
The information here will be of interest to people looking to understand, improve and replicate Apache CloudStack test infrastructure across sites.
About
This document talks about the continuously evolving test infrastructure used to setup, deploy, configure, and test Apache CloudStack. Information here is useful for anyone involved in build, test and continuous integration.
Deployment Architecture
The following diagram shows a small representation of the deployed test environment. The test environment is switched through various network models supported by cloudstack over the course of the tests. One can also control the underlying hypervisor providing compute power to the cloud. This is a general proof-of-concept and does not necessarily represent the true state of the system at any point. The infrastructure keeps evolving and adapting to CloudStack's features and bug fixes.
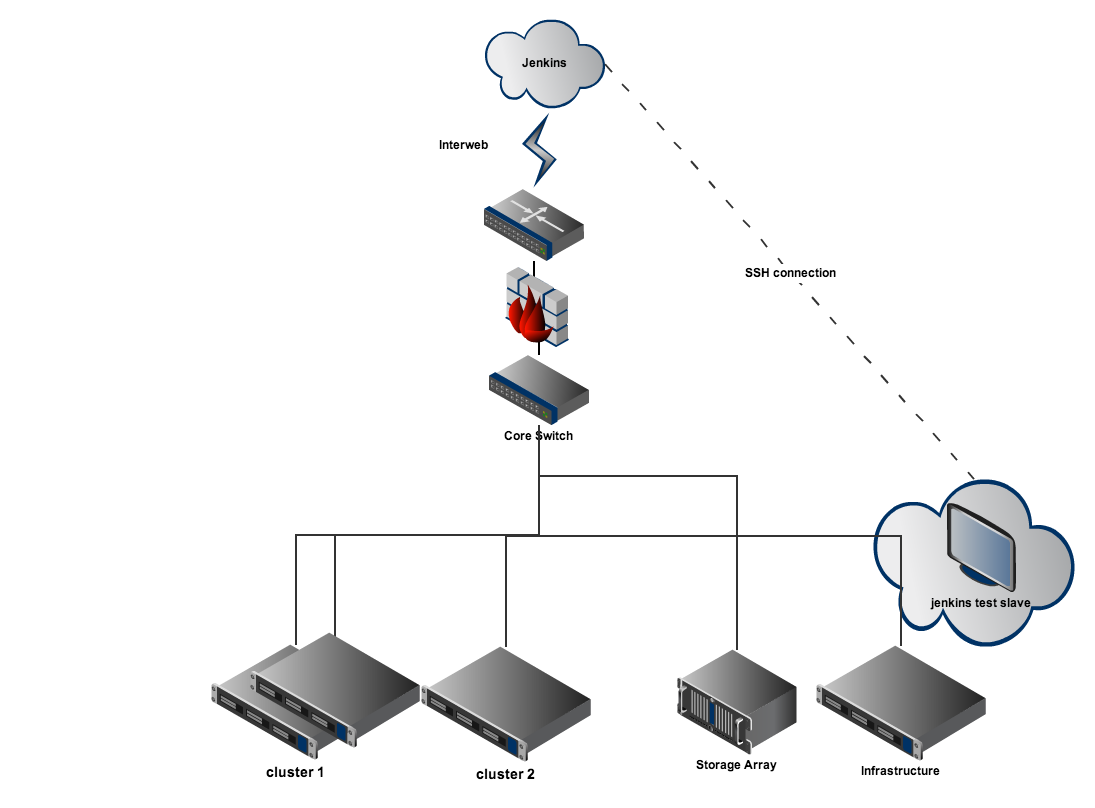
The central jenkins (master) instance at jenkins.bacd.org connects to a jenkins slave within the data center via SSH. Traditionally a non-standard port with key-pair only access is preferred to keep the deployment secure. This slave is a VM with necessary packages, scripts and tools that drives the rest of the dedicated test infrastructure through various configurations required for testing. All the necessary configurations are controlled by a matrix of combinations. These combinations are nothing but jobs on the jenkins (master).
The jenkins slave instance(s) are placed on your managed infrastructure. This managed infra could be an internal cloudstack deployment by itself.
The cluster1, cluster2 ... are racks/pods of hypervisor blades outside your regular managed infrastructure that will form the testbed for cloudstack setup using jenkins' jobs. For this setup we manage all the power features using an IPMI network (not shown here).
The storage is usually shared by all of the test-bed infrastructure. But you are free to deploy this as you have modelled your production installation of cloudstack.
Components in the jenkins slave
The necessary packages and tools that compose this jenkins slave are described below. Briefly described is also the purpose of the tool and any special configuration required.
- cobbler - all baremetal PXE booting from ISO images. Preloaded (RHEL, Ubuntu, XenServer, ESXi) images
- puppetmaster - puppet is used for the configuration of packages within the freshly deployed management server VM.
- dnsmasq - Manages all the DNS for the dedicated testbed.
- python and virtualenv - tests run within the virtualenv environment in each run
- httpd and yumrepo - an ephemeral yum repository holding latest packages from a development branch
Key components
At the center of the workflow is the "jenkins slave" appliance that manages the infrastructure. This is a Cent OS 6.2 VM running on a XenServer. The slave VM is responsible for triggering the entire test run when it is time. This schedule is indicated by jenkins master through the test jobs.
The slave appliance is composed of the following parts:
Cobbler
cobbler is a provisioning PXE server (and much more) useful for rapid setup of Linux machines. It can do DNS, DHCP, power management and package configuration via puppet. It is capable of managing network installation of both physical and virtual infrastructure. Cobbler comes with an expressive CLI as well as web-ui frontends for management.
Cobbler manages installations through profiles and systems:
- profiles - these are text files called kickstarts defined for a distribution's installation. For eg: RHEL 6.1 or Ubuntu 12.04 LTS. Each of the machines in the test environment - hypervisors and CloudStack management servers contains a profile in the form of a kickstart.
The profile list looks as follows on our sample setup:
root@infra ~# cobbler profile list
cloudstack-rhel
cloudstack-ubuntu
rhel63-KVM
ubuntu1204-x86_64
xen62
xen56
- systems - these are virtual/physical infrastructure mapped to cobbler profiles based on the hostnames of machines that can come alive within the environment.
root@infra ~# cobbler system list
acs-qa-h11
acs-qa-h20
acs-qa-h21
acs-qa-h23
cloudstack-rhel
cloudstack-ubuntu
So eg: if acs-qa-h11 is mapped to rhel63-KVM cobbler will refresh the machine with a base OS of RHEL and install necessary virtualization packages for KVM.
When a new image needs to be added we create a 'distro' in cobbler and associate that with a profile's kickstart. Any new systems to be hooked-up to be serviced by the profile can then be added easily by cmd line.
Puppetmaster
Cobbler reimages machines on-demand but it is up to Puppet recipes to do configuration management within them. The configuration management is required for KVM hypervisors (KVM agent for eg: ) and for the CloudStack management server which needs mysql, cloudstack, etc. The puppetmasterd daemon on the slave-vm is responsible for 'kicking' nodes to initiate configuration management on themselves when they come alive.
So the slave-vm is also the repository of all the Puppet recipes for various modules that need to be configured for the test infrastructure to work. The modules are placed in /etc/puppet and bear the same structure as our github repo. When we need to affect a configuration change on any of our systems we only change the github repo and the systems in place are affected upon next run.
dnsmasq
DNS is controlled by cobbler but its configuration of hosts is set within dnsmasq.d/hosts. This is a simple 1-1 mapping of hostnames with IPs. For the most part this should be the single place where one needs to alter for replicating the test setup. Everywhere else only DNS names are/should-be used.
DHCP
DHCP is also done by dnsmasq. All configuration is in /etc/dnsmasq.conf. static mac-ip-name mappings are given for hypervisors while the virtual instances get dynamic ips
Power Management
ipmi for power management is setup on all the test servers and the ipmitool provides a convienient CLI for booting the machines on the network into PXEing.
marvin integration
Once CloudStack has been installed and the hypervisors prepared we are ready to use marvin to stitch together zones, pods, clusters and compute and storage to put together a 'cloud'. Once configured - we perform a cursory health check to see if we have all systemVMs running in all zones and that built-in templates are downloaded in all zones. Subsequently we are able to launch tests on this environment
Only the latest tests from git are run on the setup. This allows us to test in a pseudo-continuous fashion with a nightly build deployed on the environment. Each test run takes a few hours to finish.
Control via github
There are two github repositories controlling the test infrastructure.
a. The Puppet recipes at gh:acs-infra-test
b. The gh:cloud-autodeploy repo that has the scripts to orchestrate the overall workflow
Workflow
When jenkins triggers the test job following sequence of actions occur on the test infrastructure
- The deployment configuration is chosen based on the hypervisor being used. We currently have xen.cfg and kvm.cfg that are in the gh:cloud-autodeploy repo
- A virtualenv python environment is created within which the configuration and test runs by marvin are isolated into. Virtualenv is great for sandboxing test environment runs. In to the virtualenv are copied all the latest tests from the cloudstack repo.
- We fetch the last successful marvin build and install it within this virtualenv. Installing a new marvin on each run helps us test with the latest APIs available.
- We fetch the latest version of the driver script from github:cloud-autodeploy. fetching the latest allows us to make adjustments to the infra without having to copy scripts in to the test infrastructure.
- Based on the hypervisor chosen we choose a profile for cobbler to reimage the hosts in the infrastructure. If xen is chosen we bring up the profile of the latest xen kickstart available in cobbler. currently - this is at xenserver 6.2. If KVM is chosen we can pick between ubuntu and rhel based host OS kickstarts. Other hypervisors such as ESXi and XCP are also bootable.
- With this setup we kick off the driver script with the following cmd line arguments
$ python configure.py -v $hypervisor -d $distro -p $profile -l $LOG_LVL
The $distro argument chooses the hostOS of the mgmt server - this can be ubuntu / rhel. LOG_LVL can be set to INFO/DEBUG/WARN for troubleshooting and more verbose log output.
- The configure script does various operations to prepare the environment:
- clears up any dirty cobbler systems from previous runs
- cleans up Puppet certificates of these systems. Puppet recipes will fail if puppetmaster finds an invalid certificate
- starts up a new xenserver VM that will act as the mgmt server. we chose to keep things simple by launching the vm on a xenserver. one could employ jclouds via jenkins to deploy the mgmt server VM on a dogfooded cloudstack.
- in parallel the deployment config of marvin is parsed through to find the hypervisors that need to be cleaned up, pxe booted and prepared for the CloudStack deployment.
- all the hosts in the marvin config are pxe booted via ipmi and cobbler takes over to reimage them with the profile chosen by the jenkins job run.
- while this is happening we also seed the secondary storage with the systemvm template reqd for the hypervisor.
- all the primary stores in the marvin config are then cleaned for the next run.
- While cobbler is reimaging the hosts with the right profiles, the configure script waits until all hosts are reachable over ssh. It also checks for essential services (http, mysql) ports to come up. Cobbler once done with refreshing the machine hands over the reins to puppet.
- Puppet slaves within the machines in the environment reach out to puppetmaster to get their identity. mgmt server vm fetches its own recipe and starts configuring itself while hypervisors will do the same in case they need to be acting as KVM agents.
- When the essential ports for mgmt server - 8080 and 8096 are open and listening we know that the mgmt server has come up successfully. We then go ahead and deploy the configuration specified by marvin.
- After marvin finishes configuring the cloud - it performs a health check to see if the system is ready for running tests upon.
- Tests are run using the nose test runner with the marvin plugin and reports are recorded by jenkins.
Jobs in the jenkins test pipeline
The jenkins pipeline (sequence of jobs) for the above workflow of tests is described below in flowchart format.
View the configuration of test-matrix/test-matrix-extended jobs to understand further.
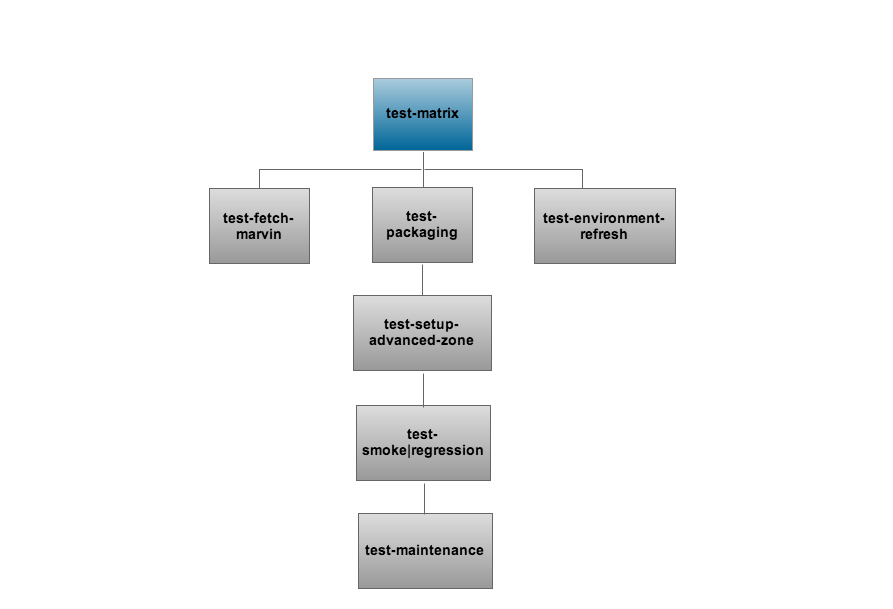
- test-matrix-* - This is the umbrella job that starts all other jobs in the sequence. This job points to master by default and so does test-yumrepo-refresh. When you want to change the branch you have to change it for both jobs to ensure your tests are running on the right target branch.
- test-yumrepo-refresh - hourly job refreshing packages on a s3 bucket
- test-environment-refresh - cleanup all hosts to a target cobbler profile (xen/xcp/kvm)
- test-packaging - deploy new cloudstack vm, configure packages, install cloudstack latest rpms from s3
- test-setup-advanced-zone - setup an advanced zone on the testbed and wait for systemvms to be ready
- test-smoke|regression-matrix - run the bvt/full regression tests on the environment
- test-maintenance-operations - run any tests that need to run sequentially like maintenance mode on hosts, disabling zone etc.
Limitations
- Currently this infrastructure has limited capacity and with the increasing number of tests we sometimes run out of resources during a test run
- Only advanced zone and basic zone with security groups are currently employed. Any external networking device etc is not employed in this testbed
- No object storage or ceph storage
Enhancements
- run test fixes on idle environment upon checkin without deploy
- creating ones own slave vm appliance
- dogfooding the slave appliance via packer
- custom zones - using a marvin config file
- digest emails via jenkins. controlling spam
- external devices (LB, VPX, FW)
Future
- monitoring and status page for the infra
- control all jenkins jobs via github using jenkins-job-builder
- multiple internal jenkins environments on a single landing page jenkins.bacd.org
- multiple hv environments with multiple hv configurations
- multiple storage configurations - ceph, object store etc
Troubleshooting
Any of the several steps in the workflow can fail. If you find a failure, please bring the issue to notice on the dev@ mailing list.
Overview
Content Tools
Apps