Status
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
Generally speaking, applications may consist of one or more jobs, and they may want to share the data with others. In Flink, the jobs in the same application are independent and share nothing among themselves. If a Flink application involves several sequential steps, each step (as an independent job) will have to write its intermediate results to an external sink, so that its results can be used by the following step (job) as sources.
Although functionality-wise this works, this programming paradigm has a few shortcomings:
- In order to share a result, a sink must be provided.
- Complicated applications become inefficient due to a large amount of IO on the intermediate results.
- User experience is weakened for users using programming API (SQL users are not victims here because the temporary tables are created by the framework)
It turns out that interactive programming support is critical to the user experience on Flink in batch processing scenarios. The following code gives an example:
Table a = ….
Table b = a.select(...).filter(...)
Integer max = b.orderBy($("val").desc()).limit(1).execute().collect().next().getField(...)
Integer min = b.orderBy($("val").asc()).limit(1).execute().collect().next().getField(...) // recompute table b from table a
Table e = b.select("(f1 - min)/(max - min)").filter(...)
e.execute().print() // recompute table b from table a
...
If (b.count() > 10) { // recompute table b from table a
b.select(UDF1(...)).execute().print()// recompute table b from table a
} else {
b.select(UDF2(...)).execute().print()
}
In the above code, because b is not cached, it will be computed from scratch multiple times whenever referred later in the program.
To address the above issues, we propose to add support for interactive programming in Flink Table API.
Public Interfaces
Table API
1. Add the following two new methods to the Flink Table class.
/**
* Cache this table to builtin table service or the specified customized table service.
*
* This method provides a hint to Flink that the current table maybe reused later so a
* cache should be created to avoid regenerating this table.
*
* The following code snippet gives an example of how this method could be used.
*
* {{{
* Table t = tEnv.fromCollection(data).as('country, 'color, 'count)
*
* CachedTable t1 = t.filter('count < 100).cache()
* // t1 is cached after it is computed for the first time.
* t1.execute().print()
*
* // When t1 is used again to compute t2, it may not be re-computed.
* Table t2 = t1.groupBy('country).select('country, 'count.sum as 'sum)
* t2.execute().print()
*
* // Similarly when t1 is used again to compute t3, it may not be re-computed.
* Table t3 = t1.groupBy('color).select('color, 'count.avg as 'avg)
* t3.execute().print()
*
* }}}
*
* @note Flink optimizer may decide to not use the cache if doing that will accelerate the
* processing, or if the cache is no longer available for reasons such as the cache has
* been invalidated.
* @note The table cache could be create lazily. That means the cache may be created at
* the first time when the cached table is computed.
* @note The table cache will be cleared when the user program exits.
* @note This method is only supported in batch table and it is treated as No-Op for stream table
*
* @return the current table with a cache hint. The original table reference is not modified
* by the execution of this method. If this method is called on a table with cache
* hint, the same table object will return.
*/
CachedTable cache();
2. Add a CachedTable interface extend Table
public interface CachedTable extends Table {
/**
* Manually invalidate the cache of this table to release the physical resources. Users are
* not required to invoke this method to release physical resource unless they want to. The
* table caches are cleared when user program exits.
*
* @note After invalidated, the cache may be re-created if this table is used again.
*/
void invalidateCache();
}
3. Add a close method to the TableEnvironment
/** * Close and clean up the table environment. All the * table cache should be released physically. */ void close();
Proposed Changes
Cache intermediate results
As mentioned in the motivation section. The key idea of the FLIP is to allow the intermediate process results to be cached, so later references to that result do not require duplicate computation. To achieve that, we need to introduce Cached Tables.
The cached tables are tables whose contents are saved by Flink as the user application runs. A cached Table can be created in the following way:
Explicit caching
- Users can call cache() method on a table to explicitly tell Flink to cache a Table.
- The cache() method returns a new CachedTable object.
- The cache() method does not execute eagerly. Instead, the table will be cached when the DAG that contains the cached table runs.
Semantic of cache() method
TableEnvironment tEnv = ... Table t1 = ... CachedTable t2 = t1.cache() ... t2.execute().print() // t1 is cached. Table t3 = t1.select(...) // cache will NOT be used. Table t4 = t2.select(...) // cache will be used. ... t2.invalidateCache() // cache will be released ... t2.execute().print() // cache will be recreated
Scope of the cached result
The cached tables are available to the user application using the same TableEnvironment.
Release the cached results
The cached intermediate results will consume some resources and need to be released eventually. The cached result will be released in two cases.
User application exits
When TableEnvironment is closed, the resources consumed by the cached tables will also be released. This usually happens when user application exits.
Explicit invalidateCache() invocation
Sometimes users may want to release the resource used by a cached table before the application exits. In this case, users can call invalidateCache() on a table. This will immediately release the resources used to cache that table.
Implementation Details
To let the feature available out of the box, a default file system based cache service will be provided, which utilizes the cluster partition implemented in FLIP-67. This section describes the implementation details of the default table service.
Although the implementation details are transparent to the users, there are some related changes to make the default implementation work.
Default Intermediate Result Storage (Phase 1)
Intermediate result reuse
The architecture is illustrated below:
Each cached table consists of two pieces of information:
- Table metadata - name, location, etc.
- Table contents - the actual contents of the table
The metadata of the cached table is stored in the client (e.g. CatalogManager) and the actual contents are stored in the Task Managers as cluster partitions(FLIP-67).
The end to end process is the following:

Step 1: Execute JOB_1 (write cached tables)
- Users call table.cache(), the client
- Wrap the operation of the table with CacheOperation. The CacheOpeartion contains a generated IntermediateResultId
- While translating the operations to rel nodes, the planner adds a CacheSink, which contains the IntermediateResultId, to the cached node in the DAG. By adding a sink to the cached node, we can make sure that the optimizer would not affect the cached node
- The CacheSink is treated as a normal sink when the planner optimizes and translates the rel nodes to transformation
- When the Executor(StreamGraphGenerator) translates the transformation to stream graph, it recognizes the CacheSink, removes the CacheSink, and sets the cache flag of the upstream node.
- If the StreamingJobGraphGenerator see the node with the cache flag set, it sets the result partition type to BLOCKING_PERSISTENT
- The client submits the job
- JobMaster executes the job as usual. After the job finishes, the TaskExecutor promotes the BLOCKING_PERSISTENT result partitions to cluster partitions instead of releasing them (Implemented in FLIP-67)
- After the job finishes, JobMaster reports the information of the cluster partition (ClusterPartitionDescriptor) back to the client in form of a mapping of [IntermediateDataSetId -> [ClusterPartitionDescriptor]]
- The ClusterPartitionDescriptor should include a ShuffleDescriptor and some metadata, i.e. numberOfSubpartitions and partitionType
- The ClusterPartitionDescriptor will be serialized before sending back to the client via JobResult and only be deserialized in the StreamingJobGraphGenerator
- The CatalogManager in the table environment maintain the mapping of CachedTable -> (IntermediateResultId, [ClusterPartitionDescriptor])
Step 2: Execute JOB_2 (read cached tables)
- Later on, when the client submits another job whose DAG contains a CacheOperation, the planner
- looks up the available intermediate results in the CatalogManager
- creates a Source node(CacheSource) that contains the ClusterPartitionDescriptor
- replace the subtree of the cached node with the source node created
- The CacheSource is treated as a normal source when the planner optimizes and translates the rel nodes to transformation
- looks up the available intermediate results in the CatalogManager
- The StreamGraphGenerator recognizes the CacheSource, includes the ClusterPartitionDescriptor in the StreamNode, and sets the operator/driver to NoOp.
- When the StreamingJobGraphGenerator sees the StreamNode that contains the ClusterPartitionDescriptor, it will include the ClusterPartitionDescriptor in the JobVertex.
- The parallelism is set to the maximum number of subpartitions among the cluster partitions to ensure that all the subpartitions are read by the NoOp vertex
- The clients submit the job
- JobMaster does the following if the JobVertex contains the ClusterPartitionDescriptor
- It assumes Scheduler understands the cluster partition location
- Create InputGateDeploymentDescriptor with the ShuffleMaster
- assign the result partitions to each subtask based on locality
- Task managers will run the given tasks as usual
Clean up
- When the application exits, all the Task Managers will exit and the intermediate results will be released.
Invalidate intermediate results
- Users invoke CachedTable.invalidateCache()
- Clients remove the intermediate result entry in the TableEnvironment.
- Clients delete the corresponding cluster partitions with the REST API provided in FLIP-67.
- The cluster partitions will then be released by the Task Managers that hold the cluster partitions.
Please refer to FLIP-67 for the implementation detail of steps 2 and 3.
ClusterPartitionDescriptor
The ClusterPartitionDescriptor should have the necessary information to let another job to be able to consume the intermediate result. It includes the ShuffleDescriptor, along with some metadata about the intermediate result, i.e., numberOfSubpartitions, partitionType, and the IntermediateDataSetID. Since it contains the runtime class ShuffleDescriptor, it should not put into the flink-core module. Instead, it will get serialized before transfer back to the client-side, and only get deserialized in the StreamingJobGraphGenerator. We can put a ClusterPartitionDescriptor interface in the flink-core, and keep the implementation of the ClusterPartitionDescriptor in the flink-runtime. The JobResult contains the SerializedValue<ClusterPartitionDescriptor> will get sent back to the client-side.
Repartition
Repartition is needed when the cache consumer requires the input data to be partitioned in a specific way, i.e. hash partition, custom partition. When the StreamingJobGraphGenerator generates the job graph, it introduces a NoOp job vertex as the upstream vertex of the cache consumer and maintains the shipStrategyName of the output job edge. During execution, the task executor will make sure that the data is repartitioned.
Failover
If a Task Manager instance fails, Flink will bring it up again. However, all the intermediate results which have a partition on the failed TM will become unavailable.
In this case, the consuming job will throw an exception and the job will fail. As a result, PartitionTracker in ResourceManager will release all the cluster partitions that are impacted(implemented in FLIP-67). The TableEnvironment will fell back and resubmit the original DAG without using the cache. The original DAG will run as an ordinary job that follows the existing recovery strategy. Note that because there is no cache available, the TableEnvironment (planner) will again create a Sink to cache the result that was initially cached, therefore the cache will be recreated after the execution of the original DAG.
The above process is transparent to the users.
Cache in Per-Job Mode
In the per-job mode cluster, a cluster will be spun up on every submitted job and tore down when the submitted job finished. All lingering resources (files, etc) are cleared up, including the cluster partition in the TMs. Therefore, the cached table will not work in the Per-Job mode cluster. When a job that read from some cached table is submitted in Per-Job mode, the first submission of the job will fail and the failover mechanism will re-execute the origin DAG.
Impact of optimization
To explain how the optimizer affects the cache node, let look at a very simple DAG, where one scan node followed by a filter node, as shown below. The optimizer can push the filter to the scan node such that the scan node will produce fewer data to the downstream node. However, such optimization will affect the result of the scan node, which is an undesired behavior if we want to cache the scan node.
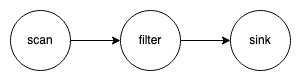
To solve the problem above, when users explicitly cache a table, we will change the DAG implicitly by adding a special sink node to the cache table, as shown below. By doing this, we are able to ensure that the result of the cache node will not be affected by the optimizer and we can identify the job vertex that produces the cache table in StreamingJobGraphGenerator by the special sink. With Blink planner, when a DAG has multiple sinks, the multi sink optimization will break the DAG into multiple RelNodeBlocks, the cache node will be the output node of one of those RelNodeBlocks. In our example, it will be broken into three RelNodeBlocks. Then, the optimizer will run independently on each of those RelNodeBlocks so that the optimizer will not affect the result of the cache node.

Future works
SQL integration
The most intuitive way to use the cache table with SQL is to create a temporary view. We can introduce a new keyword CACHED and combine it with the CREATE TEMPORARY VIEW syntax. For example, the following SQL will register the CachedTable Object in the Catalog. And the later SQL statement can refer to the temporary view in order to use the cache table. Such syntax should align well with the caching in the Table API, as the following SQL has a similar effect of running tEnv.registerTemporaryView("CachedTable", table.cache()) in Table API.
CREATE CACHE TEMPORARY VIEW CachedTable AS SELECT *
Add cache to DataStream API
As of now DataStream only supports stream processing. There is some idea of supporting both Stream and Batch (as finite stream) in DataStream. Once we do that, we can add the cache API to DataStream as well.
Cache a stream table
Theoretically speaking, users can also cache a streaming table. The semantic will be storing the result somewhere (potentially with a TTL). However, caching a streaming table is usually not that useful. For simplicity, we would not support stream table caching in the first implementation. When cache() is invoked on a stream table, it will be treated as a No-Op. This leaves us room to add caching for stream tables in the future without asking users to change their code.
Cache Eviction
The cached table utilizes the cluster partition implemented in FLIP-67 to store the intermediate result in the TMs. Therefore, it is possible that the TM could run out of space to hold the intermediate result if clients cache too many tables without releasing. When it happens, the job will fail with an exception. For simplicity, we would not implement an automatic mechanism to handle such failure in the first implementation. For now, it is up to the user to decide what to do when the failure happens. In the future, we could introduce some kind of eviction policy to release some cluster partition when the failure happens and re-run the job.
Compatibility, Deprecation, and Migration Plan
This FLIP proposes a new feature in Flink. It is fully backward compatible.
Implementation Plan
Change needed
In order to implement the cache table, the following changes are needed.
Client
- Add IntermediateDataSetID to StreamTransformation and Operator
- CatalogManager stores the Table → (IntermediateResultId, [ClusterPartitionDescriptor]) mapping
- Planner replaces the source of the cached node before optimization
- Planner adds a sink to the node that should be cached
- StreamGraphGenerator modifies the stream graph and sets the flag of the cache node accordingly
- StreamingJobGraphGenerator sets the result partition type and ClusterPartitionDescriptor of the JobVertex.
Runtime
- JobMaster reports IntermediateDataSetID to ClusterPartitionDescriptor mapping to Client.
- JobMaster can generate InputGateDeploymentDescriptor base on the ClusterPartitionDescriptor in the JobVertex.
Plan
The implementation should proceed in the following way, some of which can proceed concurrently:
- Implementation in Runtime
- The ClusterPartitionDescriptors can generated and put into the JobResult.
- By using the ClusterPartitionDescriptor in step 1.a, we can execute a Job that reads from the cluster partition.
- Implementation in StreamGraphGenerator and StreamingJobGraphGenerator
- Given the CacheSouce and CacheSInk, the JobGraph generated by the StreamingJobGraphGenerator has the ClusterPartitionDescriptor or have the ResultPartitionType set correctly.
- Implementation in Planner
- Given an Operation Tree with CacheOperation, it can replace the cache node with CacheSource accordingly or add a CacheSink to the cache node.
- Implementation in TableEnvironment/Table
- Implement the public-facing classes.
- CatalogManager can store the ClusterPartitionDescriptor of the cached node.
Test Plan
Unit tests and Integration Tests will be added to test the proposed functionalities.
Rejected Alternatives
The semantic of the cache() / invalidateCache() API has gone through extended discussions. The rejected alternative semantics are documented below:
Rejected API Option 1
API
// Do not return anything void cache(); // Alternatively, return the original table for chaining purpose. Table cache(); // Physically uncache the table to release resource void uncache(); // To explicitly ignore cache, not part of this proposal but in the future Table hint(“ingoreCache”)
Semantic
TableEnvironment tEnv = ... Table t = … ... // cache the table t.cache(); … // Assume some execution physically created the cache. tEnv.execute() ... // The optimizer decide whether the cache will be used or not. t.foo(); ... // Physically release the cache. t.uncache();
Pros
Simple and intuitive, users only need to deal one variable of Table class
Cons
Side effect: a table may be cached / uncached in a method invocation, while the caller does not know about this.
Side Effect Option 1{ Table t = … // cache the table t.cache(); ... // The cache may be released in foo() foo(t); ... // cache is no longer available t.bar() } void foo(Table t) { // cache the table t.cache(); …. // Physically drop the table t.uncache(); }
Rejected API Option 2
API
// Return a CacheHandle
CacheHandle cache();
public interface CacheHandle {
// Physically release cache resource
void release();
}
Semantic
TableEnvironment tEnv = ... Table t = … ... // cache the table CacheHandle handle1 = t.cache(); CacheHandle handle2 = t.cache; … // Assume some execution physically created the cache. tEnv.execute() ... // Optimizer decide whether cache will be used. t.foo(); ... // Release the first handle, cache will not be released because handle 2 has not been released handle1.release(); // Release the second handle, the cache will be released because all the cache handle have been released. handle2.release();
Pros
No side effect
Users only deal with the variable.
Easy to add auto caching.
Cons
The behavior of t.foo() changes after t.cache(), the concern is that this is considered as “modifies” table t, which is against the immutable principle.