Status
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
Deciding proper parallelisms for job vertices is not easy work for many users. Considering batch jobs, a small parallelism may result in long execution time and big failover regression. While an unnecessary large parallelism may result in resource waste and more overhead cost in task deployment and network shuffling.
To decide a proper parallelism, one needs to know how much data each job vertex needs to process. However, It can be hard to predict data volume to be processed by a job because it can be different everyday. And it can be harder or even impossible (due to complex operators or UDFs) to predict data volume to be processed by each job vertex.
Therefore, we’d like to propose an adaptive batch scheduler which can automatically decide parallelisms of job vertices for batch jobs. If a job vertex is not set with a parallelism, the scheduler will decide parallelism for the job vertex according to the size of its consumed datasets. The automatically decided parallelisms can better fit varying data volume everyday. It can also better fit each job vertex on its data to process, especially for SQL job vertices which cannot be manually tuned individually.
Major benefits of this scheduler includes:
- Batch job users can be relieved from parallelism tuning
- Automatically tuned parallelisms can be vertex level and can better fit consumed datasets which have a varying volume size every day
- Vertices from SQL batch jobs can be assigned with different parallelisms which are automatically tuned
- It can be the first step towards enabling auto-rebalancing workloads of tasks (see section Auto-rebalancing of workloads)
Public Interfaces
We intend to extend/introduce the following new configuration values/parameters:
- Extend jobmanager.scheduler to accept new value "AdaptiveBatch" in order to activate the adaptive batch scheduler.
- Introduce "jobmanager.adaptive-batch-scheduler.min-parallelism" as the lower bound of allowed parallelism to set adaptively.
- Introduce "jobmanager.adaptive-batch-scheduler.max-parallelism" as the upper bound of allowed parallelism to set adaptively.
- Introduce "jobmanager.adaptive-batch-scheduler.data-volume-per-task" as the size of data volume to expect each task instance to process.
- Introduce "jobmanager.adaptive-batch-scheduler.default-source-parallelism" as the default parallelism of source vertices. See Deciding Parallelism of Source Vertex for more details.
Proposed Changes
General Idea
To achieve the proposed scheduler which automatically decides parallelisms of job vertices for batch jobs, changes below are needed:
- Enables scheduler to collect sizes of finished BLOCKING datasets
- Introduces a VertexParallelismDecider to compute proper parallelisms for vertices according to the sizes of their consumed results
- Enables ExecutionGraph to be built up dynamically. This further requires that
- Related scheduling components should be updatable
- Upstream tasks can be deployed without knowing parallelisms of its consumer job vertices
- Implements AdaptiveBatchScheduler which properly updates and schedules a dynamic ExecutionGraph
Note that in order to avoid the situation that the pipeline regions containing multiple tasks may not be scheduled (due to insufficient slots) in standalone/reactive mode, the adaptive batch scheduler currently only supports ALL-EDGES-BLOCKING batch jobs. See section ALL-EDGES-BLOCKING batch jobs only for more details.
Details will be discussed in the following sections.
Collect Sizes of Finished BLOCKING Results
The adaptive batch scheduler decides the parallelism of vertices by the size of input results. To do this, the scheduler needs to know the size of each result partition when the task is finished.
We propose to introduce the numBytesProduced counter and register it into TaskIOMetricGroup, to record the size of each result partition. The snapshot of the counter will be sent to the scheduler when tasks finish.
For broadcast result partition, we need the amount of data actually produced by the vertex, instead of the amount of data sent to downstream tasks, so we introduce numBytesProduced counter instead of numBytesOut counter, to avoid the size of the broadcast result being counted multiple times.
class TaskIOMetricGroup {
...
Map<IntermediateResultPartitionID, Counter> getResultPartitionBytesProducedCounters();
void registerResultPartitionBytesProducedCounter(IntermediateResultPartitionID resultPartitionId, Counter resultPartitionBytesProducedCounter);
...
}
Vertex Parallelism Decider
VertexParallelismDecider API
We propose to introduce VertexParallelismDecider to decide the parallelism of vertices.
/**
* This class is responsible for determining the parallelism of a job vertex, based on the
* information of consumed results.
*/
class VertexParallelismDecider {
int decideParallelismForVertex(List<BlockingResultInfo> consumedResults);
class Factory {
VertexParallelismDecider create(Configuration configuration);
}
}
class BlockingResultInfo {
List<Long> getBlockingPartitionSizes();
/**
* Will be used when calculating parallelism, see section
* Deciding Parallelism of Non-source Vertex for more details.
*/
boolean isBroadcast();
}
Deciding Parallelism of Source Vertex
Considering the source vertex has no input, the scheduler cannot automatically decide parallelism for them. We suggest the following two options:
- Kind of source can infer parallelism according to the catalog. For example, HiveTableSource, see HiveParallelismInference for more details.
- Considering other sources, we proposed to introduce configuration "jobmanager.adaptive-batch-scheduler.default-source-parallelism”, users can manually configure source parallelism.
Deciding Parallelism of Non-source Vertex
The parallelism of non-source vertices will be calculated by the interface VertexParallelismDecider according to the size of the consumed results. We provide a default implementation as follows:
Suppose
- V is the bytes of data the user expects to be processed by each task.
- totalBytesnon-broadcast is the sum of the non-broadcast result sizes consumed by this job vertex.
- totalBytesbroadcast is the sum of the broadcast result sizes consumed by this job vertex.
- maxBroadcastRatio is the maximum ratio of broadcast bytes that affects the parallelism calculation.
- normalize(x) is a function that round x to the closest power of 2.
then the parallelism of this job vertex P will be:
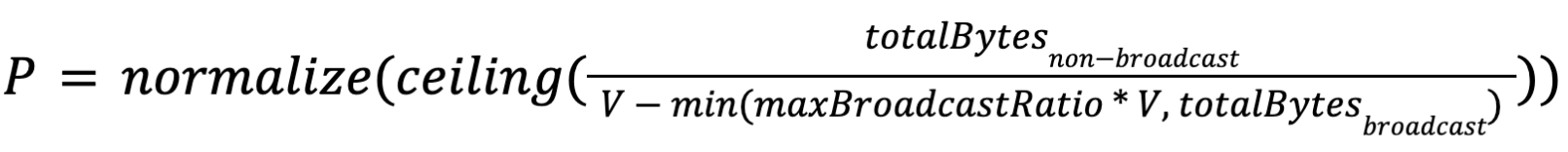
Note that we introduced two special treatment in the above formula (you can click the links for details):
Dynamic Execution Graph
Currently the execution graph will be fully built in a static way before starting scheduling. To allow parallelisms of job vertices to be decided lazily, the execution graph must be able to be built up dynamically.
Create Execution Vertices and Execution Edges Lazily
A dynamic execution graph means that a Flink job starts with an empty execution topology. The execution topology consists of execution vertices and execution edges.
Execution vertices can be created and attached to the execution topology only when:
- the parallelism of the corresponding job vertex is decided
- all upstream execution vertices are already attached
A decided parallelism of the job vertex is needed so that Flink knows how many execution vertices should be created. Upstream execution vertices need to be attached first so that Flink can connect the newly created execution vertices to the upstream vertices with execution edges.
Solution-wise regarding current implementation, an ExecutionGraph should start with a set of registered ExecutionJobVertex. By initializing an ExecutionJobVertex, ExecutionVertex will be created from it and edge connections will be built for them. The initialization also includes the creation of other components
- IntermediateResult and IntermediateResultPartition
- OperatorCoordinator and InputSplitAssigner
Note that for a dynamic graph, since its execution vertices can be lazily created, a job should not finish when all ExecutionVertex(es) finish. Changes should be made to let a job finish only when all registered ExecutionJobVertex have finished.

Updatable scheduler components
Many scheduler components rely on the execution topology to make decisions. Some of them will build up some mappings against the execution topology on initialization for later use. When the execution topology becomes dynamic, these components need to be notified about the topology changes and adjust themselves accordingly. These components are:
- DefaultExecutionTopology
- SchedulingStrategy
- PartitionReleaseStrategy
- SlotSharingStrategy
- OperatorCoordinatorHandler
- Network memory of SlotSharingGroup.
To support this, we propose changes below:
- For DefaultExecutionTopology, add a new public method:
class DefaultExecutionTopology {
...
void notifyExecutionGraphUpdated(DefaultExecutionGraph executionGraph, List<ExecutionJobVertex> newJobVertices);
...
}
2. For SchedulingStrategy, PartitionReleaseStrategy and SlotSharingStrategy, they should extends SchedulingTopologyListener which is defined as below:
public interface SchedulingTopologyListener {
/**
* Notifies that the scheduling topology is just updated.
*
* @param schedulingTopology which is just updated
*/
void notifySchedulingTopologyUpdated(SchedulingTopology schedulingTopology, List<ExecutionVertexID> newlyAddedVertices);
}
3. For OperatorCoordinatorHandler, add a new interface method to notify the operator coordinators of newly initialized ExecutionJobVertex:
interface OperatorCoordinatorHandler {
...
void registerAndStartNewCoordinators(Collection<OperatorCoordinatorHolder> coordinators, ComponentMainThreadExecutor mainThreadExecutor);
...
}
4. Currently, when fine-grained resource management is enabled, the scheduler will calculate network memory for all SlotSharingGroups during its initialization. For dynamic graphs, the network memory of SlotSharingGroup should also be calculated lazily. Once a vertex is initialized, find its corresponding slot sharing group and check whether all vertices in this slot sharing group have been initialized. If all vertices have been initialized, the scheduler will calculate the network resources for this slot sharing group.
Flexible subpartition mapping
Currently, when a task is deployed, it needs to know the parallelism of its consumer job vertex. This is because the consumer vertex parallelism is needed to decide the numberOfSubpartitions of PartitionDescriptor which is part of the ResultPartitionDeploymentDescriptor. The reason behind that is, at the moment, for one result partition, different subpartitions serve different consumer execution vertices. More specifically, one consumer execution vertex only consumes data from subpartition with the same index.

Considering a dynamic graph, the parallelism of a job vertex may not have been decided when its upstream vertices are deployed. To enable Flink to work in this case, we need a way to allow an execution vertex to run without knowing the parallelism of its consumer job vertices. One basic idea is to enable multiple subpartitions in one result partition to serve the same consumer execution vertex.
To achieve this goal, we can set the number of subpartitions to be the max parallelism of the consumer job vertex. When the consumer vertex is deployed, it should be assigned with a subpartition range to consume.
Computing Consumed Subpartition Range
The consumed subpartition range should be computed in TaskDeploymentDescriptorFactory
when creating the InputGateDeploymentDescriptor. When this happens, it is already known that how many consumer execution vertices there will be for each result partition, and how many subpartitions these result partitions have. Note that if an execution vertex consumes multiple result partitions (belonging to one IntermediateResult), all these partitions will be in the same ConsumedPartitionGroup(FLINK-21110), so that they will have the same consumer execution vertices and the same subpartition number.
For one result partition, if N is the number of consumer execution vertices and P is the number of subpartitions. For the kth consumer execution vertex, the consumed subpartition range should be:
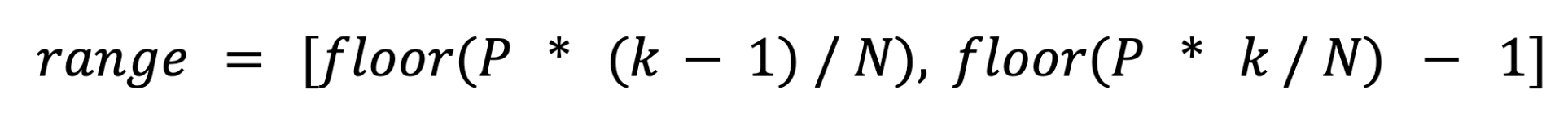
For broadcast results, we can't directly use the above formula, but need to do some special processing. Because for the broadcast result, each subpartition contains all the data to broadcast in the result partition, consuming multiple subpartitions means consuming a record multiple times, which is not correct. Therefore, we propose that the number of subpartitions for broadcast partitions should always be 1, and then all downstream tasks consume this single subpartition( The partition range of the broadcast partition is always set to 0).

A public method should be added to InputGateDeploymentDescriptor to get the range, as a replacement of the old getConsumedSubpartitionIndex() method.
class InputGateDeploymentDescriptor {
...
SubpartitionIndexRange getConsumedSubpartitionIndexRange();
...
}
class SubpartitionIndexRange {
int getStartSubIdx();
int getEndSubIdx();
}
Shuffle Service Supports Consuming Subpartition Range
Currently, all input channels from a SingleInputGate can only consume subpartitions with the same subpartition index (identified by SingleInputGate#consumedSubpartitionIndex).
In adaptive batch scheduler, the shuffle service needs to support a SingleInputGate to consume a certain range of subpartitions, the following changes are need:
- A SingleInputGate should support consuming a certain range of subpartitions, and it should contain all channels that consume the range of subpartitions. Suppose R is the number of subpartitions in this range, P is the number of partitions consumed, the number of input channels will be R * P.
- The field consumedSubpartitionIndex should be moved from SingeInputGate to InputChannel to identify the subpartition consumed by this channel.

The above modification may bring negative effects when using an excessive max parallelism, see Negative effects of using an excessive max parallelism for details.
Adaptive Batch Scheduler
The proposed AdaptiveBatchScheduler will extend the DefaultScheduler. The only differences are:
- An empty dynamic execution graph will be generated initially
- Before handling any scheduling event, the scheduler will try deciding the parallelisms for job vertices, and then initialize them to generate execution vertices, connecting execution edges, and update the execution graph
- It uses the VertexwiseSchedulingStrategy, which schedules vertices in vertex-wise way
Deciding Parallelisms for Job Vertices
The scheduler will try to decide the parallelism of all vertices before each scheduling.
For source vertices, the parallelism should have been decided before starting scheduling in following two ways:
- The parallelism is specified in JobGraph (user specified, or automatically inferred by source.)
- When creating the executionGraph, the parallelism of all source vertices will be decided according to the configurations such as "jobmanager.adaptive-batch-scheduler.default-source-parallelism".
For non-source vertices, the parallelism can be decided only when all its consumed results (all consumed results should be BLOCKING) are fully finished. The parallelism calculation algorithm can see Vertex Parallelism Decider.
The parallelism decision will be made for each job vertex in topological order to ensure that a vertex will be checked and assigned a parallelism after its upstream vertices have been checked and assigned parallelisms.
Initializing Execution Job Vertex and Update Topology
After trying to decide the parallelism of all job vertices, we then try to initialize the vertices according to the topological order. A vertex that can be initialized should meet the following conditions:
- The parallelism of the vertex has been decided and the vertex has not been initialized yet.
- All upstream job vertices have been initialized.
Finally, update scheduler components according to newly initialized vertices as described in Updatable scheduler components.
Vertex-wised Scheduling Strategy

Considering that the adaptive batch scheduler currently only supports ALL-EDGES-BLOCKING jobs, and needs to handle the scheduling topology updates during scheduling, we introduce a new scheduling strategy: VertexwiseSchedulingStrategy.
When an execution vertex is finished, the new scheduling strategy will try to check the following execution vertices to see if they can be scheduled :
- All its consumer vertices.
- All execution vertices that are newly added to topology. It is needed because otherwise some vertices will never be scheduled. e.g. If A1 finishes first and A2 finishes later, no vertex will be scheduled when A1 finishes because B1 has not been added to scheduling topology. And only B2 will be scheduled when A2 finishes, B1 will never be scheduled if we don't try to schedule the newly added vertices.
Special Processing
Convert partitioner-unspecified edges to RESCALE edges
Currently, partitioner-unspecified edges(partitioner is not explicitly set by users) will be setted to FORWARD when the parallelism of both upstream and downstream are both the default parallelism(ExecutionConfig#PARALLELISM_DEFAULT). This may cause many job vertices whose parallelism is not calculated based on data volume, but is aligned with their upstream vertices' parallelism because of forward edges, which is contrary to the original intention of our adaptive batch scheduler. To resolve this problem, we need to convert the partitioner-unspecified edges between the job vertices to RESCALE edges instead of FORWARD edges.
Support for FORWARD edges
In Flink jobs, some operators have strict requirements on FORWARD edge, but the adaptive batch scheduler can’t natively support it. Because once a vertex has multiple forward inputs with different parallelism (calculated by the vertex parallelism decider), some edges will lose their forward attributes. To solve this problem, we need to introduce ForwardGroup, which refers to a subgraph connected by forward edges. The vertices in a ForwardGroup must have the same parallelism, and we define it as the ForwardGroup’s parallelism. Then we can decide the parallelism for a vertex as follows: If the ForwardGroup’s parallelism where the vertex is located has been decided, then the vertex’s parallelism should be the same as the ForwardGroup’s parallelism. Otherwise, the vertex’s parallelism should be calculated by the above-mentioned algorithm, and take it as the ForwardGroup’s parallelism.
Implementation Plan
The implementation includes the following parts, of which 1, 2, 3 can be parallel, and 4 relies on them.
1. Support to collect result sizes when jobs finish.
The first part is to support the collection of the result partition size when jobs finish, so that the scheduler can calculate the parallelism of downstream vertices based on this information.
2. Introduce VertexParallelismDecider.
The second part is to introduce VertexParallelismDecider and provide a default implementation as described in Vertex Parallelism Decider.
3. Support dynamic execution graph.
The third part is to support creating execution graphs in a dynamic way, including two sub-parts that can be parallel:
- Support lazy initialization of vertices, updatable scheduler components
- Support flexible subpartition mapping
4. Add adaptive batch scheduler.
Finally, add an adaptive batch scheduler and provide users with related configurations.
Compatibility, Deprecation, and Migration Plan
The changes of this FLIP can mainly be divided into two parts:
- Dynamic Execution Graph. This part of the modification does not affect the default behavior of flink.
- Adaptive batch scheduler. The adaptive batch scheduler will be an optional feature which the user has to activate explicitly by setting the config option jobmanager.scheduler: AdaptiveBatch, this entails that Flink's default behaviour won't change.
Limitations
ALL-EDGES-BLOCKING batch jobs only
Currently, when submitting a batch job with too high parallelism onto a standalone cluster, the pipeline regions containing multiple tasks may not be scheduled due to insufficient slots, which will give users an inconsistent experience with streaming jobs (Adaptive Scheduler). This problem might become a bit more present when using the adaptive batch scheduler, because the parallelism may change depending on the amount of data.
To avoid this situation, the adaptive batch scheduler currently only supports ALL-EDGES-BLOCKING batch jobs. We intend to completely solve this problem in the future by considering available slots when making parallelism decisions, which is similar to adaptive scheduler.
Negative effects of using an excessive max parallelism
As mentioned above, excessive max parallelism may have negative effects on performance and resource usage, including:
- Large network memory usage of upstream tasks. When using hash shuffle, the network memory used by result partitions is proportional to the number of subpartitions. Excessive max parallelism will result in a large number of subpartitions, and further result in a large amount of network memory usage.
- Large network memory usage of downstream tasks. The network memory used by the input gate is proportional to the number of input channels. An excessive max parallelism will also result in a large number of input channels, and further result in a large amount of network memory usage for downstream tasks.
- Affects performance. An excessive max parallelism results in a large number of subpartitions. A large number of subpartitions may cause each subpartition to be too small and even unable to fill a buffer, which may affect the compression rate and network transmission performance. In addition, it may also cause a lot of random disk IO, which will slow the IO speed.
For the above problems, the following are several mitigation solutions.
- Using sort based shuffle. The network memory used by upstream tasks is independent of parallelism when using sort based shuffle. This can limit the network memory used by upstream tasks to a fixed value.
- Currently in Flink, it is allowed to configure exclusive buffers of each channel to 0 and only use floating buffers, so that the network memory used by downstream tasks can also be independent of parallelism. In addition, in the future, we intend to allow one input channel to read all data in a subpartition range, so that the number of input channels can be independent of max parallelism, thereby reducing network memory usage.
Anyway, it is still not recommended to configure an excessive max parallelism.
The max parallelism when using the adaptive batch scheduler should be the same as the parallelism you want to configure when using the default scheduler. In this way, when the amount of data of input is large enough, the adaptive batch scheduler will have the same performance as the default scheduler. When the amount of data is small, the adaptive batch scheduler will gain resource and performance advantages because it adapts a more appropriate smaller parallelism.
Inconsistent broadcast results metrics on WebUI
Note that in adaptive batch scheduler, for broadcast results, the number of bytes/records sent by the upstream vertex counted by metric is not equal to the number of bytes/records received by the downstream vertex, which may confuse users when displayed on the Web UI. The reason is as follow:
For a broadcast result partition, assuming that the actual data to be broadcast is D, then each subpartition produced by upstream vertex will be a D, and each downstream task expects to consume a D. Assuming that P_max is the maximum parallelism of the downstream vertex and P_actual is the actual parallelism of the downstream vertex, the number of bytes/records sent by the upstream vertex is P_max*D and the number of bytes/records received by the downstream vertex is P_actual*D. Therefore, if P_actual does not equal P_max, the numBytesOut metric of a task will not equal numBytesIn metric of its downstream task.
I
Future improvements
Auto-rebalancing of workloads
When running batch jobs, data skew may occur (a task needs to process much larger data than other tasks), which leads to long-tail tasks and further slows down the finish of jobs. Users usually hope that the system can automatically solve this problem.
One typical data skew case is that some subpartitions have a significantly larger amount of data than others. This case can be solved by finer grained subpartitions and auto-rebalancing of workload. The work of the adaptive batch scheduler can be considered as the first step towards it, because the requirements of auto-rebalancing are similar to adaptive batch scheduler, they both need the support of dynamic graphs and the collection of result partitions size.
Based on the implementation of adaptive batch scheduler, we can solve the above problem by increasing max parallelism (for finer grained subpartitions) and simply changing the subpartition range division algorithm (for auto-rebalancing). In the current design, the subpartition range is divided according to the number of subpartitions, we can change it to divide according to the amount of data in subpartitions, so that the amount of data within each subpartition range is basically the same. In this way, workloads of downstream tasks can be balanced.

Test Plan
The proposed changes will be tested for correctness and performance through the TPC-DS benchmark suite in a real cluster.