...
Given these requirements, there would be two options to implement this communication.
Option 1: Enumerator on the TaskManager
(TBD. explain more)
Advantages
- Splits are just data messages. Checkpoints and watermarks just work as usual
- Keeps all complexity out of the JobManager and the ExecutionGraph / Scheduler
Disadvantages
- Need some changes to the network stack
Option 2: Enumerator on the JobManager
(TBD. explain more)
Advantages
- No extra effort to keep the readers in separate failover regions
- No changes to the network stack
Disadvantages
...
The SplitEnumerator runs as a task with parallelism one. Downstream of the enumerator are the SourceReader tasks, which run in parallel. Communication goes through the regular data streams.
The readers request splits by sending "backwards events", similar to "request partition" or the "superstep synchronization" in the batch iterations. These are not exposed in operators, but tasks have access to them.
The task reacts to the backwards events: Only upon an event will it send a split. That gives us lazy/pull-based assignment. Payloads on the request backwards event messages (for example for locality awareness) is possible.
Checkpoints and splits are naturally aligned, because splits go through the data channels. The enumerator is effectively the only entry task from the source, and the only one that receives the "trigger checkpoint" RPC call.
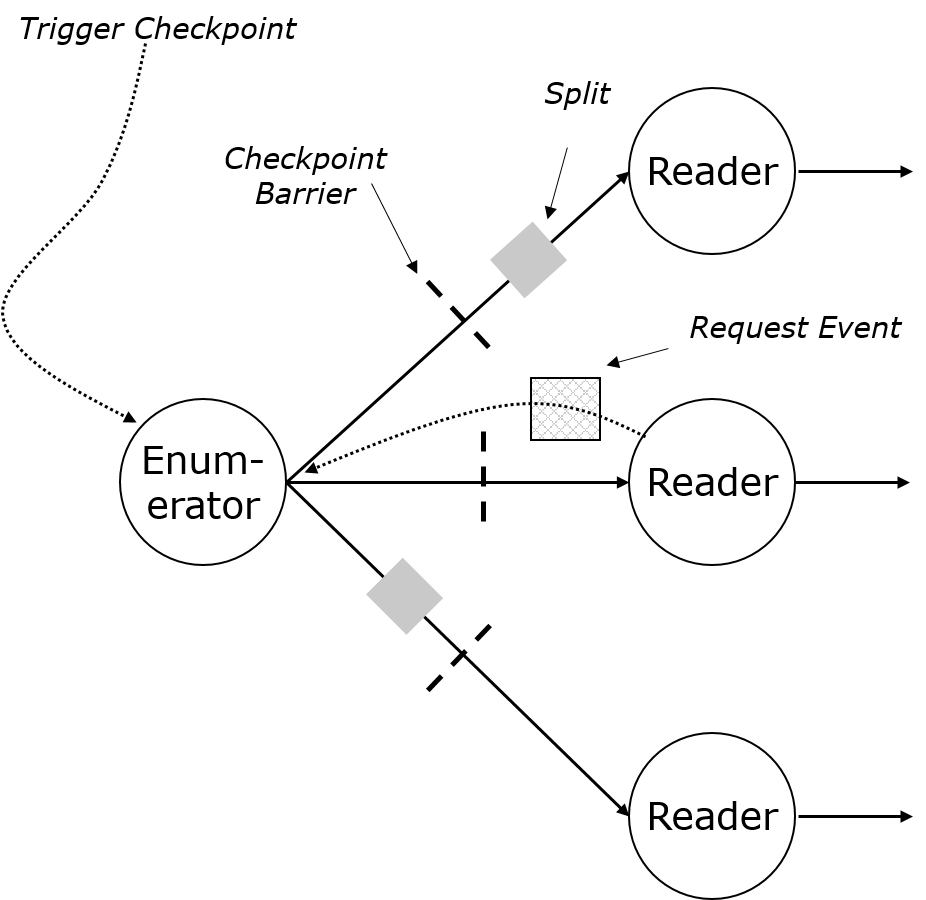
The network connection between enumerator and split reader is treated by the scheduler as a boundary of a failover region.
To decouple the enumerator and reader restart, we need one of the following mechanisms:
- Pipelined persistent channels: The contents of a channel is persistent between checkpoints. A receiving task requests the data "after checkpoint X". The data is pruned when checkpoint X+1 is completed.
When a reader fails, the recovered reader task can reconnect to the stream after the checkpoint and will get the previously assigned splits. Batch is a special case, if there are no checkpoints, then the channel holds all data since the beginning.- Pro: The "pipelined persistent channel" has also applications beyond the enumerator to reader connection.
- Con: Splits always go to the same reader and cannot be distributed across multiple readers upon recovery. Especially for batch programs, this may create bad stragglers during recovery.
- Reconnects and task notifications on failures:The enumerator task needs to remember the splits assigned to each result partition until the next checkpoint completes. The enumerator task would have to be notified of the failure of a downstream task and add the splits back to the enumerator. Recovered reader tasks would simply reconnect and get a new stream.
- Pro: Re-distribution of splits across all readers upon failure/recovery (no stragglers).
- Con: Breaks abstraction that separates task and network stack.
Option 2: Enumerator on the JobManager
(TBD. explain more)
Open Questions
In both cases, the enumerator is a point of failure that requires a restart of the entire dataflow.
To circumvent that, we probably need an additional mechanism, like a write-ahead log for split assignment.
Comparison between Options
...
| Criterion | Enumerate on Task | Enumerate on JobManager |
|---|---|---|
Encapsulation of Enumerator | Encapsulation in separate Task | Additional complexity in ExecutionGraph |
| Network Stack Changes | Significant changes. Some are more clear, like reconnecting. Some seem to break abstractions, like notifying tasks of downstream failures. | No Changes necessary |
| Scheduler / Failover Region | Minor changes | No changes necessary |
| Checkpoint alignment | No changes necessary (splits are data messages, naturally align with barriers) | Careful coordination between split assignment and checkpoint triggering. Might be simple if both actions are run in the single-threaded ExecutionGraph thread. |
| Watermarks | No changes necessary (splits are data messages, watermarks naturally flow) | Watermarks would go through ExecutionGraph |
| Checkpoint State | No additional mechanism (only regular task state) | Need to add support for mon-metadata state on the JobManager / ExecutionGraph |
| Supporting graceful Enumerator recovery (avoid full restarts) | Network reconnects (like above), plus write-ahead of split | Tracking split assignment between checkpoints, plus |
Core Public Interfaces
Source
...