Status
Motivation
More details can be found in the Flink ML Roadmap Document and in the Flink Model Serving effort specific document.
Model Serving Use Cases and solution Architecture
We describe here the requirements for the core part of a model serving system. Architecture should cover the use cases described below.
Model Deployment Cases
There are two basic approaches to machine learning - online and offline. This proposal refers only to offline model training case, although as a next step we might consider the on-line case as well. The served model is fully trained at the point of deployment.
Basic Use Case
The simplest use case is as follows: user deploys a single ML model (eg. regression model) in the model serving system and then it is accessible for scoring. For the general case the user runs N models. There might be more than one instance per model for performance reasons.
In certain use cases, for example, IoT or telecom operators, it is possible that N maybe very large eg. hundreds of thousands of models since in such occasions there is no generic model that covers everything. Our system needs to handle such scenarios.
It is often true that a model is fed with a pre-processed stream of data and then the output
of the same model might require processing as well. This idea is covered by the concept of a Machine Learning (ML) Pipeline as we will see later on.
By introducing the idea of a ML pipeline as described below (Figure 2), the above statements apply to the pipeline concept as well. As a result, the ML pipeline can be seen as unit of deployment for model serving purposes.
Multiple Models Use Case
Now within the same pipeline it is also possible to run multiple models:
a) Model Segmentation
b) Model Ensemble
c) Model Chaining
d) Model Composition
See for more here.
From the point of view of model serving, we always treat a pipeline as a single model, regardless of the amount of models encoded in it. User can always compose pipelines (or models in the simple case) as part of the overall processing being done, but if this can be achieved via the supported model format eg. PMML then it might be the prefered way to do it since this will be managed automatically by the library implementing the specific format.
Another case is to run multiple versions of the same machine learning pipeline within the serving system. One reason can be A/B testing.
For the purpose of this implementation, we consider versions of a model as different models. If the versioning is important, we recommend an external system, managing model’s versions, but assigning them unique Ids so that we can treat them as different one for the purpose of serving.
Online Models
This proposal does not address online learning.
Other System Dimensions
Filtering and transformation
Filtering and transformation of both input and output data is included in the pipeline definition, as described below.
Operations
The model serving system is easy to operate so that the user with a specific request can remove or add any pipeline. It also allows to suspend any more pipeline deployments.
This requirement is supported through usage of model’s stream.
Logging - Monitoring
User is able to retrieve any related logs for a particular model or stage of the pipeline.
It would be good to have a logging strategy independently of any real-time monitoring
capabilities as a backup for the history of events. We propose usage of the quariable state, see below, for getting all relevant information about model serving.
User is able to retrieve any information needed to get meaningful statistics about
a model/pipeline. We propose usage of the quariable state, see below, for getting all relevant monitoring information
Prediction Results
The implementation provides model serving as a functional transformation on the input data stream. THe serving can be also subject for functional composition of models.
Non Functional
Every served pipeline creates certain demands for resources to the model serving system.
Multiply these requirements by the number of served pipelines and this defines the notion of the scoring resource requirements for the system. Extra resources might be needed for serving queries for model metadata and model status. Currently user needs to know available resources within the system in order to deploy a pipeline so resource utilization is balanced, the system may help to that direction if possible. Introduction of Flip 6 will allow to alleviate this problem by automatically managing resources used by Flink.
Sometimes when it comes to resource management we would like be able to map model resource requirements known in advance (memory, cpu etc) to the underlying infrastructure.This is possible with several platforms by using label selectors on K8s or roles on Mesos and the model serving system should be able to take advantage of these capabilities. As an example for performance reasons I might want to run a Tensorflow model on specific nodes only with gpu capabilities. At the end of the day in such scenarios we might deploy a separate model serving service but users need to understand their options with this solution.
Encryption might be required for end-to-end communication and for any data at rest within the system. Authentication and Authorization is supported end-to-end for the model serving system.
Last but not least, users should be able to serve the ML pipelines locally at the development phase, while transition to production should require either minimal or no changes.
Overall implementation architecture
Currently, there are multiple tools available to Data scientists, who tend to use different tools for solving different problems and as a result they are not very keen on tools standardization.
This creates a problem for software engineers trying to use “proprietary” model serving tools supporting specific machine learning technologies. As data scientists evaluate and introduce new technologies for machine learning, software engineers are forced to introduce new software packages supporting model scoring for these additional technologies.
One of the approaches to deal with these problems is the introduction of a multiplexer on top of this proprietary systems. Although this hides the disparity of the back end systems from the consumers behind the unified APIs for model serving it still requires installation and maintenance of the actual model serving implementations.
Here we are taking an alternative approach of running model serving “natively” inside Flink server, similar to approach taken in Flink TensorFlow or Flink JPMML. But unlike approach talking by Flink Tensorflow implementation where models are “compiled” into implementation (note: Flink-JPMML supports dynamic pipelines’ serving since 0.6.0 version), we want to use dynamically controlled stream approach - models are delivered to running implementation via model’s stream and dynamically instantiated for usage. Basically, we are proposing building a streaming system allowing to update models without interruption of execution with the overall architecture which looks like follows:
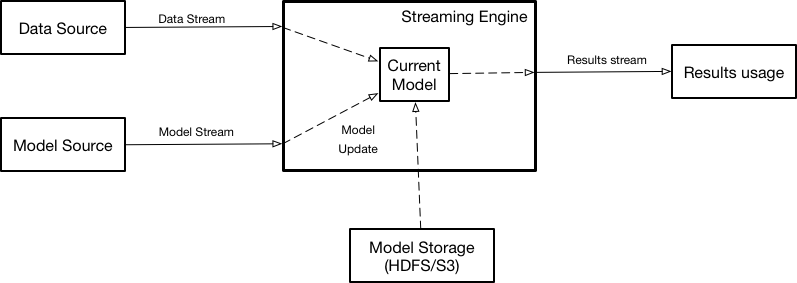
Figure 1. Overall architecture of model serving
This architecture assumes two data streams - one containing data that needs to be scored, and one containing the model updates. The streaming engine contains the current model used for the actual scoring in memory. The results of scoring can be either delivered to the customer or used by the streaming engine internally as a new stream - input for additional calculations. If there is no model currently defined, the input data is dropped. When the new model is received, it is instantiated in memory, and when instantiation is complete, scoring is switched to a new model. The model stream can either contain the binary blob of the data itself or the reference to the model data stored externally (pass by reference) in a database or a filesystem, like HDFS or S3. When possible it is preferred that the models loaded in the system to be kept in the streaming engine’s managed state which can be checkpointed and so model restoration in case of failures is automatically handled. Streaming engine’s like Flink excel at handling large states while models can also be large eg. several GBs when they are very complex.
The proposed approach so for effectively uses model scoring as a new type of functional transformation, that can be used by any other stream functional transformations.
Although the overall architecture above is showing a single model, a single streaming engine could score multiple models simultaneously.
Machine Learning pipeline
For the longest period of time model building implementation was ad hoc - people would transform source data any way they see fit, do some feature extraction, and then train their models based on these features. The problem with this approach is that when someone wants to serve this model, it is necessary to discover all of those intermediate transformations and reimplement them in the serving application.
In an attempt to formalize this process, UC Berkeley AMPLab introduced machine learning pipelines a graph defining the complete chain of data transformation steps.

Figure 2. Machine learning pipeline
The advantage of this approach is twofold:
It captures the whole processing pipeline including data preparation transformations, machine learning itself and any required post processing of the ML results. This means that pipeline defines complete transformation from well defined inputs to outputs, thus simplifying update of the model.
The definition of the complete pipeline allows for optimization of the processing.
A given pipeline can encapsulate more than one model (see, for example, PMML model composition). In this case, we consider such models internal - non visible for scoring. From scoring point of view a single pipeline always represents a single unit, regardless of how many models it encapsulates.
This notion of machine learning pipelines has been adopted by many applications including SparkML, Tensorflow, PMML, etc.
From now on, when we are talking about model serving, we will mean serving of the complete pipeline.
Public Interfaces
Model
In the heart of the Model Serving in Flink is an abstraction of model.The question here is whether it is necessary to introduce special abstractions to simplify usage of the model in Flink.
Our intention is to use model serving as an “ordinary” function, that can be used at any place of the stream processing. In addition to this we will expose a convenient DSL allowing for the user to define a user defined function (udf) to access the model and customize scoring.
For example we could have:
val joinedStream = dataStream.withModelServing(modelServingControlStream)
Then we could define a udf or execute the default prediction, joinedStream.predict{ (data,model) => // custom code} and joinedStream.predict() (could use fit, score or something else here for the name of the method).
The Model can be generically described using the following trait:
trait Model {
def score(input : AnyVal) : AnyVal
def cleanup() : Unit
def toBytes() : Array[Byte]
def getType : Long
}
The basic methods of this trait are:
Score is the basic method for the model implementation converting input data into a result or score,
Cleanup is a hook for a model implementer to release all of the resources, associated with the model execution - model lifecycle support
toBytes is a supporting method used for serialization of the model content (used for checkpointing)
GetType is a supporting method returning an index for the type of model used for finding the appropriate model factory class (see below)
Although trait is called model, what we actually mean here is not just a model but a complete machine learning pipeline.
Implementation options
The model trait can be implemented using a wide range of approaches and technologies. In order to minimize implementation options we propose to start with standards introduced by
Data Mining Group - Predictive Model Markup Language (PMML) and Portable Format for Analytics (PFA), both suited for description of machine learning pipelines.
In addition to these two standards we also want to support Tensorflow due its popularity for model building and serving.
Pipeline Metadata Definition
Because we are planning to support multiple implementation options for model, it is necessary to define a format for models representation in the stream that allows to support different kind of model’s representation. We decided to use google protocol buffers for model metadata representation. We start with option as an efficient generic way to integrate with the system but we might need to support other methods for making user experience better:
syntax = "proto3";
// Description of the trained model.
message ModelDescriptor {
// Model name
string name = 1;
// Human readable description.
string description = 2;
// The model id to use for correlating data records with this model
string dataType = 3;
// Model type
enum ModelType {
TENSORFLOW = 0;
TENSORFLOWSAVED = 1;
PMML = 2;
};
ModelType modeltype = 4;
oneof MessageContent {
// Byte array containing the model
bytes data = 5;
string location = 6;
}
}
The model here (model content) can be represented either inline as a byte array or as a reference to a location where the model is stored. In addition to the model data our definition contains the following fields:
Name - name of the model that can be used for monitoring or UI applications
Description - a human readable model description that can be used for UI applications
Data type - data type for which this model is applicable(our model stream can contain multiple different models, each used for specific data in the stream). See Chapter 3 for more details of this field utilization.
Model type - for now I define only three model types - PMML and two TensorFlow types - graph and saved models
We decided to use Scalapb for protobuf marshalling generation and processing. We might need to revise our choices as we want to make the system accessible to java users as well.
Model Factory
As defined above, a model in the stream is delivered in a form of Protobuf message, which can contain either a complete representation of the model or a reference to the model location. In order to generalise model creation from message, we are introducing additional trait - ModelFactory - supporting building models out of Model Descriptor. Additional use for this interface is support of serialization/deserialization in support of checkpointing. Model factory can be described using the following trait
trait ModelFactory {
def create(input : ModelDescriptor) : Model
def restore(bytes : Array[Byte]) : Model
}
The basic methods of this trait are:
Create - method creating model based on the Model descriptor
Restore - method to restore a model from a byte array emitted by the Model’s toByte method. These two methods need to cooperate to ensure proper functionality of ModelSerializer/ModelDeserializer
Data stream
Similar to the model stream, protobufs are used for the data feed definition and encoding. Obviously a specific definition depends on the actual data stream that you are working with.
syntax = "proto3";
// Description of the wine parameters.
message ...
// Data type for this record
string dataType = 12;
}
Note that a dataType field is added to both model and data definition. This field is used to identify the record type (in the case of multiple data types and models) in order to match it to the corresponding models.
In a simple case, it is possible to use a single concrete data type. If it is necessary to support multiple data types, either protobuf’s oneof construct can be used, if all the records are coming through the same stream, or if separate streams, managed using separate Kafka topics, can be introduced, a distinct data type can be defined by stream.
The proposed data type based linkage between data and model feeds works well when a given record is scored with a single model. If this relationship is one to many, where each record needs to be scored by multiple models, a composite key (data type with model id) can be generated for every received record.
Flink implementation Architecture
Flink provides low level stream processing operation - ProcessFunction which provides access to the basic building blocks of all (acyclic) streaming applications:
events (stream elements)
state (fault-tolerant, consistent, only on keyed stream)
timers (event time and processing time, only on keyed stream)
To realize low-level operations on two inputs, Flink provides Low-level Join operation which is bound to two different inputs (if we need to merge more than two streams it is possible to cascade multiple low level joins; additionally side inputs, scheduled for the upcoming versions of Flink would allow additional approaches to stream merging) and provides individual methods for processing records from each input. Implementing a low level join typically follows the following pattern:
Create and maintain a state object reflecting the current state of execution
Update the state upon receiving elements from one (or both) input(s)
Upon receiving elements from one or both input(s) use current state to transform data and produce the result
The following figure is a block diagram that illustrates this operation.

Figure 3. Flink’s low level join
This pattern fits well into the overall architecture that we want to implement.
Flink provides 2 ways of implementing low-level joins - key based join based on CoProcessFunction and partitions-based join based on RichCoFlatMapFunction. Although both can be used for required implementation, they provide different SLAs and are applicable for slightly different use cases.
Key-based joins
Flink’s CoProcessFunction allows key-based merge of 2 streams. When using this API, data is key-partitioned across multiple Flink executors. Records from both streams are routed (based on key) to the appropriate executor that is responsible for the actual processing.

Figure 4. Key Based join
The main characteristics of this approach:
Individual model’s scoring is implemented by a separate executor (a single executor can score multiple models), which means that scaling of Flink leads to a better distribution of individual models and consequently better parallelization of scorings.
A given model is always scored by a given executor, which means that depending on input records types distribution this approach can lead to “hot” executors
Partition-based joins
Flink’s RichCoFlatMapFunction allows merging of 2 streams in parallel (based on parallelization parameter). When using this API, on the partitioned stream, data from different partitions is processed by dedicated Flink executor. Records from model stream are broadcasted to all executors. As it can be seen from the figure below, each partition of the input stream, in this case is routed to its instance of model server. If the amount of partitions of the input stream is less than Flink parallelization factor, then only some of the model server instances will be utilized, if it is more, than some of the model server instances will serve more than one partition.
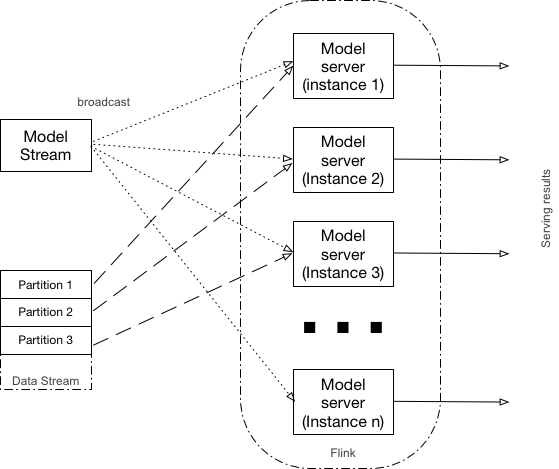
Figure 5. Partition based join
The main characteristics of this approach:
The same model can be scored in one of several executors based on the partitioning of the data streams, which means that scaling of Flink (and input data partitioning) leads to a better scoring throughput.
Because model stream is broadcasted to all executors, which operate independently, some racing conditions in the model update can exist, meaning that at the point of the model switch, some model jitter can occur.
Additionally, because the same model in this case is deployed to all executors, the amount of memory required to model deployment will grow proportionally as the amount of executors grow.
Selecting appropriate join type
When deciding on the appropriate join type consider the following:
Based on its implementation, key-based joins is an appropriate approach for the situations when we need to score multiple data types with relatively even distribution.
Based on its implementation partition-based joins is an appropriate approach for the situations when we need to score one (or small amount) model under heavy data load assuming that the data source is evenly partitioned. Also keep in mind that this approach requires more memory for models deployment.
Monitoring
Any streaming application, and model serving is no exception, requires well defined monitoring solution. An example of information that we might want to see for model serving application includes:
Which model is currently used
When it was installed
How many times models have been served
What are the average, min/max model serving times
Etc.
The basic information about model serving can be represented as follows:
case class ModelToServeStats(
name: String, // Model name
description: String, // Model descriptor
modelType: ModelDescriptor.ModelType, // Model type
since : Long, // Start time of model usage
var usage : Long = 0, // Number of servings
var duration : Double = .0, // Time spent on serving
var min : Long = Long.MaxValue, // Min serving time
var max : Long = Long.MinValue // Max serving time
)
This information can be calculated during model execution and then used for monitoring. The basic implementation for monitoring can done using different approaches, including logging, writing this information to database, etc.
Additional elegant solution for monitoring - queryable state - is present in Flink starting from version 1.2. Usage of queryable state allows to directly query the latest state of your stream processing application, without needing to materialize that state to external databases or external storage first.

This seems like an ideal solution for monitoring, but unfortunately works only for key-based joins.
Optimizations
There is space for optimizing the key-based solution to avoid the hot executor issue where all load of scoring is processed by one executor. One solution would be to serve more instances of a model. This can be done by sending down the model stream keys of the form data_type_model_A_key_1, data_type_model_A_key_2, etc...(we serve the same model here on different instances). We assume the first instance has key data_type_model_A_key_0.So when we scale we send new keys. Each executor which gets the full key for the first time will fetch/create the model as usual and store it locally.
The data stream should be joined by data_type with the same model stream (broadcast) one level up so the data key can be re-written randomly, to match the full key, before it arrives and at the operator where we store the data model. At that upper operator we keep state of the unique full model keys we have seen so far only.
We should send only once the new key at the top stream and if we see it for the first time fetch the model.
Note: For this to work we need to be careful with the partitioning done by Flink so that the composite key actually distributes the records to the appropriate models when hashing takes place.
Proposed Changes
Target is to add a new library over flink for model serving. This should be a useful tool that adds value to the flink ecosystem. Implementation for queryable operator state (for partition-based joins), is required for monitoring implementation (currently covered by https://issues.apache.org/jira/browse/FLINK-7771).
Compatibility, Deprecation, and Migration Plan
There are not backwards compatibility/migration/deprecation concerns since this only adds new API.
Rejected Alternatives
We discussed usage of Side Inputs for stream merging. It has 2 potential benefits:
Cleaner semantics for initial value of side inputs
Easier semantics for stream merging in the case of multiple (more than 2 streams)
Unfortunately, at the time of implementation, side inputs are not available, so implementation is leveraging low level joins, which do the job.
Speculative Model Serving
The main limitation of the solution presented above is a single model per data type, which is rarely the case in the real life deployments. As described in detail by Ted Dunning, in his Machine Learning Logistics book, in real life deployments, there is typically an ensemble of models scoring the same data item in parallel and then a decision block decides which result to use. Here we will describe an extension of proposed solution supporting speculative model serving.
Why speculative model serving?
According to Wikipedia, speculative execution is:
“an optimization technique where a computer system performs some task that may not be needed. Work is done before it is known whether it is actually needed, so as to prevent a delay that would have to be incurred by doing the work after it is known that it is needed. If it turns out the work was not needed after all, most changes made by the work are reverted and the results are ignored.
The objective is to provide more concurrency if extra resources are available. This approach is employed in a variety of areas, including branch prediction in pipelined processors, value prediction for exploiting value locality, prefetching memory and files” etc.
In the case of Model Serving, speculative execution means scoring data in parallel leveraging a set of models, then selecting the best score based on some metric.
Speculative model serving implementation
The generic implementation of speculative model serving can be presented as follows:

Here, instead of sending requests directly to the executor (model server) we send it to a special component - Starter. Starter's responsibility is to distribute these requests to known Executors, that process (implement model serving, in our case) these requests in parallel. Execution results are then send to Collector, responsible for determine final result based on the results calculated by individual Executors.
Such simple architecture allows to implement a lot of important model serving patterns including the following:
- Guaranteed execution time. Assuming that we have several models with the fastest providing fixed execution time, it is possible to provide a model serving implementation with a fixed upper-limit on execution time, as long as that time is larger than the execution time of the simplest model
- Consensus based model serving. Assuming that we have several models, we can implement model serving where prediction is the one returned by the majority of the models.
- Quality based model serving. Assuming that we have an metric allowing us to evaluate the quality of model serving results, this approach allows us to pick the result with the best quality. It is, of course, possible to combine multiple feature, for example, consensus based model serving with the guaranteed execution time, where the consensus result is used when it completes within a given time interval.
- "Canary" deployment, where some of requests are routed to the "new" executors.
Combining Speculative execution with "real time updatable" model serving, described earlier, leads to the following overall architecture:

It turns out that such architecture can be easily implemented on Flink (leveraging key-based joins), as presented below:

The implementation leverages three CoProcessFunction classes:
- Router processor implements starter. It receives both models and data streams (see above) and routes them to appropriate Model processor (leveraging side outputs), based on appropriate key. It also notifies Speculative processor about starting new data request processing. As an optimization, if there are no models available for a given data type, Pouter processor directly sends result ("no models available") to Speculative processor. Current implementation forwards request to all available Model processor, but can be overridden to implement required request distribution.
- Model processor directly follows implementation for key-based joins, described above.
- Speculative processor implements collector, presented above. Its implementation relies on "decider", which represents an interface (see below), that have to be implemented based on specific set of requirements.
In addition to the above the following extensions to the model are introduced for this implementation:
- Additional case classes describing additional messages:
case class ServingRequest(GUID : String, data : AnyVal)
case class ServingQualifier(key : String, value : String)
case class ServingResponse(GUID : String, result : ServingResult, confidence : Option[Double] = None, qualifiers : List[ServingQualifier] = List.empty)
case class SpeculativeRequest(dataModel : String, dataType : String, GUID: String, data: AnyVal)
case class SpeculativeModel(dataModel : String, model : ModelToServe)
case class SpeculativeServiceRequest(dataType : String, dataModel : String, GUID: String, result : Option[ServingResult], models: Int = 0) - Decider interface used for selecting results:
trait Decider {
def decideResult(results: CurrentProcessing): ServingResult
}
case class CurrentProcessing(dataType : String, models : Int, start : Long, results : ListBuffer[ServingResponse])
Monitoring
This implementation leverages monitoring approach based on a queryable state (same as above). In addition to ModelServiceStats (per model) this implementation also exposes two additional pieces of information:
- List of available models (per data type) - List[String]
SpeculativeExecutionStats describing statistics on the speculative execution:
final case class SpeculativeExecutionStats(
var name: String,
decider : String,
tmout: Long,
since: Long = System.currentTimeMillis(),
usage: Long = 0,
duration: Double = 0.0,
min: Long = Long.MaxValue,
max: Long = Long.MinValue
Implementation
An initial implementation and examples for this Flip, they include just basic model serving implementation without speculative piece. Implementation is provided in both Scala and Java. It Implements both key-base and partition-base joins and Tensorflow support for both "optimized" and saved formats. Implementation is split into 2 part:
Library implementation
This is implementation of the base library independent from the type of the messages that particular solution is using. It is strongly typed, implemented using generics. Library implementation includes 3 modules:
Here Flink Model Serving shared contains protobuf definition (see Pipeline Metadata Definition above) And Flink model serving Java and Flink model serving Scala provides the same implementation in both Java and Scala. Theoretically it is possible to combine the two, but Java and Scala syntax is sufficiently different, so the 2 parallel implementations are provided.
In addition to this both Java and Scala implementation contain a set of unit tests for validating implementation
Flink Model Serving Java
The implementation is contained in the namespace *org.apache.flink.modelserving.java*, which contains 3 namespaces:
- model - code containing definition of model and its transformation implementation
- query - code containing base implementation for the Flink queryable state query
- server - code containing basic implementation of the Flink specific components of the overall implementation
Model implementation is split into generic and tensorflow based implementation, such implementation allows to add other model types support in the future without disrupting the base code. Generic model implementation includes the following classes:
- DataConverter - a set of model transformation methods
- DataToServe - a trait defining generic container for data used for model serving and its behavior
- Model - a trait defining generic model and its behavior (see above)
- ModelFactory - a trait defining generic model factory and its behavior (see above)
- ModelFactoriesResolver - a trait defining generic model factory resolver and its behavior. The purpose of this trait is to get the model factory based on the model type.
- ModelToServe - an intermediate representation of the model
- ModelToServeStats - model usage statistics
- ModelWithType - a combined container for model and its type used by Flink implementation
- ServingResult - generic representation of model serving result
A tensorflow namespace inside model namespace contains 4 classes:
- TensorFlowModel extends Model by adding Tensorflow specific functionality for the case of optimized Tensorflow model
- TensorBundelFlowModel extends Model by adding Tensorflow specific functionality for the case of bundled Tensorflow model
- TField a definition of the field in the tensorfow saved model
- TSignature a definition of the signature in the tensorfow saved model
Query namespace contains a single class - ModelStateQuery - implementing Flink Queryable state client for the model state
Server namespace contains 3 namespaces:
- Keyed - contains DataProcessorKeyed - implementation of the model serving using key based join (see above) and based on Flink's CoProcessFunction
- Partitioned - contains DataProcessorMap - implementation of the model serving using partion based join (see above) and based on Flink's RichCoFlatMapFunction
- Typeshema contains support classes used for type manipulation and includes the following:
- ByteArraySchema - deserialization schema for byte arrays used for reading protobuf based data from Kafka
- ModelTypeSerializer - type serializer used for checkpointing
- ModelSerializerConfigSnapshot - type serializer snapshot configuration for ModelTypeSerializer
- ModelWithTypeSerializer - type serializer used for checkpointing
- ModelWithTypeSerializerConfigSnapshot - type serializer snapshot configuration for ModelWithTypeSerializer
Flink Model Serving Scala
The implementation provides identical functionality to the Java one and is contained in the namespace org.apache.flink.modelserving.scala, which contains 3 namespaces:
- model - code containing definition of model and its transformation implementation
- query - code containing base implementation for the Flink queryable state query
- server - code containing basic implementation of the Flink specific components of the overall implementation
Model implementation is split into generic and tensorflow based implementation, such implementation allows to add other model types support in the future without disrupting the base code. Generic model implementation includes the following classes:
- DataToServe - a trait defining generic container for data used for model serving and its behavior
- Model - a trait defining generic model and its behavior (see above)
- ModelFactory - a trait defining generic model factory and its behavior (see above)
- ModelFactoryResolver - a trait defining generic model factory resolver and its behavior. The purpose of this trait is to get the model factory based on the model type.
ModelToServe defines additional case classes used for the overall implementation and a set of data transformations used for model manipulation and transforming it between different implementations. Additional classes included here include ServingResult - a container for model serving result; ModelToServeStats - model to serve statistics (see above) and ModelToServe - internal generic representation of the model
- ModelWithType - a combined container for model and its type used by Flink implementation
A tensorflow namespace inside model namespace contains 2 abstract classes:
TensorFlowModel extends Model by adding Tensorflow specific functionality for the case of optimized Tensorflow model
- TensorBundelFlowModel extends Model by adding Tensorflow specific functionality for the case of bundled Tensorflow model
Query namespace contains a single class - ModelStateQuery - implementing Flink Queryable state client for the model state
Server namespace contains 3 namespaces:
- Keyed - contains DataProcessorKeyed - implementation of the model serving using key based join (see above) and based on Flink's CoProcessFunction
- Partitioned - contains DataProcessorMap - implementation of the model serving using partion based join (see above) and based on Flink's RichCoFlatMapFunction
- Typeshema contains support classes used for type manipulation and includes the following:
- ByteArraySchema - deserialization schema for byte arrays used for reading protobuf based data from Kafka
- ModelTypeSerializer - type serializer used for checkpointing
- ModelWithTypeSerializer - type serializer used for checkpointing
Example implementation
This is implementation of the a wine quality example based on the above library. Implementation includes 3 modules:
Implementation demonstrates how to use library to build Flink Model serving implementation.
When building a new implementation you first need to define data that is used for model serving. An example is using wine quality example. Data definition is for wine is provided in model serving example shared. We are using protobuf encoding for data here, but other encoding can be used as well. Additionally Shared namespace contains implementation of embedded Kafka server (for local testing) and a Kafka provider periodically publishing both data and model, that can be used for testing the example.
There are two implementations of example - Java and Scala, that works exactly the same but are using corresponding version of Library.
Lets walk through the Scala implementation. It is located in the namespace org.apache.flink.examples.modelserving.scala and is comprised of three namespaces:
- Model
- Query
- Server
Model namespace contains three classes, extending library and implementing specific operations for a given data type.
- WineTensorFlowModel extends TensorFlowModel class by implementing processing specific to Wine quality data
- WineTensorFlowBundeledModel extends TensorFlowBundelModel class by implementing processing specific to Wine quality data
- WineFactoryResolver extends ModelFactoryResolver class by specifying above two classes as available factories
Server namespace implements 2 supporting classes : DataRecord implementing DataToServe trait for Wine type and BadDataHandler - simple data error handler implementation
It also provides complete Flink implementation for both key based join (ModelServingKeyedJob) and partition base join (ModelServingFlatJob).
To run the example first start org.apache.flink.examples.modelserving.client.client.DataProvider class, that will publish both data and model messages to Kafka (to test that publication works correctly you can use org.apache.flink.examples.modelserving.client.client.DataReader; do not forget to stop it before you proceed). Once data provider is running you can start actual model serving (ModelServingKeyedJob or ModelServingFlatJob). If you are using keyed version, you can also run ModelStateQueryJob from the query namespace to see execution statistics (Flink only supports query for keyed join). When running query, do not forget to update jobID with the actual ID of your run