...
- One currently implements different sources for batch and streaming execution.
- The logic for "work discovery" (splits, partitions, etc) and actually "reading" the data is intermingled in the
SourceFunctioninterface and in theDataStreamAPI API, leading to complex implementations like the Kafka and Kinesis source. - Partitions/shards/splits are not explicit in the interface. This makes it hard to implement certain functionalities in a source-independent way, for example event-time alignment, per-partition watermarks, dynamic split assignment, work stealing. For example, the Kafka source supports per-partition watermarks, the Kinesis source doesn't. Neither source supports event-time alignment (selectively reading from splits to make sure that we advance evenly in event time).
- The checkpoint lock is "owned" by the source function. The implementation has to ensure to make element emission and state update under the lock. There is no way for Flink to optimize how it deals with that lock.
The lock is not a fair lock. Under lock contention, some thready might not get the lock (the checkpoint thread).
This also stands in the way of a lock-free actor/mailbox style threading model for operators. - There are no common building blocks, meaning every source implements a complex threading model by itself. That makes implementing and testing new sources hard, and adds a high bar to contributing to existing sources .
...
The SplitEnumerator is similar to the old batch source interface's functionality of creating splits and assigning splits. It runs only once, not in parallel (but could be thought of to parallelize in the future, if necessary).
It might run on the JobManager or in a single task on a TaskManager (see below "Where to runt run the Enumerator").
Example:
- In the File Source , the
SplitEnumeratorlists all files (possibly sub-dividing them into blocks/ranges). - For the Kafka Source, the
SplitEnumeratorfinds all Kafka Partitions that the source should read from.
- In the File Source , the
The Reader reads the data from the assigned splits. The reader encompasses most of the functionality of the current source interface.
The Reader reads the data from the assigned splits and encompasses most of the functionality of the current source interface. Some readers may read a sequence of bounded splits after another, some may ready multiple (unbounded) splits in parallel.
The main Source interface itself is only a factory for creating split enumerators and readers. This This separation between enumerator and reader allows mixing and matching different enumeration strategies with split readers. For example, the current Kafka connector has different strategies for partition discovery that are intermingled with the rest of the code. With the new interfaces in place, we would only need one split reader implementation and there could be several split enumerators for the different partition discovery strategies.
With these two components encapsulating the core functionality, the main Source interface itself is only a factory for creating split enumerators and readers.
| draw.io Diagram | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||
| draw.io Diagram | ||||||||||||||||
|
Example:
- In the File Source , the
SplitEnumeratorlists all files (possibly sub-dividing them into blocks/ranges). - For the Kafka Source, the
SplitEnumeratorfinds all Kafka Partitions that the source should read from.
Batch and Streaming Unification
...
Sequential Single Split |
Multi-split Multiplexed |
Multi-split multiMulti-threadesthreaded |
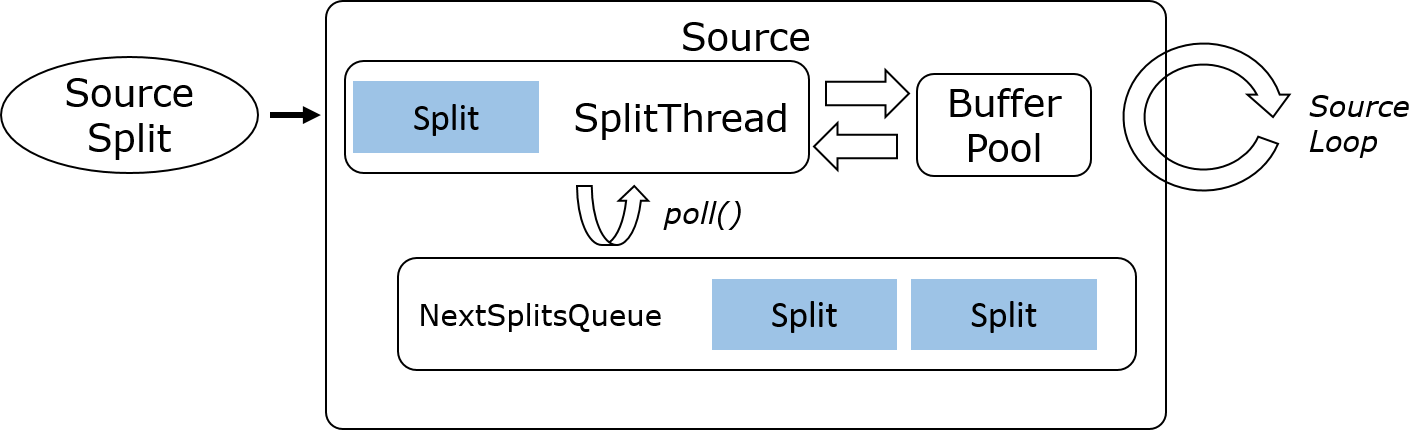


Most of the readers implemented against these higher level building blocks would only need to implement an interface similar to this. The contract would also be that all methods except wakeup() would be called by the same thread, obviating the need for any concurrency handling in the connector.
...
TBD.
Event Time Alignment
TBD.
| Anchor | ||||
|---|---|---|---|---|
|
Where Where to Run the Enumerator
The communication of splits between the Enumerator
...
and the SourceReader has specific requirements:
- Lazy / pull-based assignment: Only when a reader requests the next split should the enumerator send a split. That results in better load-balancing
- Payload on the "pull" message, to communicate information like "location" from the SourceReader to SplitEnumerator, thus supporting features like locality-aware split assignment.
- Exactly-once fault tolerant with checkpointing: A split is sent to the reader once. A split is either still part of the enumerator (and its checkpoint) or part of the reader or already complete.
- Exactly-once between checkpoints (and without checkpointing): Between checkpoints (and in the absence of checkpoints), the splits that were assigned to readers must be re-added to the enumerator upon failure / recovery.
- Communication channel must not connect tasks into a single failover region
Given these requirements, there would be two options to implement this communication.
Option 1: Enumerator on the TaskManager
(TBD. explain more)
Advantages
- Splits are just data messages. Checkpoints and watermarks just work as usual
- Keeps all complexity out of the JobManager and the ExecutionGraph / Scheduler
Disadvantages
- Need some changes to the network stack
Option 2: Enumerator on the JobManager
(TBD. explain more)
Advantages
- No extra effort to keep the readers in separate failover regions
- No changes to the network stack
Disadvantages
- Requires additional effort to align RPC communication for split assignment, checkpoints, and watermarks to be consistent
- Adds quite a bit of complexity to JobManager and Checkpoint Coordinator
...
Core Public Interfaces
Source
...