Status
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
Problem:
We experience some unexpected increase of data sent over the network for broadcasts with increasing number of slots per task manager.
We provided a benchmark [1]. It not only increases the size of data sent over the network but also hurts performance as seen in the preliminary results below. In this results cloud-11 has 25 nodes and ibm-power has 8 nodes with scaling the number of slots per node from 1 - 16.
suite | name | median_time |
broadcast.cloud-11 | broadcast.01 | 8796 |
broadcast.cloud-11 | broadcast.02 | 14802 |
broadcast.cloud-11 | broadcast.04 | 30173 |
broadcast.cloud-11 | broadcast.08 | 56936 |
broadcast.cloud-11 | broadcast.16 | 117507 |
broadcast.ibm-power-1 | broadcast.01 | 6807 |
broadcast.ibm-power-1 | broadcast.02 | 8443 |
broadcast.ibm-power-1 | broadcast.04 | 11823 |
broadcast.ibm-power-1 | broadcast.08 | 21655 |
broadcast.ibm-power-1 | broadcast.16 | 37426 |
After looking into the code base it, it seems that the data is deserialized only once per TM, but the actual data is sent for all slots running the operator with broadcast vars and just gets discarded in case it’s already deserialized.
We do not see a reason the data can't be shared among the slots of a TM and therefore just sent once.
[1] https://github.com/TU-Berlin-DIMA/flink-broadcast
Public Interfaces
Not yet clear.
Proposed Changes
There are several ways to achieve a solution. Here I will explain my thought process:
Current State
Instead of gathering the data only into one slot, we send it to each slot of the task manager in a “pull” fashion.

Also note that instead of having as many intermediate results per task manager as target tasks, we have that times the number of slots. Which means a high number of additional connections and setup overhead. Without that overhead it would look like this:

The RecordWriter will ask the OutputEmitter to which channel it should emit records. In the broadcast case, the OutputEmitter will return “write to all available slots”.

General solution approach:
I first try to avoid to change connections, but instead just try to prevent sending unnecessary messages.
First Approach - Naive
Tell OutputEmitter how many task managers there are and return the same amount of channels:
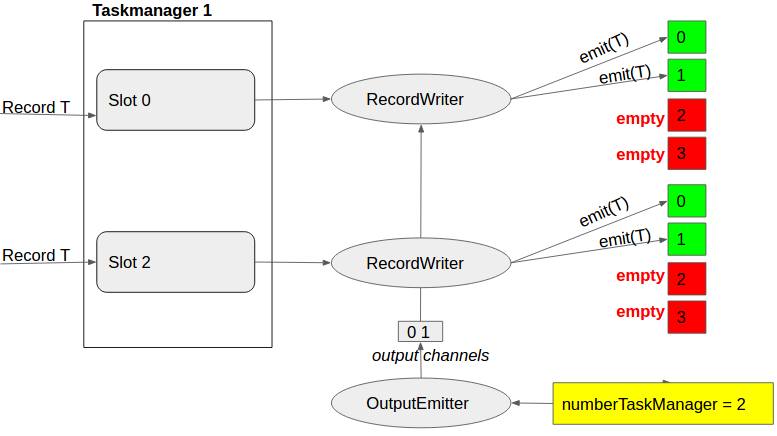
This will lead to the following communication scheme:

As you see this is exactly what we want. We only send everything once. The red dashed lines mean that the task tries to read but recognizes immediately that the input slot is empty.
In order to make this possible we also need to chance BroadcastVariableMaterialization. Because if we start to read the wrong slot, we will skip the data. To prevent this we will start to read all slots and if we recognize that the channel is empty we wait until the data is materialized on the other channel of the task manager:
data = read(slot_i);
if (!data.empty()) {
materialize();
} else {
wait until materialized();
}
Experiments showed that this different approach to handle BroadcastVariableMaterialization alone saves 50% of the execution time for an iterative workload without reducing messages.
This approach works for a simple map().withBroadcastSet(). But it turns out that scheduling for native iterations is less predictable. So we can also end up with the following scenario:

Second Approach - Tell each task its TaskManagerID
The scheduler knows about all available task managers. When a new task is scheduled it will also be informed about its task manager. The ID of the task manger will be within 0 to N-1 (N= number of available task managers). So when BroadcastVariableMaterialization is trying to read we will overwrite the slot by the task manager id:

Drawback: Maybe you already see the problem here. If Taskmanager 1 finishes before Taskmanager 2. The task 1 with slot 1 thinks that it can already start the Map operation since it thinks the materialization is completed. But the task 1 is executed on the other task manager so we get an exception.
There are multiple solutions to resolve this issue. We can wait as long as all slots are either empty or finished. This can be implemented by adding the function hasNext() in the ReaderIterator which doesn’t already pull the first record.
Third Approach - Pass each task a list of one assigned slot per task manager
With this approach we tell the OutputEmitter exactly which of the slots are required.
Problem: Scheduling is done in parallel. When some of the tasks are already deployed some other tasks are not even scheduled yet. So I haven’t found a way yet to predict on which slot the task will run. This is necessary to find one unique slot per task manager.
Fourth Approach - Just read once
After Stephan’s interesting email (http://mail-archives.apache.org/mod_mbox/flink-dev/201607.mbox/%3CCANC1h_vtfNy6LuqjTJ3m0ZZvZQttkYO9GdTNshchhv=eO9cV8w@mail.gmail.com%3E), I implemented part of his idea. This idea mostly affects the BroadcastVariableMaterialization. Instead of reading from all input slots we will only read the first upcoming input slot and save the same Reader in the BroadcastVariableManager. So if it is an iterative workload in the next iteration we will use the very same reader. Since we don’t know which input slot will be the slot we actually read from we will write to all input slots to be save. So there is still some overhead here. But we gain by not sending unnecessary data. The design looks like this:

Locally this approach works already for a small number of iterations (=170 iterations, don’t ask me yet, why it stops there). On the cluster it fails. I still need to investigate where the problem is.
Possible issues:
We don’t release the non-read slots properly
- We need to introduce synchronization after every iteration to prevent early releasing
Fifth Approach - Write broadcast data to one blocking subpartition only
This approach writes the broadcast data only to one blocking subpartition. So there is no data redundancy and no unnecessary network traffic. In order to make the broadcast subpartitions blocking we modify the job graph generation accordingly.

This approach currently does not work for native iterations (see https://issues.apache.org/jira/browse/FLINK-1713).
In the case of a simple Map().withBroadcastSet() we achieve the following results on the IBM-cluster:
suite | name | average_time (ms) |
broadcast.ibm-power-1 | broadcast.01 | 6597.33 |
broadcast.ibm-power-1 | broadcast.02 | 5997 |
broadcast.ibm-power-1 | broadcast.04 | 6576.66 |
broadcast.ibm-power-1 | broadcast.08 | 7024.33 |
broadcast.ibm-power-1 | broadcast.16 | 6933.33 |
You can see that the run time stays constant, which is exactly what we want. So the next step is to extend iterations to make it work in general.
But there was also an error with this approach. We create subpartitions which are not used. Subpartitions are only released when they are consumed. So with this approach we produce a memory leak.
Sixth Approach - Use one subpartition only
With this approach we only create one subpartition per task / slot. To make this possible we have to redirect all execution edges accordingly.

Now we have to figure out when to release the blocking partition.
Of each task manager one task will read the subpartition and send a release message to the subpartition when finished. The other tasks which don't read just sent a "I am done" message to the subpartition. We know the number of tasks, so we know when every task is finished.
This approach currently does not work for native iterations (see https://issues.apache.org/jira/browse/FLINK-1713).
In the case of a simple Map().withBroadcastSet() we achieve the following results on the IBM-cluster:
suite | name | average_time (ms) |
broadcast.ibm-power-1 | broadcast.01 | 6433 |
broadcast.ibm-power-1 | broadcast.02 | 6162.66 |
broadcast.ibm-power-1 | broadcast.04 | 6459 |
broadcast.ibm-power-1 | broadcast.08 | 6635.66 |
broadcast.ibm-power-1 | broadcast.16 | 7002.66 |
Compatibility, Deprecation, and Migration Plan
...
Test Plan
...
Rejected Alternatives
...