Overview
Geode is main memory based data management solution. Given its shared-nothing architecture, each member node is self-sufficient and independent. Each node manages its data set in memory and on local disk. While share-nothing reduces contention across the system, it has some limitations too. In many in-memory use cases, a small fraction of data is accessed frequently. Managing this subset in memory improves application's performance. However there are some infrequent analytical jobs accessing full dataset. Full data scans can cause eviction of critical data from memory. It can also increase response latency by contending for network resources. It is desired that analytical jobs do not impact online application. So an alternative access method for analytical workloads can be put forward.
A persistence store based on HDFS could be used to address some of the issues discussed above. HDFS provides economical, reliable, scalable and high performance storage layer. Together with the Hadoop ecosystem, it has transformed the way data is shared and analyzed by various data management systems. Region data persisted on HDFS could be accessed directly from HDFS without impacting cluster performance.
Like Geode DiskStore we introduce HdfsStore as a means to persist region data on HDFS. This document discusses HdfsStore management API and behavior. We assume the reader is familiar with Regions, Members, gfsh etc.
Goals
- Offline Geode data access, using custom InputFormat designed for Geode.
- Support all features using region iterators on Hdfs regions.
- Use Geode for data ingestion while caching recent data in memory.
- Hdfs data loader
- High performance Hdfs reads
Anti-Goals
- Secondary indexes on data archived on HDFS.
- Eviction logic will be based on LRU.
- Eviction may cause keys to be evicted from memory. Supporting features depending on in-memory keys may not work
- Replicated HdfsRegions
Design
Geode will provide a new type of persistence store, HdfsStore. Regions using HdfsStore will be referred to as HdfsRegions in this document. Data update operations related to HdfsRegions will be buffered in an asynchronous queue, referred as HdfsBuffer. Periodically the buffer data will be written on Hdfs. For reliability HdfsBuffers can be persisted on local disks. Region data will also be cached in memory for performant access. Since memory is finite, records will be evicted from memory when needed. However these records are never destroyed from HDFS. Hence full record of all events is present on HDFS. In case of a cache miss, a lookup on HDFS is executed and the data is loaded in memory.
- Each write operation will be cached in-memory and HDFS buffers simultaneously.
- A new/updated record may result in LRU eviction of existing data
Read-Write HdfsRegion
The update log managed on HDFS is similar to the oplog (operational log) maintained on local disk. Within the oplogs, the records are sorted on key. Each oplog on Hdfs is also augmented with metadata including some indexes, bloom filters, etc. Sorting and metadata speeds up HDFS reads. For the same performance reasons, metadata will be cache in memory. Such a region will be called Read-Write HfdsRegion
Write-Only HdfsRegion
In some cases, HDFS read may not be needed. For e.g. if Geode is used for micro-batch ingestion. If so overhead of sorting data within oplogs and managing metadata is unnecessary. Such a region will be referred to as Write-Only HdfsRegion.
Offline Access
Geode will also persist region related metadata on Hdfs. Geode will also provide utility readers to parse the metadata and iterate over region files on Hdfs. Using these utilities external tools will be able to consume region data even if Geode is offline.
Put KV
Get K
HDFS Store
HDFS stores provide a means of persisting data on HDFS. There can be multiple instance of HDFS stores in a cluster. A user will normally perform the following steps to enable HDFS persistence for a region:
- [Optional] Creates a Disk store for buffer reliability. HDFS buffers will use local persistence till it is persisted on HDFS.
- Creates a HDFS Store
- Creates a Region connected to HDFS Store
- Uses region API to create and query data
Key attributes of a HDFS Store
Attribute | Alterable? | Purpose |
|---|---|---|
Name | no | A unique identifier for the HDFSStore |
NameNodeURL | no | HDFSStore persists data on a HDFS cluster identified by cluster's NameNode URL or NameNode Service URL. NameNode URL can also be provided via hdfs-site.xml (see HDFSClientConfigFile). If the NameNode url is missing HDFSStore creation will fail. HDFS client can also load hdfs configuration files in the classpath. NameNode URL provided in this way is also fine. |
HomeDir | no | The HDFS directory path in which HDFSStore stores files. The value must not contain the NameNode URL. The owner of this node's JVM process must have read and write access to this directory. The path could be absolute or relative. If a relative path for HomeDir is provided, then the HomeDir is created relative to /user/JVM_owner_name or, if specified, relative to directory specified by the hdfs-root-dir property. As a best practice, HDFS store directories should be created relative to a single HDFS root directory. As an alternative, an absolute path beginning with the "/" character to override the default root location can be provided. |
HDFSClientConfigFile | no | The full path to the HDFS client configuration file, for e.g. hdfs-site.xml or core-site.xml. This file must be accessible to any node where an instance of this HDFSStore will be created. If each node has a local copy of this configuration file, it is important for all the copies to be "identical". Alternatively, by default HDFS client can also load some HDFS configuration files if added in the classpath. |
MaxMemory | yes | The maximum amount of memory in megabytes used by HDFSStore. HDFSStore buffers data in memory to optimize HDFS IO operations. Once the configured memory is utilized, data may overflow to disk. |
ReadCacheSize | no | The maximum amount of memory in megabytes used by HDFSStore read cache. HDFSStore can cache data in memory to optimize HDFS IO operations. Read cache shares memory allocated to HDFSStore. Increasing read cache memory can improve the read performance. |
BatchSize | yes | HDFSStore buffer data is persisted on HDFS in batches, and the BatchSize defines the maximum size (in megabytes) of each batch that is written to HDFS. This parameter, along with BatchInterval determines the rate at which data is persisted on HDFS. |
BatchInterval | yes | HDFSStore buffer data is persisted on HDFS in batches, and the BatchInterval defines the maximum time that can elapse between writing batches to HDFS. This parameter, along with BatchSize determines the rate at which data is persisted on HDFS. |
DispatcherThreads | no | The maximum number of threads (per region) used to write batches of HDFS. If you have a large number of clients that add or update data in a region, then you may need to increase the number of dispatcher threads to avoid bottlenecks when writing data to HDFS. |
BufferPersistent | no | Configure if HDFSStore in-memory buffer data, that has not been persisted on HDFS yet, should be persisted to a local disk to buffer prevent data loss. Persisting data may impact write performance. If performance is critical and buffer data loss is acceptable, disable persistence. |
DiskStore | no | The named DiskStore to use for any local disk persistence needs of HDFSStore, for e.g. store's buffer persistence and buffer overflow. If you specify a value, the named DiskStore must exist. If you specify a null value or you omit this option, default DiskStore is used. |
SynchronousDiskWrite | no | Include the isSynchronous option to enable or disable synchronous writes to the local DiskStore. |
PurgeInterval | yes | HDFSStore creates new files as part of periodic maintenance activity. Existing files are deleted asynchronously. PurgeInterval defines the amount of time old files remain available for MapReduce jobs. After this interval has passed, old files are deleted. |
Compaction | yes | Compaction reorganizes data in HDFS files to improve read performance and reduce number of data files on HDFS. It also removes old version and deleted records. Compaction process can be I/O-intensive. Tune the performance of compaction using CompactionThreads. |
CompactionThreads | yes | The maximum number of threads that HDFSStore uses to perform compaction. You can increase the number of threads used for compactions on different buckets as necessary in order to fully utilize the performance of your HDFS cluster and its disks. |
MaxWriteOnlyFileSize | yes | For HDFS write-only regions, this defines the maximum size (in megabytes) that an HDFS log file can reach before HDFSStore closes the file and begins writing to a new file. This clause is ignored for HDFS read/write regions. Keep in mind that the files are not available for MapReduce processing until the file is closed; you can also set WriteOnlyFileRolloverInterval to specify the maximum amount of time an HDFS log file remains open. |
WriteOnlyFileRolloverInterval | yes | For HDFS write-only regions, this defines the maximum time that can elapse before HDFSStore closes an HDFS file and begins writing to a new file. This clause is ignored for HDFS read/write regions. |
InputFormat
Read-Write Region
- Input
- Count of files is known. Each buffer flush operation will create a new oplog file. Periodically some files will be merged by compaction. When InputFormat is initialized it will see a list of oplog files.
- Number of buckets is known, say P
- Size of files is known
- Hdfs block size is known, say H
- File creation time is known
- Records within a file will be sorted by key
- Files can have overlapping key range
- Each oplog file has a mini index metadata, a subset of keys and their offset in the oplog is saved.
- Approximate count of unique keys can be computed.
- Constraints
- The process of split creation needs to be efficient. It is desired that the split creation is not dependent on contents of the oplog files. It is ok to create and read metadata files.
- Number of files can change while data is consumed
- Duplicate processing of the same event by two RecordReaders is an error
Algorithm
- Compute how many splits should be created
- Compute the total size of all active files of a bucket, say b
- Find the Hdfs block size (H)
- Number of splits to be created, s = b/H. The idea is to split the bucket into s equal parts, size of Hdfs block size. Each split will process a disjoint key range, i such that 0 < i <= s
- Total number of splits per region will be S = s x P
- Compute key range per split
- Identify a subset of large oplog files, i.e. files containing most data. Locality of these files matters the most
- Read keys and offset from the root index metadata of the selected files
- Merge the roots keys and construct a sorted array of unique root keys, [k1, k2, ... , kN] (N >> s)
- Split N root index keys into s ranges, N / s = [ N1, N2, ... , Ns ]
- Find preferred HDFS block for each range
- Fetch Hdfs block metadata from the NN for the selected files
- For each Hdfs block find the matching range using root index metadata fetched earlier
- For each Hdfs block compute how much data will actually be read. This is a function of total number of keys in the hdfs block and the overlap with key range.
- For each range find location of the hdfs block which will provide maximum data. Prefer newer blocks over old ones.
- Create split with keyRange, hdfs block location and oplog file paths
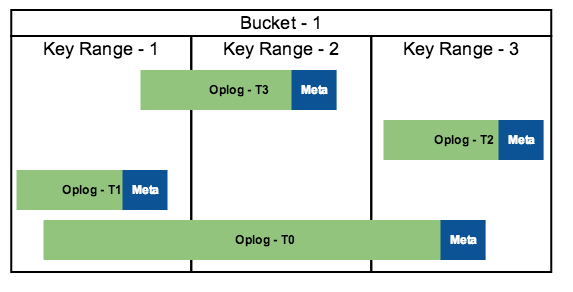
Write-Only Region
Oplog files for write-Only HdfsRegions have disjoint ranges. Use CombineInputFormat to create splits and record readers