instants of time that helps provide instantaneous views of the def~table, while also efficiently supporting retrieval of data in the order in which it was written. The timeline is akin to a redo/transaction log, found in databases, and consists of a set of def~timeline-instants. Hudi guarantees that the actions performed on the timeline are atomic & timeline consistent based on the instant time. Timeline is implemented as a set of files under the `.hoodie` def~metadata-folder directly under the def~table-basepath. Specifically, while the most recent instants are maintained as individual files, the older instants are archived to the def~timeline-archival folder, to bound the number of files, listed by writers and queries.
A Hudi `timeline instant` consists of the following components
- def~instant-action: Type of action performed on the def~table
- def~instant-time: typically a timestamp (e.g: 20190117010349), which monotonically increases in the order of action’s begin time.
- instant state: current state of the def~timeline
- Each instant also has metadata either in avro or json format, that describes in detail the state of the action, at its state on that instant time
Key Instant action types performed include:COMMITS - `action type` which denotes an atomic write of a batch of records into a def~table (see def~commit).CLEANS - `action type` which denotes a background activity that gets rid of older versions of files in the def~table, that are no longer needed.DELTA_COMMIT - `action type` which denotes an atomic write of a batch of records into a def~merge-on-read (MOR) def~table-type of def~table, where some/all of the data could be just written to delta logs (see def~commit).COMPACTION - `action type` which denotes a background activity to reconcile differential data structures within Hudi e.g: merging updates from delta log files onto def~base-files columnar file formats. Internally, compaction manifests as a special def~commit on the timeline (see def~timeline)ROLLBACK - `action type` denotes that a def~timeline of `instant action type` commit/delta commit was unsuccessful & rolled back, removing any partial files produced during such a writeSAVEPOINT - `action type` marks certain file groups as “saved”, such that cleaner will not delete them. It helps restore the def~table to a point on the timeline, in case of disaster/data recovery scenarios.
Any given instant can be in one of the following states:
REQUESTED- Denotes an action has been scheduled, but has not initiatedINFLIGHT- Denotes that the action is currently being performedCOMPLETED- Denotes completion of an action on the timeline
Data Files
Hudi organizes a table into a folder structure under a def~table-basepath on DFS. If the table is partitioned by some columns, then there are additional def~table-partitions under the base path, which are folders containing data files for that partition, very similar to Hive tables. Each partition is uniquely identified by its def~partitionpath, which is relative to the basepath. Within each partition, files are organized into def~file-groups, uniquely identified by a def~file-id. Each file group contains several def~file-slices, where each slice contains a def~base-file (e.g: parquet) produced at a certain commit/compaction def~instant-time, along with set of def~log-files that contain inserts/updates to the base file since the base file was last written. Hudi adopts a MVCC design, where compaction action merges logs and base files to produce new file slices and cleaning action gets rid of unused/older file slices to reclaim space on DFS.
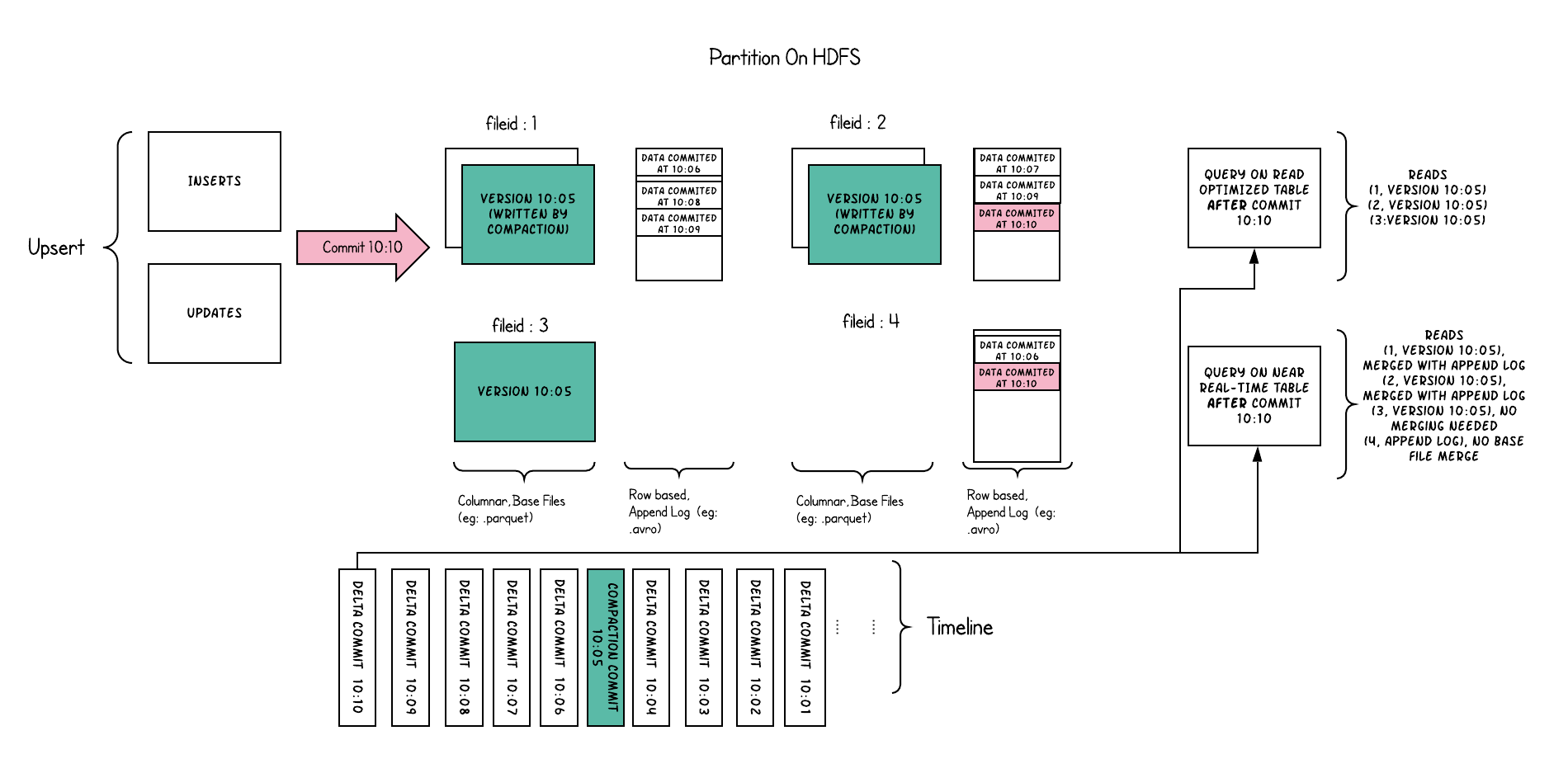 Fig : Shows four file groups 1,2,3,4 with base and log files, with few file slices each
Fig : Shows four file groups 1,2,3,4 with base and log files, with few file slices each
Index
Hudi provides efficient upserts, by mapping a def~record-key + def~partition-path combination consistently to a def~file-id, via an indexing mechanism. This mapping between record key and file group/file id, never changes once the first version of a record has been written to a file group. In short, the mapped file group contains all versions of a group of records. Hudi currently provides two choices for indexes : def~bloom-index and def~hbase-index, (with a few in the works :
HUDI-466
-
Getting issue details...
STATUS
,
HUDI-407
-
Getting issue details...
STATUS
) to map a record key into the file id to which it belongs to. This enables us to speed up upserts significantly, without scanning over every record in the table. Hudi Indices can be classified based on their ability to lookup records across partition.
Table Types
The implementation specifics of the two def~table-types are detailed below.
Copy On Write Table
A def~table-type where a def~table's def~commits are fully merged into def~table during a def~write-operation. This can be seen as "imperative ingestion", "compaction" of the happens right away. No def~log-files are written and def~file-slices contain only def~base-file. (e.g a single parquet file constitutes one file slice) The Spark DAG for this storage, is relatively simpler. The key goal here is to group the tagged Hudi record RDD, into a series of updates and inserts, by using a partitioner. To achieve the goals of maintaining file sizes, we first sample the input to obtain a workload profile that understands the spread of inserts vs updates, their distribution among the partitions etc. With this information, we bin-pack the records such that Any remaining records after that, are again packed into new file id groups, again meeting the size requirements.

Merge On Read Table
In this def~table-type, records written to the def~table, are quickly first written to def~log-files, which are at a later time merged with the def~base-file, using a def~compaction action on the timeline. Various def~query-types can be supported depending on whether the query reads the merged snapshot or the change stream in the logs or the un-merged base-file alone. At a high level, def~merge-on-read (MOR) writer goes through same stages as def~copy-on-write (COW) writer in ingesting data. The updates are appended to latest log (delta) file belonging to the latest file slice without merging. For inserts, Hudi supports 2 modes: As in the case of def~copy-on-write (COW), the input tagged records are partitioned such that all upserts destined to a def~file-id are grouped together. This upsert-batch is written as one or more log-blocks written to def~log-files. Hudi allows clients to control log file sizes. The WriteClient API is same for both def~copy-on-write (COW) and def~merge-on-read (MOR) writers. With def~merge-on-read (MOR), several rounds of data-writes would have resulted in accumulation of one or more log-files. All these log-files along with base-parquet (if exists) constitute a def~file-slice which represents one complete version of the file. This table type is the most versatile, highly advanced and offers much flexibility for writing (ability specify different compaction policies, absorb bursty write traffic etc) and querying (e.g: tradeoff data freshness and query performance). At the same time, it can involve a learning curve for mastering it operationally.

Writing
Write Operations
It may be helpful to understand the 3 different write operations provided by Hudi datasource or the delta streamer tool and how best to leverage them. These operations can be chosen/changed across each commit/deltacommit issued against the dataset.
- def~upsert-operation: This is the default operation where the input records are first tagged as inserts or updates by looking up the index and the records are ultimately written after heuristics are run to determine how best to pack them on storage to optimize for things like file sizing. This operation is recommended for use-cases like database change capture where the input almost certainly contains updates.
- def~insert-operation: This operation is very similar to upsert in terms of heuristics/file sizing but completely skips the index lookup step. Thus, it can be a lot faster than upserts for use-cases like log de-duplication (in conjunction with options to filter duplicates mentioned below). This is also suitable for use-cases where the dataset can tolerate duplicates, but just need the transactional writes/incremental pull/storage management capabilities of Hudi.
- def~bulk-insert-operation Both upsert and insert operations keep input records in memory to speed up storage heuristics computations faster (among other things) and thus can be cumbersome for initial loading/bootstrapping a Hudi dataset at first. Bulk insert provides the same semantics as insert, while implementing a sort-based data writing algorithm, which can scale very well for several hundred TBs of initial load. However, this just does a best-effort job at sizing files vs guaranteeing file sizes like inserts/upserts do.
Compaction
Compaction is a def~instant-action, that takes as input a set of def~file-slices, merges all the def~log-files, in each file slice against its def~base-file, to produce a new compacted file slices, written as a def~commit on the def~timeline. Compaction is only applicable for the def~merge-on-read (MOR) table type and what file slices are chosen for compaction is determined by a def-compaction-policy (default: chooses the file slice with maximum sized uncompacted log files) that is evaluated after each def~write-operation. At a high level, there are two styles of compaction
Cleaning
Cleaning is an essential def~instant-action, performed for purposes of deleting old def~file-slices and bound the growth of storage space consumed by a def~table. Cleaning is performed automatically and right after each def~write-operation and leverages the timeline metadata cached on the timeline server to avoid scanning the entire def~table to evaluate opportunities for cleaning. There are two styles of cleaning supported. Additionally, cleaning ensures that there is always 1 file slice (the latest slice) retained in a def~file-group.
Optimized DFS Access
Hudi also performs several key storage management functions on the data stored in a def~table. A key aspect of storing data on DFS is managing file sizes and counts and reclaiming storage space. For e.g HDFS is infamous for its handling of small files, which exerts memory/RPC pressure on the Name Node and can potentially destabilize the entire cluster. In general, query engines provide much better performance on adequately sized columnar files, since they can effectively amortize cost of obtaining column statistics etc. Even on some cloud data stores, there is often cost to listing directories with large number of small files.
Here are some ways, Hudi writing efficiently manages the storage of data.
- The small file handling feature in Hudi, profiles incoming workload and distributes inserts to existing def~file-group instead of creating new file groups, which can lead to small files.
- Employing a cache of the def~timeline, in the writer such that as long as the spark cluster is not spun up everytime, subsequent def~write-operations never list DFS directly to obtain list of def~file-slices in a given def~table-partition
- User can also tune the size of the def~base-file as a fraction of def~log-files & expected compression ratio, such that sufficient number of inserts are grouped into the same file group, resulting in well sized base files ultimately.
- Intelligently tuning the bulk insert parallelism, can again in nicely sized initial file groups. It is in fact critical to get this right, since the file groups once created cannot be deleted, but simply expanded as explained before.
Querying
Given such flexible and comprehensive layout of data and rich def~timeline, Hudi is able to support three different ways of querying a def~table, depending on its def~table-typeQuery Type def~copy-on-write (COW) def~merge-on-read (MOR) Snapshot Query Query is performed on the latest def~base-files across all def~file-slices in a given def~table or def~table-partition and will see records written upto the latest def~commit action. Query is performed by merging the latest def~base-file and its def~log-files across all def~file-slices in a given def~table or def~table-partition and will see records written upto the latest def~delta-commit action. Incremental Query Query is performed on the latest def~base-file, within a given range of start , end def~instant-times (called the incremental query window), while fetching only records that were written during this window by use of the def~hoodie-special-columns Query is performed on a latest def~file-slice within the incremental query window, using a combination of reading records out of base or log blocks, depending on the window itself. Read Optimized Query Same as snapshot query Only access the def~base-file, providing data as of the last def~compaction action performed on a given def~file-slice. In general, guarantees of how fresh/upto date the queried data is, depends on def~compaction-policy 
Snapshot Queries
Queries see the latest snapshot of def~table as of a given delta commit or commit def~instant-action.; In case of def~merge-on-read (MOR) table, it provides near-real time def~tables (few mins) by merging the base and delta files of the latest file slice on-the-fly. For def~copy-on-write (COW), it provides a drop-in replacement for existing parquet tables (or tables of same def~base-file type), while providing upsert/delete and other write side features.
Incremental Queries
Queries only see new records written to the def~table, since a given commit /delta-commit def~instant-action; effectively provides change streams to enable incremental data pipelines.
Read Optimized Queries
Queries see the latest snapshot of the def~table as of a given commit / compaction def~instant-action; exposes only the base / columnar files in latest file slices to the queries and guarantees the same columnar query performance compared to a non-hudi columnar def~table. Following table summarizes the trade-offs between the different def~query-types.Trade-off def~read-optimized-query def~snapshot-query Data Latency Higher Lower Query Latency Lower (raw base / columnar file performance) Higher (merge base / columnar file+ row based delta/log files)
8 Comments
Shaofeng Li
The pics are broken.(e.g: {% include image.html file="hudi_log_format_v2.png" alt="hudi_log_format_v2.png" max-width="1000" %}, {% include image.html file="async_compac_1.png" alt="async_compac_1.png" max-width="1000" %}). Would you please fix it? Vinoth Chandar
Vinoth Chandar
This page is still WIP.. queued up on my lst. thanks for all the careful reviews!
Zheng Hu
Vinoth Chandar any thoughts to attach the correct pictures ? seems we still can not see the pictures. Thanks.
HKB
Thank you for the document. This helped a lot to get a good insight into the architecture of Hudi. However, all the "def~" makes it very hard to read. Most other documentation on the internet use only links whenever necessary, and that makes it easier to read.
Vinoth Chandar
thanks. somebody thought me that annotation on the community. seemed like a good idea back then. feel free to edit/correct
HKB
I would be happy to. I do not have access. Can you add me?
Vinoth Chandar
you should have access now!
HKB
Feel free to sue these guys for copying your article: