Basic Definitions
Node - individual instance of Ignite, either a server or a client.
Client node - a thick client used to connect to an Ignite cluster. It can't store any data and acts as a gateway to the cluster.
Server node - regular Ignite node used to store data and serve requests. "Node" and "server node" definitions are used interchangeably across this document.
Node order - internal property of a node used to imply a total order over the nodes in a cluster.
Coordinator - special server node responsible for coordinating different processes in the cluster (e.g. verifying discovery messages or managing Partition Map Exchange).
Topology - arrangement of nodes connected via a communication network.
Introduction
The main goal of the discovery mechanism is to create a topology of Ignite nodes and build and maintain a consistent in-memory view of it on every node. For example, this view may contain the number of nodes in the cluster and their orders.
Discovery mechanism is represented by the DiscoverySpi interface, while TcpDiscoverySpi is its default implementation. Other implementations, like ZookeeperDiscoverySpi, also exist but are out of the scope of this article.
Exact topology structure is defined by the particular DiscoverySpi implementations, for example, TcpDiscoverySpi defines a ring-shaped topology.
When describing cluster topology, we are talking about a logical arrangement that only exists on the "discovery" level. For example, when querying data residing in caches, a cluster might use a different topology than described here.
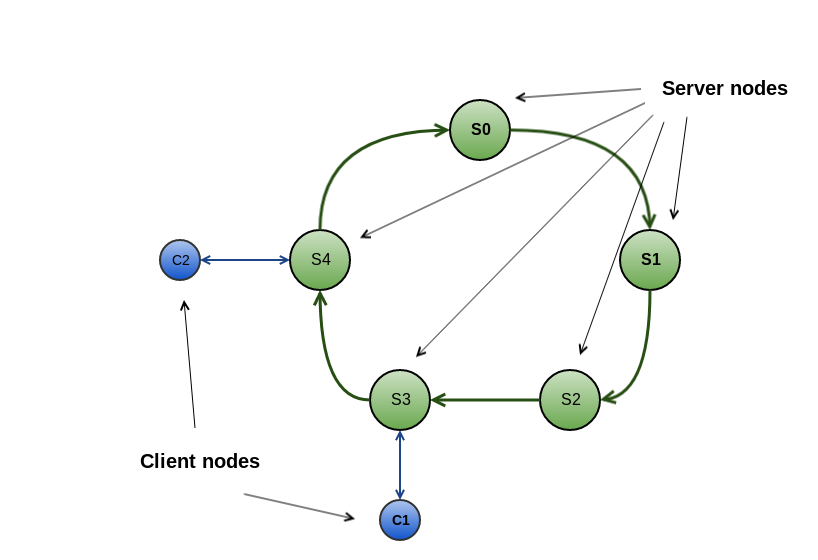
Ring-Shaped Topology
TcpDiscoverySpi organizes all server nodes of a cluster into a ring-shaped structure where each node can only send discovery messages to a single node (called a "neighbor"). Client nodes stay outside of the ring and are always connected to a single server. This logic is contained inside ServerImpl and ClientImpl classes for server and client nodes respectively.
Node Join Process
Overview
When a new node starts, it tries to find an existing cluster by probing all addresses provided by the TcpDiscoveryIpFinder. If all addresses are unavailable, the node considers itself as the only node, forms a cluster from itself and becomes the coordinator. Otherwise, it starts the join process.
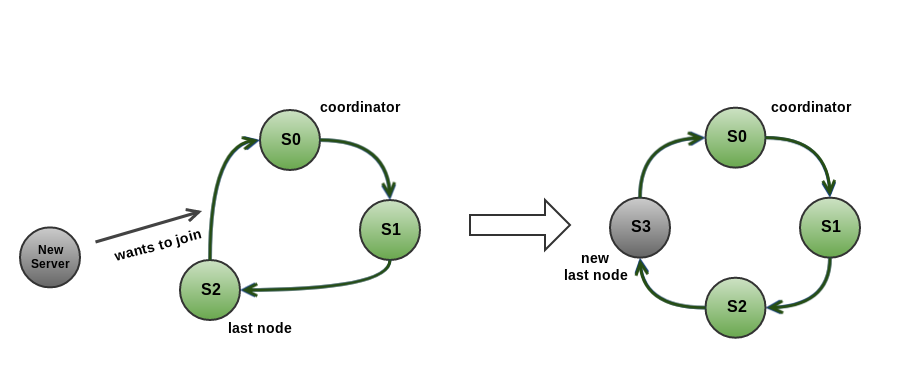
Node join process consists of several phases:
- Joining node sends a
TcpDiscoveryJoinRequestMessageto a random node in the cluster, which gets forwarded to the coordinator. - Coordinator places the new node in the ring between the last node and itself and propagates the topology changes by sending the
TcpDiscoveryNodeAddedMessageacross the ring. - After
TcpDiscoveryNodeAddedMessagehas been received by all members of the cluster,TcpDiscoveryNodeAddFinishedMessageis sent to finalize the changes.
TcpDiscoveryJoinRequestMessage
A node begins the join process by calling ServerImpl#joinTopology (for server nodes) or ClientImpl#joinTopology (for client nodes), which in turn calls TcpDiscoverySpi#collectExchangeData to collect all necessary discovery data (e.g. cache configurations from GridCacheProcessor, see different GridComponent#collectJoiningNodeData implementations). This data gets packed into the join request and sent to the coordinator.
When the coordinator receives the request it validates the message and generates the TcpDiscoveryNodeAddedMessage, if a validation was successful (see ServerImpl.RingMessageWorker#processJoinRequestMessage). This message is then sent across the ring.
TcpDiscoveryNodeAddedMessage
When handling the TcpDiscoveryNodeAddedMessage, every node in the cluster applies joining node discovery data to components, collects its local discovery data, and adds it to the message (see ServerImpl.RingMessageWorker#processNodeAddedMessage for details). The message is then propagated further across the ring by calling ServerImpl.RingMessageWorker#sendMessageAcrossRing.
When TcpDiscoveryNodeAddedMessage completes the full circle and reaches the coordinator again, it gets consumed and the coordinator emits the TcpDiscoveryNodeAddFinishedMessage.
TcpDiscoveryNodeAddedMessage is delivered to the joining node as well, it receives the message at the very end after all other nodes have already processed it.
TcpDiscoveryNodeAddFinishedMessage
TcpDiscoveryNodeAddFinishedMessage finishes the process of node join. When receiving this message, each node fires the NODE_JOINED event to notify the discovery manager about the new joined node.
NodeAddFinished and additional join requests
The joining node will send an additional join request if it doesn't receive TcpDiscoveryNodeAddFinishedMessage on time. This time is defined by TcpDiscoverySpi#networkTimeout and has a default value of 5 seconds (TcpDiscoverySpi#DFLT_NETWORK_TIMEOUT).
Detecting and Removing Failed Nodes from Topology
Detecting failed nodes is the responsibility of each server node in a cluster. However, detecting failed servers and clients works slightly differently.
Server Nodes Failures
As servers are organized into a ring each node can easily detect failure of its next neighbor node if sending of a discovery message fails.
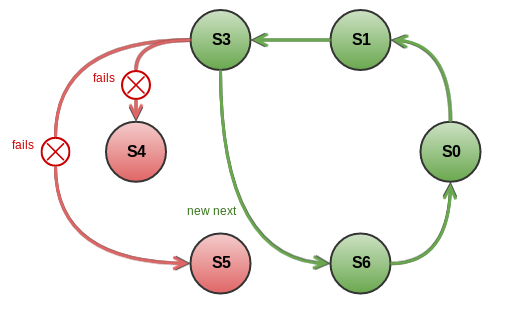
However, the process of removing a failed node from the ring is not that simple and has to be managed by the coordinator. It contains two steps:
First step
During the first step, the server that detected that its neighbor has failed adds the broken node's address to a special in-memory structure called failedNodes (see TcpDiscoveryAbstractMessage#failedNodes). This structure is then used to filter out the failed nodes from the list of all nodes in the ring until the second step is complete.
After that, the server tries to establish a connection to the next node in the ring. If the connection is established, this node becomes the new neighbor, otherwise the process gets repeated until a working node is found.
TcpDiscoveryAbstractMessage and its responsibilities
All discovery messages contain information about failed nodes in the topology (see ServerImpl$RingMessageWorker#sendMessageAcrossRing) and all nodes that receive a discovery message start processing it by updating their local failedNodes (see ServerImpl$RingMessageWorker#processMessage).
When the ring is restored and the next available node is found, the current node sends a TcpDiscoveryNodeFailedMessage for every encountered failed node (e.g. if three nodes have failed, three TcpDiscoveryNodeFailedMessage messages are sent).
Second step
The second step starts on the coordinator. When the coordinator receives a TcpDiscoveryNodeFailedMessage it verifies it and sends it across the ring. All servers (including the coordinator) update their local topology versions, remove the failed node(s) from the ring structure and failedNodes internal structures (see ServerImpl$RingMessageWorker#processNodeFailedMessage).
Client Nodes Failures
Section patiently waits for someone to contribute the content
Resilience in Presence of Short Network Glitches
Algorithm of restoring ring without failing nodes (that one involving CrossRingMessageSendState and other tricky things and special timeouts) should be covered here in great details (including special timeouts)
Corner Cases with Filtering of Unverified NodeFailed Messages
Section patiently waits for someone to contribute the content
Custom Discovery Messages and Events
Section patiently waits for someone to contribute the content
Message Delivery Guarantees
Section patiently waits for someone to contribute the content
Overview
Content Tools
Apps