...
- One currently implements different sources for batch and streaming execution.
- The logic for "work discovery" (splits, partitions, etc) and actually "reading" the data is intermingled in the
SourceFunctioninterface and in theDataStreamAPI, leading to complex implementations like the Kafka and Kinesis source. - Partitions/shards/splits are not explicit in the interface. This makes it hard to implement certain functionalities in a source-independent way, for example event-time alignment, per-partition watermarks, dynamic split assignment, work stealing. For example, the Kafka source supports and Kinesis consumers support per-partition watermarks, the Kinesis source doesn't. Neither source but as of Flink 1.8.1 only the Kinesis consumer supports event-time alignment (selectively reading from splits to make sure that we advance evenly in event time).
- The checkpoint lock is "owned" by the source function. The implementation has to ensure to make element emission and state update under the lock. There is no way for Flink to optimize how it deals with that lock.
The lock is not a fair lock. Under lock contention, some thready might not get the lock (the checkpoint thread).
This also stands in the way of a lock-free actor/mailbox style threading model for operators. - There are no common building blocks, meaning every source implements a complex threading model by itself. That makes implementing and testing new sources hard, and adds a high bar to contributing to existing sources .
...
- Sequential Single Split (File, database query, most bounded splits)
- Multi-split multiplexed (Kafka, Pulsar, Pravega, ...)
- Multi-split multi-threaded (Kinesis, ...)
Sequential Single Split |
Multi-split Multiplexed |
Multi-split Multi-threaded |
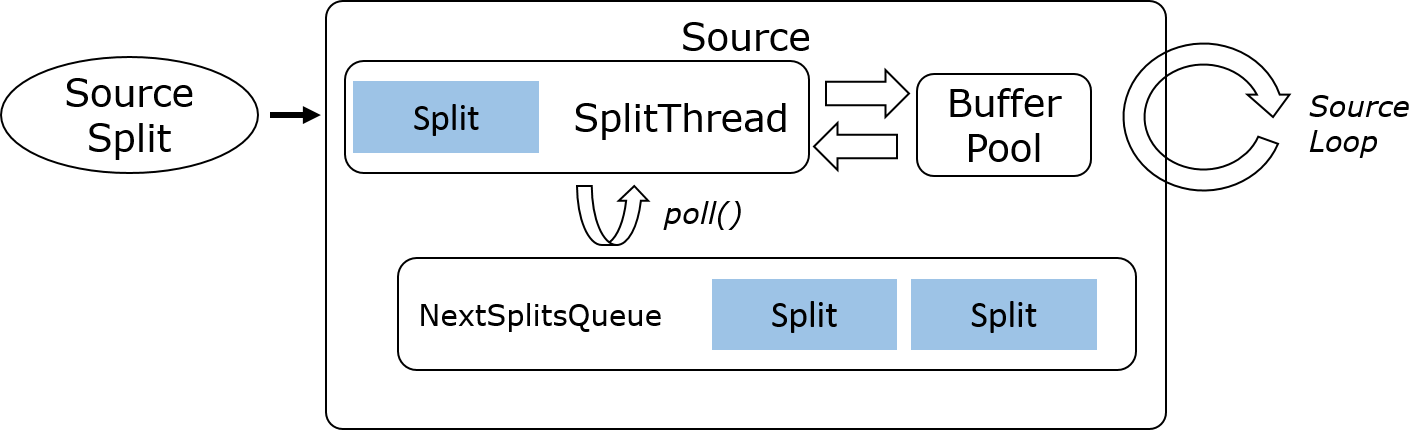


Most of the readers implemented against these higher level building blocks would only need to implement an interface similar to this. The contract would also be that all methods except wakeup() would be called by the same thread, obviating the need for any concurrency handling in the connector.
...
Comparison between Options
| Criterion | Enumerate on Task | Enumerate on JobManager | Enumerate on SourceCoordinator |
|---|---|---|---|
Encapsulation of Enumerator | Encapsulation in separate Task | Additional complexity in ExecutionGraph | New component SourceCoordinator |
| Network Stack Changes | Significant changes. Some are more clear, like reconnecting. Some seem to break abstractions, like notifying tasks of downstream failures. | No Changes necessary | No Changes necessary |
| Scheduler / Failover Region | Minor changes | No changes necessary | Minor changes |
| Checkpoint alignment | No changes necessary (splits are data messages, naturally align with barriers) | Careful coordination between split assignment and checkpoint triggering. Might be simple if both actions are run in the single-threaded ExecutionGraph thread. | No changes necessary (splits are through RPC, naturally align with barriers) |
| Watermarks | No changes necessary (splits are data messages, watermarks naturally flow) | Watermarks would go through ExecutionGraph | Watermarks would go through RPC |
| Checkpoint State | No additional mechanism (only regular task state) | Need to add support for asynchronous non-metadata state on the JobManager / ExecutionGraph | Need to add support for asynchronous state on the SourceCoordinator |
| Supporting graceful Enumerator recovery (avoid full restarts) | Network reconnects (like above), plus write-ahead of split | Tracking split assignment between checkpoints, plus | Tracking split assignment between checkpoints, plus write-ahead of split assignment between checkpoints |
Personal opinion from Stephan: If we find an elegant way to abstract the network stack changes, I would lean towards running the Enumerator in a Task, not on the JobManager.
...