
under reconsideration
This design, though valid is ignoring the rising use of tools like oasis camp and tosca, as well as the more propriatary format of terraform. Embedding or co-installing Apache Brooklyn with CloudStack for the use of creating application landscapes seems more appropriate.
Introduction
ApplicationClusters (or AppC, pronounce appz) are an attempt to make orchestrating bigger application landscapes easier in a vanilla Apache CloudStack install.
Services like Kubernetes, Cloud Foundry, DBaaS require integration support from underlying CloudStack. This support includes Grouping Vms, Scaling, Monitoring. Rather than making changes every time to support various services in ACS, a generic framework has to be developed.
As an example container technologies are gaining quite a momentum and changing the way how application are traditionally deployed in the public and private clouds. Gaining interest in micro services based architecture is also fostering adoption of container technologies. Much like how cloud orchestration platforms enable the provisioning of VMs and adjacent services, container orchestration platforms like Kubernetes [3], docker swarm [1], mesos [2] are emerging to enable orchestration of containers. Container orchestration platforms typically can be run any where and be used to provision containers. A popular choice of running containers has been running them on the IaaS provisioned VMs. AWS and GCE provide native functionality to launch containers abstracting out the underlying consumption of VMs. A container orchestration platform can be provisioned on top of CloudStack using development tools, (see [6]), but they are not an out of the box solution. Given the momentum of container technologies, micro-services etc it make sense to provide a native functionality in CloudStack which is available out-of-the-box for users.
Another example are DBaaS installations. These have different sets of roles then the above mentioned container services with different number of nodes in each role. Those two have usually only two roles but for instance sdn solutions might have three roles; switch-, controlplane- and configuration-machines.
Apache Cloudstack should not involve itself with how virtual machines are used, though plugins for CloudStack might be written that do configure sets of VMs for certain uses (like kubernetes in [8]). The intention of this functionality is to provide the organisation of sets of VMs with roles to be used as a single application, be it a container cluster or a database or a SDN facility.
Purpose
Purpose of this document is present the functional requirements for supporting generic vm cluster service functionality in CloudStack
Glossary
Node - Vm in CloudStack
Application cluster - a managed group of VMs in CloudStack
DBaaS - Database as a Service
IaaS - Infrastructure as a service
PaaS - Platform as a service
Functional specification
Application Cluster
CloudStack VM cluster service shall introduce the notion of application cluster. A 'application cluster' shall be first class CloudStack entity that will be a composite of existing CloudStack entities like virtual machines, network, network rules etc.
The application cluster service shall stitch together cluster resources. Any enhancements or plugins can call it to do further deploys of the chosen cluster application like a manager and nodes in Kubernetes, Mesos, docker swarm etc, to provide the manager's service type, like AWS ECS, Google container service etc to the CloudStack users.
Cluster life-cycle management
Container service shall provide following container cluster life-cycle operations.
- create application cluster: provision cluster resources, and brings the cluster in to operational readiness state. Resources provisioning shall be the responsibility of the caller, that can act according to the cluster manager used. All the cluster VM's shall be launched in to a dedicated network for the cluster. API end point of cluster manager can be exposed by the caller through creating a port forwarding rule on source nat ip of the network dedicated for the cluster.
- delete application cluster: destroy all the resources provisioned for the application cluster. Post delete, a application cluster can not be performed any operations on it.
- start application cluster: Starting a cluster will start the VMs and possibly start the network.
- stop application cluster: Stopping a cluster will shutdown all the resources consumed by the application cluster. User can start the cluster at a later point with Start operation.
- recovering a cluster: Due to possible faults (like VMs that got stopped due to failures, or malfunctioning cluster manager etc) application cluster can end up in Alert state. Recover is used to revive application cluster to a sane running state. In the initial version this is just trying to have the correct number of VMs per role. In later versions callbacks for (re-)provisioning may be added.
- cluster resizing (scale-in/out): increase or decrease the size of the cluster on a per role basis. The functionality here is adhering to the same limitations as stated above under recovering.
- list application cluster: list all the application clusters
provisioning service orchestrator
The provisioning of the service is out of scope for the application cluster. A calling plugin or external tool add value by calling, as part of its creation plan, any setting up of a control plane of the service type that was chosen. How a service will be setup is dependent on the chosen service type.
Design
API changes
Following API shall be introduced with application cluster:
- createApplicationCluster
- name: name of the application cluster
- description: description of application cluster
- type: service type - Kubernetes, CloudFoundry, Mesos etc
- zoneid: uuid of the zone in which application cluster will be provisioned
- a list of
- role: the name for this type of VM
- priority: used for starting order, lower numbers will be started sooner. As default the order (times ten) will be used.
- serviceofferingid: service offering with which cluster VMs of this role shall be provisioned
- template: the template to use for VMs of this role
- count: size of the cluster or number of VMs of this role to be provisioned
- accountname: account for which application cluster shall be created
- domainid: domain of the account for which application cluster shall be created
- networkid: uuid of the network in to which application cluster VM's will be provisioned. If not specified cluster service shall provision a new isolated network with default isolated network offering with source nat service.
- deleteApplicationCluster
- id: uuid of application cluster
- startApplicationCluster
- id: uuid of application cluster
- stopApplicationCluster
- id: uuid of application cluster
- increaseRoleCount
- id: uuid of application cluster
- role: the name for the type of node to be added
- decreaseRoleCount
- id: uuid of application cluster
- role: the name of the role for which to remove a node
- listApplicationClusters
- id: uuid of application cluster
- name: (part of) the name of the clusters
- listClusterNodes
- id: uuid of application cluster
New reponse 'applicationclusterreponse' shall be added with below details:
- name
- description
- zoneid
- list of
- role
- priority
- serviceofferingid
- templateid
- size
- networkid
suggested k8 extension response field - endpoint: URL of the application cluster manger API server endpoint
Life cycle operations
Each of the life cycle operation is a workflow resulting in either provisioning or deleting multiple CloudStack resources. There is no guarantee a workflow of a life cycle operation will succeed due to the lack of a two-phase-commit model, by means of resource reservation followed by provisioning semantics. Also there is no guarantee of a rollback succeeding. For instance, while provisioning a cluster of 10 VMs, deployment may run out of capacity to provision any more VMs after provisioning the first five Vms. In which case as rollback action, the provisioned VMs can be destroyed. But there can be cases where deleting a provisioned VM is not possible temporarily. For instance when a host is disconnected etc. So its not possible to achieve strong consistency and this will not be a focus in this phase of the development.
Below approach is followed while performing life cycle operations..
- A best effort will be done to bring the cluster up to spec. If this failed it will be retried indefinitely.
- If deployment fails it is the responsibility of the user to stop and destroy the cluster.
The below state machine reflects how a application cluster state transitions for each of life cycle operations
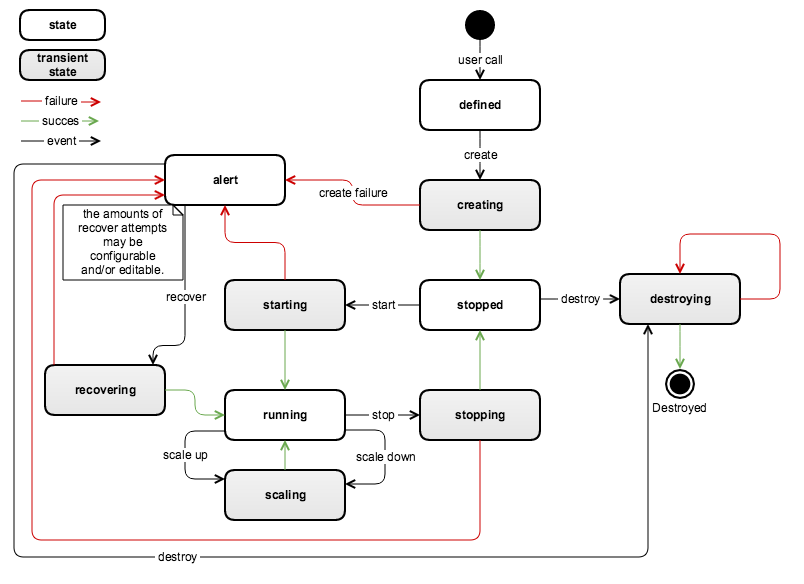
Garbage collection
Garbage collection shall be implemented as a way to clean up the resources of application cluster, as a background task. Following are cases where cluster resources are freed up.
- Starting application cluster fails, resulting in clean up of the provisioned resources (Starting → Expunging → Destroyed)
- Deleting application cluster (Stopped→ Expunging → Destroyed and Alert→ Expunging → Destroyed )
If there are failures in cleaning up resources, and clean up can not proceed, the state of the application cluster is marked as 'Expunge' instead of 'Expunging'. The garbage collector will loop through the list of application clusters in 'Expunge' state periodically and try to free the resources held by application cluster.
Cluster state synchronization
State of the application cluster is 'desired state' of the cluster as intended by the user or what the system's logical view of the application cluster. However there are various scenarios where desired state of the application cluster is not sync with state that can be inferred from actual physical/infrastructure. For e.g a application cluster in 'Running' state with cluster size of 10 VM's all in running state. Its possible due to host failures, some of the VM's may get stopped at later point. Now the desired state of the application cluster is a cluster with 10 VM's running and in operationally ready state, but the resource layer is state is different. So we need a mechanism to ensure:
- cluster is in desired state at resource/infrastructure layer. Which could mean provision new VM's or delete VM's, in the cluster etc to ensure desired state of the application cluster
- Conversely when reconciliation can not happen reflect the state of the cluster accordingly, and to recover at later point.
Following mechanism will be implemented.
- A state 'Alert' will be maintained that application cluster is not in its desired state.
- A state synchronization background task will run periodically to infer if the cluster is in desired state. If not cluster will marked as alert state.
- A recovery action try to recover the cluster
State transitions in FSM, where a application cluster ends up in 'Alert' state:
- failure in middle of scale in/out, resulting in cluster size (# of VM's) not equal to the expected
- failure in stopping a cluster, leaving some VM's to be running state
- Difference of states as detected by the state synchronization thread.
example provisioning kubernetes container cluster manager
Core OS template shall be used to provision container cluster VM. Setting up a cluster VM as master/node of kubernetes is done through cloud-config script [7] in CoreOS. CloudStack shall pass necessary cloud config script as base 64 encoded user data. Once Core OS instances are launched by CloudStack, by virtue of cloud-config data passed as user data, core OS instances self-configures as kubernetes master and node VM's
schema changes
CREATE TABLE IF NOT EXISTS `cloud`.`application_cluster` (
`id` bigint unsigned NOT NULL auto_increment COMMENT 'id',
`uuid` varchar(40),
`name` varchar(255) NOT NULL,
`description` varchar(4096) COMMENT 'display text for this application cluster',
`zone_id` bigint unsigned NOT NULL COMMENT 'zone id',
`network_id` bigint unsigned COMMENT 'network this application cluster uses',
`account_id` bigint unsigned NOT NULL COMMENT 'owner of this cluster',
`domain_id` bigint unsigned NOT NULL COMMENT 'owner of this cluster',
`state` char(32) NOT NULL COMMENT 'current state of this cluster',
`key_pair` varchar(40),
`created` datetime NOT NULL COMMENT 'date created',
`removed` datetime COMMENT 'date removed if not null',
`gc` tinyint unsigned NOT NULL DEFAULT 1 COMMENT 'gc this application cluster or not',
`network_cleanup` tinyint unsigned NOT NULL DEFAULT 1 COMMENT 'true if network needs to be clean up on deletion of application cluster. Should be false if user specfied network for the cluster',
CONSTRAINT `fk_cluster__zone_id` FOREIGN KEY `fk_cluster__zone_id` (`zone_id`) REFERENCES `data_center` (`id`) ON DELETE CASCADE,
CONSTRAINT `fk_cluster__network_id` FOREIGN KEY `fk_cluster__network_id`(`network_id`) REFERENCES `networks`(`id`) ON DELETE CASCADE,
PRIMARY KEY(`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS `cloud`.`application_cluster_role` (
`id` bigint unsigned NOT NULL auto_increment COMMENT 'id',
`cluster_id` bigint unsigned NOT NULL COMMENT 'cluster id',
`name` varchar(255) NOT NULL COMMENT 'role name',
`service_offering_id` bigint unsigned COMMENT 'service offering id for the cluster VM',
`template_id` bigint unsigned COMMENT 'vm_template.id',
`node_count` bigint NOT NULL default '0',
PRIMARY KEY(`id`),
CONSTRAINT `fk_cluster__service_offering_id` FOREIGN KEY `fk_cluster__service_offering_id` (`service_offering_id`) REFERENCES `service_offering`(`id`) ON DELETE CASCADE,
CONSTRAINT `fk_cluster__template_id` FOREIGN KEY `fk_cluster__template_id`(`template_id`) REFERENCES `vm_template`(`id`) ON DELETE CASCADE,
CONSTRAINT `application_cluster_role_cluster__id` FOREIGN KEY `application_cluster_role_cluster__id`(`cluster_id`) REFERENCES `application_cluster`(`id`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS `cloud`.`application_cluster_role_vm_map` (
`id` bigint unsigned NOT NULL auto_increment COMMENT 'id',
`role_id` bigint unsigned NOT NULL COMMENT 'role id',
`vm_id` bigint unsigned NOT NULL COMMENT 'vm id',
PRIMARY KEY(`id`),
CONSTRAINT `application_cluster_role_vm_map_cluster_role__id` FOREIGN KEY `application_cluster_role_vm_map_cluster_role__id`(`role_id`) REFERENCES `application_cluster_role`(`id`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS `cloud`.`application_cluster_details` (
`id` bigint unsigned NOT NULL auto_increment COMMENT 'id',
`cluster_id` bigint unsigned NOT NULL COMMENT 'cluster id',
`key` varchar(255) NOT NULL,
`value` text,
PRIMARY KEY(`id`),
CONSTRAINT `application_cluster_details_cluster__id` FOREIGN KEY `application_cluster_details_cluster__id`(`cluster_id`) REFERENCES `application_cluster`(`id`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS `cloud`.`application_cluster_role_details` (
`id` bigint unsigned NOT NULL auto_increment COMMENT 'id',
`role_id` bigint unsigned NOT NULL COMMENT 'role id',
`key` varchar(255) NOT NULL,
`value` text,
PRIMARY KEY(`id`),
CONSTRAINT `application_cluster_role_details_role__id` FOREIGN KEY `application_cluster_role_details_cluster__id`(`role_id`) REFERENCES `application_cluster_role`(`id`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
// example details for a cluster used as a k8 container cluster:
enum {
`username`,
`password`,
`registry_username`,
`registry_password`,
`registry_url`,
`registry_email`,
`endpoint` varchar(255) COMMENT 'url endpoint of the application cluster manager api access',
`console_endpoint` varchar(255) COMMENT 'url for the application cluster manager dashbaord',
`cores` bigint unsigned NOT NULL COMMENT 'number of cores',
`memory` bigint unsigned NOT NULL COMMENT 'total memory'
};
References
[1] https://www.docker.com/products/docker-swarm
[2] https://mesosphere.github.io/marathon/
[4] https://aws.amazon.com/ecs/
[5] https://cloud.google.com/container-engine/
[6] https://cloudierthanthou.wordpress.com/2015/10/23/apache-mesos-and-kubernetes-on-apache-cloudstack/
[7] https://github.com/kubernetes/kubernetes/tree/master/cluster/rackspace/cloud-config
Overview
Content Tools
Apps
4 Comments
Kishan Kavala
machine_cluster_details can be a simple name-value table like other details tables in cloudstack (user_vm_details, host_details)
Daan
good remark, Kishan. I'll go ahead now and put this on the backlog
Daan
At the moment this service is geared towards a single master and a definable set of nodes as used by kubernetes. in practice that is not the only configuration this will be useful for in fact it will be only a minority of use cases that adhere to this topology.
The design needs to include a notion of node type including offering, template and number to be useful.
Per node a number of configuration templates with target locations need to be filled. This may be done by defining a configuration script or by a list of configuration templates.
Wido den Hollander
Looks good! I would just try to avoid to make it to container specific. While it doesn't seem that way right now just mentioning it.
A use-case I see is 3-node MariaDB Galera clusters for example. They all need to be group together. No need for a master node, just 3 VMs running with Linux + MariaDB in there.
Would make a excellent use-case for this. Using the API tooling can figure out which three nodes to use and bootstrap them.
Or a 3-node Consul cluster, 3-node Nomad (Containers as well). All kinds of interesting things can be done.