Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
This FLIP aims to solve several problems/shortcomings in the current streaming source interface (SourceFunction) and simultaneously to unify the source interfaces between the batch and streaming APIs. The shortcomings or points that we want to address are:
- One currently implements different sources for batch and streaming execution.
- The logic for "work discovery" (splits, partitions, etc) and actually "reading" the data is intermingled in the
SourceFunctioninterface and in theDataStreamAPI, leading to complex implementations like the Kafka and Kinesis source. - Partitions/shards/splits are not explicit in the interface. This makes it hard to implement certain functionalities in a source-independent way, for example event-time alignment, per-partition watermarks, dynamic split assignment, work stealing. For example, the Kafka and Kinesis consumers support per-partition watermarks, but as of Flink 1.8.1 only the Kinesis consumer supports event-time alignment (selectively reading from splits to make sure that we advance evenly in event time).
- The checkpoint lock is "owned" by the source function. The implementation has to ensure to make element emission and state update under the lock. There is no way for Flink to optimize how it deals with that lock.
The lock is not a fair lock. Under lock contention, some thready might not get the lock (the checkpoint thread).
This also stands in the way of a lock-free actor/mailbox style threading model for operators. - There are no common building blocks, meaning every source implements a complex threading model by itself. That makes implementing and testing new sources hard, and adds a high bar to contributing to existing sources .
Overall Design
There are several key aspects in the design, which are discussed in each section. The discussion helps understand the public interface better.
Separating Work Discovery from Reading
The sources have two main components:
- SplitEnumerator: Discovers and assigns splits (files, partitions, etc.)
- Reader: Reads the actual data from the splits.
The SplitEnumerator is similar to the old batch source interface's functionality of creating splits and assigning splits. It runs only once, not in parallel (but could be thought of to parallelize in the future, if necessary).
It might run on the JobManager or in a single task on a TaskManager (see below "Where to run the Enumerator").
Example:
- In the File Source , the
SplitEnumeratorlists all files (possibly sub-dividing them into blocks/ranges). - For the Kafka Source, the
SplitEnumeratorfinds all Kafka Partitions that the source should read from.
- In the File Source , the
The Reader reads the data from the assigned splits. The reader encompasses most of the functionality of the current source interface.
Some readers may read a sequence of bounded splits after another, some may ready multiple (unbounded) splits in parallel.
This separation between enumerator and reader allows mixing and matching different enumeration strategies with split readers. For example, the current Kafka connector has different strategies for partition discovery that are intermingled with the rest of the code. With the new interfaces in place, we would only need one split reader implementation and there could be several split enumerators for the different partition discovery strategies.
With these two components encapsulating the core functionality, the main Source interface itself is only a factory for creating split enumerators and readers.
Batch and Streaming Unification
Each source should be able to work as a bounded (batch) and as an unbounded (continuous streaming) source.
The Boundedness is an intrinsic property to the source instance itself. In most cases, only the SplitEnumerators should know the Boundedness, while the SplitReaders are agnostic.
That way, we can also make the API type safe in the future, when we can explicitly model bounded streams.
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
FileSource<MyType> theSource = new ParquetFileSource("fs:///path/to/dir", AvroParquet.forSpecific(MyType.class));
// The returned stream will be a DataStream if theSource is unbounded.
// After we add BoundedDataStream which extends DataStream, the returned stream will be a BoundedDataStream.
// This allows users to write programs working in both batch and stream execution mode.
DataStream<MyType> stream = env.source(theSource);
// Once we add bounded streams to the DataStream API, we will also add the following API.
// The parameter has to be bounded otherwise an exception will be thrown.
BoundedDataStream<MyType> batch = env.boundedSource(theSource);
Examples
FileSource
- For "bounded input", it uses a
SplitEnumeratorthat enumerates once all files under the given path. - For "continuous input", it uses a
SplitEnumeratorthat periodically enumerates once all files under the given path and assigns the new ones.
KafkaSource
- For "bounded input", it uses a
SplitEnumeratorthat lists all partitions and gets the latest offset for each partition and attaches that as the "end offset" to the split. - For "continuous input", it uses a
SplitEnumeratorthat lists all partitions and attaches LONG_MAX as the "end offset" to each split. - The source may have another option to periodically discover new partitions. That would only be applicable to the "continuous input".
Generic enumerator-reader communication mechanism
The SplitEnumerator and SourceReader are both user implemented class. It is not rare that the implementation require some communication between these two components. In order to facilitate such use cases. In this FLIP, we introduce a generic message passing mechanism between the SplitEnumerator and SourceReader. This mechanism require an additional RPC method pair in the JobMasterGateway and TaskExecutorGateway. The message passing stack could be illustrated below.
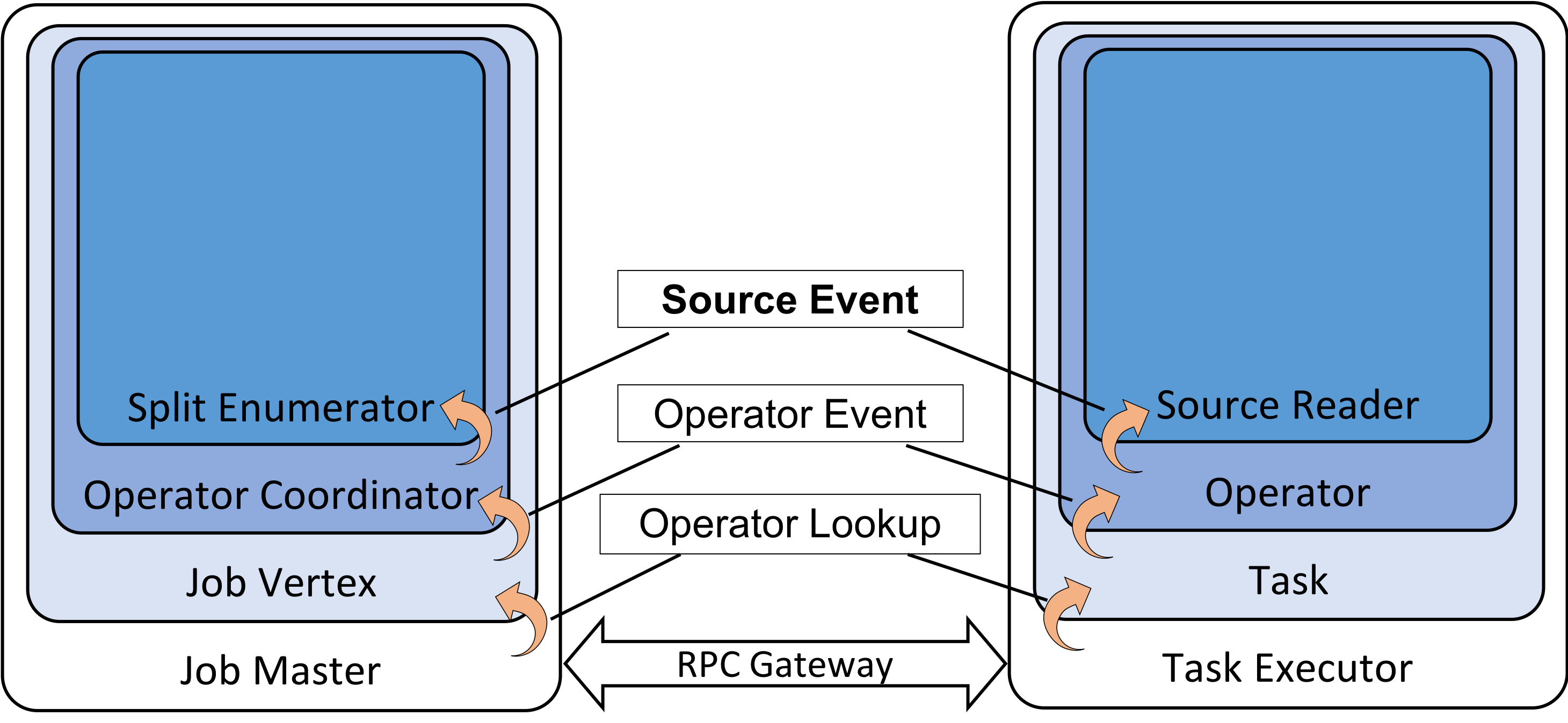
The SourceEvent is the interface for messages passed between the SplitEnumerator and the SourceReader. The OperatorEvent is the interface for messages passed between the OperatorCoordinator and Operator. The OperatorCoordinator is a generic coordinator that could be associated with any operator. In this FLIP, the SourceCoordinator will be an implementation of OperatorCoordinator that encapsulate SplitEnumerator.
Reader Interface and Threading Model
The reader need to fulfill the following properties:
- No closed work loop, so it does not need to manage locking
- Non-blocking progress methods, to it supports running in an actor/mailbox/dispatcher style operator
- All methods called by the same on single thread, so implementors need not deal with concurrency
- Watermark / Event time handling abstracted to be extensible for split-awareness and alignment (see below sections "Per Split Event-time" and "Event-time Alignment")
- All readers should naturally supports state and checkpoints
- Watermark generation should be circumvented for batch execution
The following core aspects give us these properties:
- Splits are both the type of work assignment and the type of state held by the source. Assigning a split or restoring a split from a checkpoint is the same to the reader.
- Advancing the reader is a non-blocking call that returns a future.
- We build higher-level primitives on top of the main interface (see below "High-level Readers")
- We hide event-time / watermarks in the
SourceOutputand pass different source contexts for batch (no watermarks) and streaming (with watermarks).
TheSourceOutputalso abstract the per-partition watermark tracking.
The SourceReader will run as a PushingAsyncDataInput which works well with the new mailbox threading model in the tasks, similar to the network inputs.
Base implementation and high-level readers
The core source interface (the lowest level interface) is very generic. That makes it flexible, but hard to implement for contributors, especially for sufficiently complex reader patterns like in Kafka or Kinesis.
In general, most I/O libraries used for connectors are not asynchronous, and would need to spawn an I/O thread to make them non-blocking for the main thread.
We propose to solve this by building higher level source abstractions that offer simpler interfaces that allow for blocking calls.
These higher level abstractions would also solve the issue of sources that handle multiple splits concurrently, and the per-split event time logic.
Most readers fall into one of the following categories:
- One reader single splits. (Some dead simple blocking readers)
- One reader multiple splits.
- Sequential Single Split (File, database query, most bounded splits)
- Multi-split multiplexed (Kafka, Pulsar, Pravega, ...)
- Multi-split multi-threaded (Kinesis, ...)
Sequential Single Split |
Multi-split Multiplexed |
Multi-split Multi-threaded |
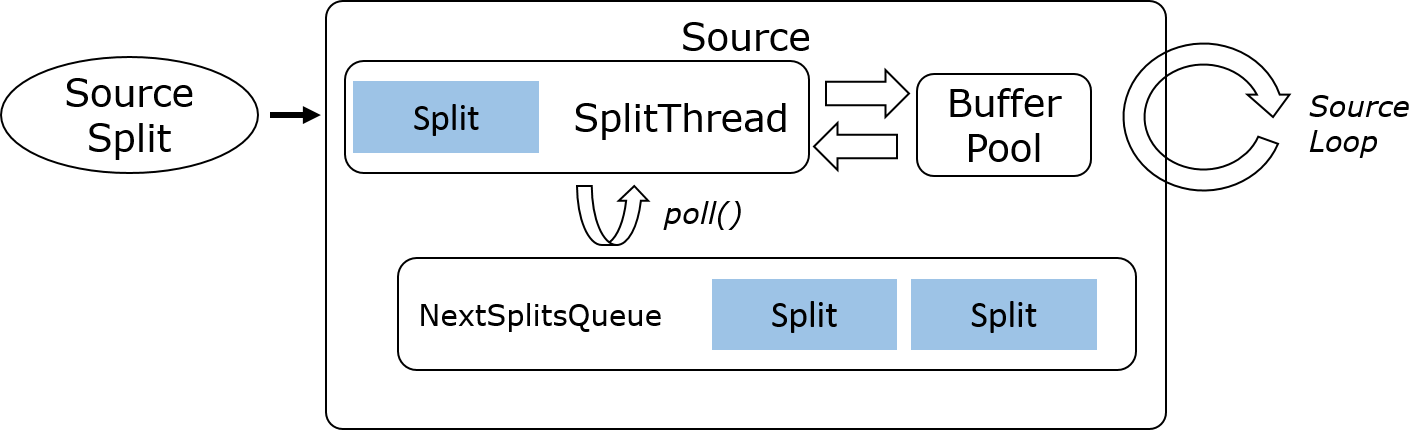


Most of the readers implemented against these higher level building blocks would only need to implement an interface similar to this. The contract would also be that all methods except wakeup() would be called by the same thread, obviating the need for any concurrency handling in the connector.
public interface SplitReader<E, SplitT extends SourceSplit> {
RecordsWithSplitIds<E> fetch() throws InterruptedException;
void handleSplitsChanges(Queue<SplitsChange<SplitT>> splitsChanges);
void wakeUp();
}
The RecordsWithSplitIds returned by the SplitReader will be passed to an RecordEmitter one by one. The RecordEmitter is responsible for the following:
- Convert the raw record type <E> into the eventual record type <T>
- Provide an event time timestamp for the record that it processes.
With the base implementation users writing their own source can just focus on:
- Fetch records from external system.
- Perform record parsing and conversion.
- Extract timestamps and optionally deal with watermarks. A followup FLIP will provide some default behaviors for users to deal with their watermark.
The base implementation can be roughly illustrated below:

Some brief explanations:
- When a new split is added to the SourceReader by SplitEnumerator, the initial state of that new split is put into a state map maintained by the SourceReaderBase before the split is assigned to a SplitReader.
- The records are passed from the the SplitReaders to the RecordEmitter in RecordsBySplitIds. This allows the SplitReader to enqueue records in a batch manner, which benefits performance.
- The SourceReaderBase iterates over each records and looks up their corresponding split state. The Record and its corresponding split state is passed to the RecordEmitter.
Note that the abstraction of this base implementation does not specify where the deserialization is performed. Because the RecordEmitter is driven by the main mailbox thread of the task, ideally the deserialization should be done in the split reader so it is more scalable. It is also possible to introduce a deserialization thread pool to do that. However, the detail implementation of deserialization is not the focus of this FLIP and will be covered by followup FLIPs.
The interfaces used by the base implementation is covered in the section of interface for base implementation.
Failover
The state of the SplitEnumerator includes the following:
- The unassigned splits
- The splits that have been assigned but not successfully checkpointed yet.
- The assigned but uncheckpointed splits will be associated with each of the checkpoint id they belong to.
The state of the SourceReader includes:
- The assigned splits
- The state of the splits (e.g. Kafka offsets, HDFS file offset, etc)
When the SplitEnumerator fails, a full failover will be performed. While it is possible to have a finer grained failover to only restore the state of the SplitEnumerator, we would like to address this in a separate FLIP.
When a SourceReader fails, the failed SourceReader will be restore to its last successful checkpoint. The SplitEnumerator will partially reset its state by adding the assigned-but-uncheckpointed splits back to the SplitEnumerator. In this case, only the failed subtask and its connected nodes will have to reset the states.
Where to run the enumerator
There was a long discussion about where to run the enumerator which we documented in the appendix. The final approach we took was very similar to option 3 with a few differences. The approach is following.
Each SplitEnumerator will be encapsulated in one SourceCoordinator. If there are multiple sources, multiple SourceCoordinator will there be. The SourceCoordinators will run in the JobMaster, but not as part of the ExecutionGraph. In this FLIP, we propose to failover the entire execution graph when the SplitEnumerator fails. A finer grained enumerator failover will be proposed in a later FLIP.
Per Split Event Time
With the introduction of the SourceSplit, we can actually emit per split event time for the users. We plan to propose the solution in a separate FLIP instead of in this FLIP to reduce the complexity.
Event Time Alignment
The event time alignment becomes easier to implement with the generic communication mechanism introduced between SplitEnumerator and SourceReader. In this FLIP we do not include this in the base implementation to reduce the complexity.
Public Interface
The public interface changes introduced by this FLIP consist of three parts.
- The top level public interfaces.
- The interfaces introduced as a part of the base implementation of the top level public interfaces.
- The base implementation provides common functionalities required for most Source implementations. See base implementation for details.
- The RPC gateway interface change for the generic message passing mechanism.
It is worth noting that while we will try best to maintain stable interfaces, the interfaces introduced as part of the base implementation (e.g. SplitReader) is more likely to change than the top level public interface such as SplitEnumerator / SourceReader. This is primarily because we expect to add more functionality into the base implementation over time.
Top level public interfaces
- Source - A factory style class that helps create SplitEnumerator and SourceReader at runtime.
- SourceSplit - An interface for all the split types.
- SplitEnumerator - Discover the splits and assign them to the SourceReaders
- SplitEnumeratorContext - Provide necessary information to the SplitEnumerator to assign splits and send custom events to the the SourceReaders.
- SplitAssignment - A container class holding the source split assignment for each subtask.
- SourceReader - Read the records from the splits assigned by the SplitEnumerator.
- SourceReaderContext - Provide necessary function to the SourceReader to communicate with SplitEnumerator.
- SourceOutput - A collector style interface to take the records and timestamps emit by the SourceReader.
- WatermarkOutput - An interface for emitting watermark and indicate idleness of the source.
Watermark - A new Watermark class will be created in the package org.apache.flink.api.common.eventtime. This class will eventually replace the existing Watermark in org.apache.flink.streaming.api.watermark. This change allows flink-core to remain independent of other modules. Given that we will eventually put all the watermark generation into the Source, this change will be necessary. Note that this FLIP does not intended to change the existing way that watermark can be overridden in the DataStream after they are emitted by the source.
Source
/**
* The interface for Source. It acts like a factory class that helps construct
* the {@link SplitEnumerator} and {@link SourceReader} and corresponding
* serializers.
*
* @param <T> The type of records produced by the source.
* @param <SplitT> The type of splits handled by the source.
* @param <EnumChkT> The type of the enumerator checkpoints.
*/
public interface Source<T, SplitT extends SourceSplit, EnumChkT> extends Serializable {
/**
* Get the boundedness of this source.
*
* @return the boundedness of this source.
*/
Boundedness getBoundedness();
/**
* Creates a new reader to read data from the spits it gets assigned.
* The reader starts fresh and does not have any state to resume.
*
* @param readerContext The {@link SourceReaderContext context} for the source reader.
* @return A new SourceReader.
*/
SourceReader<T, SplitT> createReader(SourceReaderContext readerContext);
/**
* Creates a new SplitEnumerator for this source, starting a new input.
*
* @param enumContext The {@link SplitEnumeratorContext context} for the split enumerator.
* @return A new SplitEnumerator.
*/
SplitEnumerator<SplitT, EnumChkT> createEnumerator(SplitEnumeratorContext<SplitT> enumContext);
/**
* Restores an enumerator from a checkpoint.
*
* @param enumContext The {@link SplitEnumeratorContext context} for the restored split enumerator.
* @param checkpoint The checkpoint to restore the SplitEnumerator from.
* @return A SplitEnumerator restored from the given checkpoint.
*/
SplitEnumerator<SplitT, EnumChkT> restoreEnumerator(
SplitEnumeratorContext<SplitT> enumContext,
EnumChkT checkpoint) throws IOException;
// ------------------------------------------------------------------------
// serializers for the metadata
// ------------------------------------------------------------------------
/**
* Creates a serializer for the source splits. Splits are serialized when sending them
* from enumerator to reader, and when checkpointing the reader's current state.
*
* @return The serializer for the split type.
*/
SimpleVersionedSerializer<SplitT> getSplitSerializer();
/**
* Creates the serializer for the {@link SplitEnumerator} checkpoint.
* The serializer is used for the result of the {@link SplitEnumerator#snapshotState()}
* method.
*
* @return The serializer for the SplitEnumerator checkpoint.
*/
SimpleVersionedSerializer<EnumChkT> getEnumeratorCheckpointSerializer();
}
/**
* The boundedness of the source: "bounded" for the currently available data (batch style),
* "continuous unbounded" for a continuous streaming style source.
*/
public enum Boundedness {
/**
* A bounded source processes the data that is currently available and will end after that.
*
* <p>When a source produces a bounded stream, the runtime may activate additional optimizations
* that are suitable only for bounded input. Incorrectly producing unbounded data when the source
* is set to produce a bounded stream will often result in programs that do not output any results
* and may eventually fail due to runtime errors (out of memory or storage).
*/
BOUNDED,
/**
* A continuous unbounded source continuously processes all data as it comes.
*
* <p>The source may run forever (until the program is terminated) or might actually end at some point,
* based on some source-specific conditions. Because that is not transparent to the runtime,
* the runtime will use an execution mode for continuous unbounded streams whenever this mode
* is chosen.
*/
CONTINUOUS_UNBOUNDED
}
SourceSplit
/**
* An interface for all the Split types to implement.
*/
public interface SourceSplit {
/**
* Get the split id of this source split.
* @return id of this source split.
*/
String splitId();
}
SourceReader
/**
* The interface for a source reader which is responsible for reading the records from
* the source splits assigned by {@link SplitEnumerator}.
*
* @param <T> The type of the record emitted by this source reader.
* @param <SplitT> The type of the the source splits.
*/
public interface SourceReader<T, SplitT extends SourceSplit> extends Serializable, AutoCloseable {
/**
* Start the reader;
*/
void start();
/**
* Poll the next available record into the {@link SourceOutput}.
*
* <p>The implementation must make sure this method is non-blocking.
*
* <p>Although the implementation can emit multiple records into the given SourceOutput,
* it is recommended not doing so. Instead, emit one record into the SourceOutput
* and return a {@link Status#AVAILABLE_NOW} to let the caller thread
* know there are more records available.
*
* @return The {@link Status} of the SourceReader after the method invocation.
*/
Status pollNext(SourceOutput<T> sourceOutput) throws Exception;
/**
* Checkpoint on the state of the source.
*
* @return the state of the source.
*/
List<SplitT> snapshotState();
/**
* @return a future that will be completed once there is a record available to poll.
*/
CompletableFuture<Void> isAvailable();
/**
* Adds a list of splits for this reader to read.
*
* @param splits The splits assigned by the split enumerator.
*/
void addSplits(List<SplitT> splits);
/**
* Handle a source event sent by the {@link SplitEnumerator}
*
* @param sourceEvent the event sent by the {@link SplitEnumerator}.
*/
void handleSourceEvents(SourceEvent sourceEvent);
/**
* The status of this reader.
*/
enum Status {
/** The next record is available right now. */
AVAILABLE_NOW,
/** The next record will be available later. */
AVAILABLE_LATER,
/** The source reader has completed all the reading work. */
FINISHED
}
}
SourceOutput
public interface SourceOutput<E> extends WatermarkOutput {
void emitRecord(E record);
void emitRecord(E record, long timestamp);
}
WatermarkOutput
/**
* An output for watermarks. The output accepts watermarks and idleness (inactivity) status.
*/
@Public
public interface WatermarkOutput {
/**
* Emits the given watermark.
*
* <p>Emitting a watermark also implicitly marks the stream as <i>active</i>, ending
* previously marked idleness.
*/
void emitWatermark(Watermark watermark);
/**
* Marks this output as idle, meaning that downstream operations do not
* wait for watermarks from this output.
*
* <p>An output becomes active again as soon as the next watermark is emitted.
*/
void markIdle();
}
Watermark
/**
* Watermarks are the progress indicators in the data streams. A watermark signifies
* that no events with a timestamp smaller or equal to the watermark's time will occur after the
* water. A watermark with timestamp <i>T</i> indicates that the stream's event time has progressed
* to time <i>T</i>.
*
* <p>Watermarks are created at the sources and propagate through the streams and operators.
*
* <p>In some cases a watermark is only a heuristic, meaning some events with a lower timestamp
* may still follow. In that case, it is up to the logic of the operators to decide what to do
* with the "late events". Operators can for example ignore these late events, route them to a
* different stream, or send update to their previously emitted results.
*
* <p>When a source reaches the end of the input, it emits a final watermark with timestamp
* {@code Long.MAX_VALUE}, indicating the "end of time".
*
* <p>Note: A stream's time starts with a watermark of {@code Long.MIN_VALUE}. That means that all records
* in the stream with a timestamp of {@code Long.MIN_VALUE} are immediately late.
*/
@Public
public final class Watermark implements Serializable {
private static final long serialVersionUID = 1L;
/** Thread local formatter for stringifying the timestamps. */
private static final ThreadLocal<SimpleDateFormat> TS_FORMATTER = ThreadLocal.withInitial(
() -> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"));
// ------------------------------------------------------------------------
/** The watermark that signifies end-of-event-time. */
public static final Watermark MAX_WATERMARK = new Watermark(Long.MAX_VALUE);
// ------------------------------------------------------------------------
/** The timestamp of the watermark in milliseconds. */
private final long timestamp;
/**
* Creates a new watermark with the given timestamp in milliseconds.
*/
public Watermark(long timestamp) {
this.timestamp = timestamp;
}
/**
* Returns the timestamp associated with this Watermark.
*/
public long getTimestamp() {
return timestamp;
}
/**
* Formats the timestamp of this watermark, assuming it is a millisecond timestamp.
* The returned format is "yyyy-MM-dd HH:mm:ss.SSS".
*/
public String getFormattedTimestamp() {
return TS_FORMATTER.get().format(new Date(timestamp));
}
// ------------------------------------------------------------------------
@Override
public boolean equals(Object o) {
return this == o ||
o != null &&
o.getClass() == Watermark.class &&
((Watermark) o).timestamp == this.timestamp;
}
@Override
public int hashCode() {
return Long.hashCode(timestamp);
}
@Override
public String toString() {
return "Watermark @ " + timestamp + " (" + getFormattedTimestamp() + ')';
}
}
SourceReaderContext
/**
* A context for the source reader. It allows the source reader to get the context information and
* allows the SourceReader to send source event to its split enumerator.
*/
public interface SourceReaderContext {
/**
* Returns the metric group for this parallel subtask.
*
* @return metric group for this parallel subtask.
*/
MetricGroup getMetricGroup();
/**
* Send a source event to the corresponding SplitEnumerator.
*
* @param event The source event to send.
*/
void sendEventToEnumerator(SourceEvent event);
}
SplitEnumerator
/**
* A interface of a split enumerator responsible for the followings:
* 1. discover the splits for the {@link SourceReader} to read.
* 2. assign the splits to the source reader.
*/
public interface SplitEnumerator<SplitT extends SourceSplit, CheckpointT> extends AutoCloseable {
/**
* Start the split enumerator.
*
* <p>The default behavior does nothing.
*/
void start();
/**
* Handles the source event from the source reader.
*
* @param subtaskId the subtask id of the source reader who sent the source event.
* @param sourceEvent the source event from the source reader.
*/
void handleSourceEvent(int subtaskId, SourceEvent sourceEvent);
/**
* Add a split back to the split enumerator. It will only happen when a {@link SourceReader} fails
* and there are splits assigned to it after the last successful checkpoint.
*
* @param splits The split to add back to the enumerator for reassignment.
* @param subtaskId The id of the subtask to which the returned splits belong.
*/
void addSplitsBack(List<SplitT> splits, int subtaskId);
/**
* Add a new source reader with the given subtask ID.
*
* @param subtaskId the subtask ID of the new source reader.
*/
void addReader(int subtaskId);
/**
* Checkpoints the state of this split enumerator.
*/
CheckpointT snapshotState();
/**
* Called to close the enumerator, in case it holds on to any resources, like threads or
* network connections.
*/
@Override
void close() throws IOException;
}
SplitEnumeratorContext
/**
* A context class for the {@link SplitEnumerator}. This class serves the following purposes:
* 1. Host information necessary for the SplitEnumerator to make split assignment decisions.
* 2. Accept and track the split assignment from the enumerator.
* 3. Provide a managed threading model so the split enumerators do not need to create their
* own internal threads.
*
* @param <SplitT> the type of the splits.
*/
public interface SplitEnumeratorContext<SplitT extends SourceSplit> {
MetricGroup metricGroup();
/**
* Send a source event to a source reader. The source reader is identified by its subtask id.
*
* @param subtaskId the subtask id of the source reader to send this event to.
* @param event the source event to send.
* @return a completable future which will be completed when the event is successfully sent.
*/
void sendEventToSourceReader(int subtaskId, SourceEvent event);
/**
* Get the number of subtasks.
*
* @return the number of subtasks.
*/
int numSubtasks();
/**
* Get the currently registered readers. The mapping is from subtask id to the reader info.
*
* @return the currently registered readers.
*/
Map<Integer, ReaderInfo> registeredReaders();
/**
* Assign the splits.
*
* @param newSplitAssignments the new split assignments to add.
*/
void assignSplits(SplitsAssignment<SplitT> newSplitAssignments);
/**
* Invoke the callable and handover the return value to the handler which will be executed
* by the source coordinator.
*
* <p>It is important to make sure that the callable should not modify
* any shared state. Otherwise the there might be unexpected behavior.
*
* @param callable a callable to call.
* @param handler a handler that handles the return value of or the exception thrown from the callable.
*/
<T> void callAsync(Callable<T> callable, BiConsumer<T, Throwable> handler);
/**
* Invoke the callable and handover the return value to the handler which will be executed
* by the source coordinator.
*
* <p>It is important to make sure that the callable should not modify
* any shared state. Otherwise the there might be unexpected behavior.
*
* @param callable the callable to call.
* @param handler a handler that handles the return value of or the exception thrown from the callable.
* @param initialDelay the initial delay of calling the callable.
* @param period the period between two invocations of the callable.
*/
<T> void callAsync(Callable<T> callable,
BiConsumer<T, Throwable> handler,
long initialDelay,
long period);
}
SplitAssignment
/**
* A class containing the splits assignment to the source readers.
*
* <p>The assignment is always incremental. In another word, splits in the assignment are simply
* added to the existing assignment.
*/
public class SplitsAssignment<SplitT extends SourceSplit> {
private final Map<Integer, List<SplitT>> assignment;
public SplitsAssignment(Map<Integer, List<SplitT>> assignment) {
this.assignment = assignment;
}
/**
* @return A mapping from subtask ID to their split assignment.
*/
public Map<Integer, List<SplitT>> assignment() {
return assignment;
}
@Override
public String toString() {
return assignment.toString();
}
}
SourceEvent
/**
* An interface for the events passed between the SourceReaders and Enumerators.
*/
public interface SourceEvent extends Serializable {}
StreamExecutionEnvironment
public class StreamExecutionEnvironment {
...
public <T> DataStream<T> continuousSource(Source<T, ?, ?> source) {...}
public <T> DataStream<T> continuousSource(Source<T, ?, ?> source, TypeInformation<T> type) {...}
public <T> DataStream<T> boundedSource(Source<T, ?, ?> source) {...}
public <T> DataStream<T> boundedSource(Source<T, ?, ?> source, TypeInformation<T> type) {...}
...
}
Public interface from base Source implementation
The following interfaces are high level interfaces that are introduced by the base implementation of Source.
- SourceReaderBase - The base implementation for SourceReader. It uses the following interfaces.
- SplitReader - The stateless and thread-less high level reader which is only responsible for reading raw records of type <E> from the assigned splits.
- SplitChange - The split change to the split reader. Right now there is only one subclass which is SplitAddition.
- RecordsWithSplitIds - A container class holding the raw records of type <E> read by SplitReader. It allows the SplitReader to fetch and pass the records in batch.
- RecordEmitter - A class that takes the raw records of type <E> returned by the SplitReader, convert them into the final record type <T> and emit them into the SourceOutput.
SourceReaderBase
/**
* An abstract implementation of {@link SourceReader} which provides some sychronization between
* the mail box main thread and the SourceReader internal threads. This class allows user to have
* a SourceReader implementation by just providing the following:
* <ul>
* <li>A {@link SplitReader}.</li>
* <li>A {@link RecordEmitter}</li>
* <li>The logic to clean up a split state after it is finished.</li>
* <li>The logic to get the state from a {@link SourceSplit}.</li>
* <li>The logic to restore a {@link SourceSplit} from its state.</li>
* </ul>
*
* @param <E> The rich element type that contains information for split state update or timestamp extraction.
* @param <T> The final element type to emit.
* @param <SplitT> the immutable split type.
* @param <SplitStateT> the mutable type of split state.
*/
public abstract class SourceReaderBase<E, T, SplitT extends SourceSplit, SplitStateT>
implements SourceReader<T, SplitT> {
// -------------------- Abstract method to allow different implementations ------------------
/**
* Handles the finished splits to clean the state if needed.
*/
protected abstract void onSplitFinished(Collection<String> finishedSplitIds);
/**
* When new splits are added to the reader. The initialize the state of the new splits.
*
* @param split a newly added split.
*/
protected abstract SplitStateT initializedState(SplitT split);
/**
* Convert a mutable SplitStateT to immutable SplitT.
*
* @param splitState splitState.
* @return an immutable Split state.
*/
protected abstract SplitT toSplitType(String splitId, SplitStateT splitState);
}
SplitReader
/**
* An interface used to read from splits. The implementation could either read from a single split or from
* multiple splits.
*
* @param <E> the element type.
* @param <SplitT> the split type.
*/
public interface SplitReader<E, SplitT extends SourceSplit> {
/**
* Fetch elements into the blocking queue for the given splits. The fetch call could be blocking
* but it should get unblocked when {@link #wakeUp()} is invoked. In that case, the implementation
* may either decide to return without throwing an exception, or it can just throw an interrupted
* exception. In either case, this method should be reentrant, meaning that the next fetch call
* should just resume from where the last fetch call was waken up or interrupted.
*
* @return A RecordsWithSplitIds that contains the fetched records grouped by the split ids.
*
* @throws InterruptedException when interrupted
*/
RecordsWithSplitIds<E> fetch() throws InterruptedException;
/**
* Handle the split changes. This call should be non-blocking.
*
* @param splitsChanges a queue with split changes that has not been handled by this SplitReader.
*/
void handleSplitsChanges(Queue<SplitsChange<SplitT>> splitsChanges);
/**
* Wake up the split reader in case the fetcher thread is blocking in
* {@link #fetch()}.
*/
void wakeUp();
}
SplitChange
/**
* An abstract class to host splits change.
*/
public abstract class SplitsChange<SplitT> {
private final List<SplitT> splits;
SplitsChange(List<SplitT> splits) {
this.splits = splits;
}
/**
* @return the list of splits.
*/
public List<SplitT> splits() {
return Collections.unmodifiableList(splits);
}
}
/**
* A change to add splits.
*
* @param <SplitT> the split type.
*/
public class SplitsAddition<SplitT> extends SplitsChange<SplitT> {
public SplitsAddition(List<SplitT> splits) {
super(splits);
}
}
RecordsWithSplitIds
/**
* An interface for the elements passed from the SplitReader to the source reader.
*/
public interface RecordsWithSplitIds<E> {
/**
* Get all the split ids.
*
* @return a collection of split ids.
*/
Collection<String> getSplitIds();
/**
* Get all the records by Splits;
*
* @return a mapping from split ids to the records.
*/
Map<String, Collection<E>> getRecordsBySplits();
/**
* Get the finished splits.
*
* @return the finished splits after this RecordsWithSplitIds is returned.
*/
Set<String> getFinishedSplits();
}
RecordEmitter
/**
* Emit a record to the downstream.
*
* @param <E> the type of the record emitted by the {@link SplitReader}
* @param <T> the type of records that are eventually emitted to the {@link SourceOutput}.
* @param <SplitStateT> the mutable type of split state.
*/
public interface RecordEmitter<E, T, SplitStateT> {
/**
* Process and emit the records to the {@link SourceOutput}. A typical implementation will do the
* followings:
*
* <ul>
* <li>
* Convert the element emitted by the {@link SplitReader} to the target type taken by the
* {@link SourceOutput}.
* </li>
* <li>
* Extract timestamp from the passed in element and emit the timestamp along with the record.
* </li>
* <li>
* Emit watermarks for the source.
* </li>
* </ul>
*
* @param element The intermediate element read by the SplitReader.
* @param output The output to which the final records are emit to.
* @param splitState The state of the split where the given element was from.
*/
void emitRecord(E element, SourceOutput<T> output, SplitStateT splitState) throws Exception;
}
Public interface from RPC gateway
TaskExecutorGateway
public interface TaskExecutorGateway extends RpcGateway {
...
/**
* Sends an operator event to an operator in a task executed by this task executor.
*
* <p>The reception is acknowledged (future is completed) when the event has been dispatched to the
* {@link org.apache.flink.runtime.jobgraph.tasks.AbstractInvokable#dispatchOperatorEvent(OperatorID, SerializedValue)}
* method. It is not guaranteed that the event is processes successfully within the implementation.
* These cases are up to the task and event sender to handle (for example with an explicit response
* message upon success, or by triggering failure/recovery upon exception).
*/
CompletableFuture<Acknowledge> sendOperatorEvent(
ExecutionAttemptID task,
OperatorID operator,
SerializedValue<OperatorEvent> evt);
...
}
JobMasterGateway
public interface JobMasterGateway {
...
CompletableFuture<Acknowledge> sendOperatorEventToCoordinator(
ExecutionAttemptID task,
OperatorID operatorID,
SerializedValue<OperatorEvent> event);
...
}
Implementation Plan
The implementation should proceed in the following steps, some of which can proceed concurrently.
- Validate the interface proposal by implementing popular connectors of different patterns:
- FileSource
- For a row-wise format (splittable within files, checkpoint offset within a split)
- For a bulk format like Parquet / Orc.
- Bounded and unbounded split enumerator
- KafkaSource
- Unbounded without dynamic partition discovery
- Unbounded with dynamic partition discovery
- Bounded
- Kinesis
- Unbounded
- Unbounded
- FileSource
- Implement test harnesses for the high-level readers patterns
- Test their functionality of the readers implemented in (1)
- Implement a new
SourceReaderTaskand implement the single-threaded mailbox logic - Implement
SourceEnumeratorTask Implement the changes to network channels and scheduler, or to RPC service and checkpointing, to handle split assignment and checkpoints and re-adding splits.
Compatibility, Deprecation, and Migration Plan
In the DataStream API, we mark the existing source interface as deprecated but keep it for a few releases.
The new source interface is supported by different stream operators, so the two source interfaces can easily co-exist for a while.
We do not touch the DataSet API, which will be eventually subsumed by the DataStream API anyways.
Test Plan
Unit test and integration test for each implementations.
Appendix - Where to run the enumerator
The communication of splits between the Enumerator and the SourceReader has specific requirements:
- Lazy / pull-based assignment: Only when a reader requests the next split should the enumerator send a split. That results in better load-balancing
- Payload on the "pull" message, to communicate information like "location" from the SourceReader to SplitEnumerator, thus supporting features like locality-aware split assignment.
- Exactly-once fault tolerant with checkpointing: A split is sent to the reader once. A split is either still part of the enumerator (and its checkpoint) or part of the reader or already complete.
- Exactly-once between checkpoints (and without checkpointing): Between checkpoints (and in the absence of checkpoints), the splits that were assigned to readers must be re-added to the enumerator upon failure / recovery.
- Communication channel must not connect tasks into a single failover region
Given these requirements, there would be three options to implement this communication. And
Option 1: Enumerator on the TaskManager
The SplitEnumerator runs as a task with parallelism one. Downstream of the enumerator are the SourceReader tasks, which run in parallel. Communication goes through the regular data streams.
The readers request splits by sending "backwards events", similar to "request partition" or the "superstep synchronization" in the batch iterations. These are not exposed in operators, but tasks have access to them.
The task reacts to the backwards events: Only upon an event will it send a split. That gives us lazy/pull-based assignment. Payloads on the request backwards event messages (for example for locality awareness) is possible.
Checkpoints and splits are naturally aligned, because splits go through the data channels. The enumerator is effectively the only entry task from the source, and the only one that receives the "trigger checkpoint" RPC call.
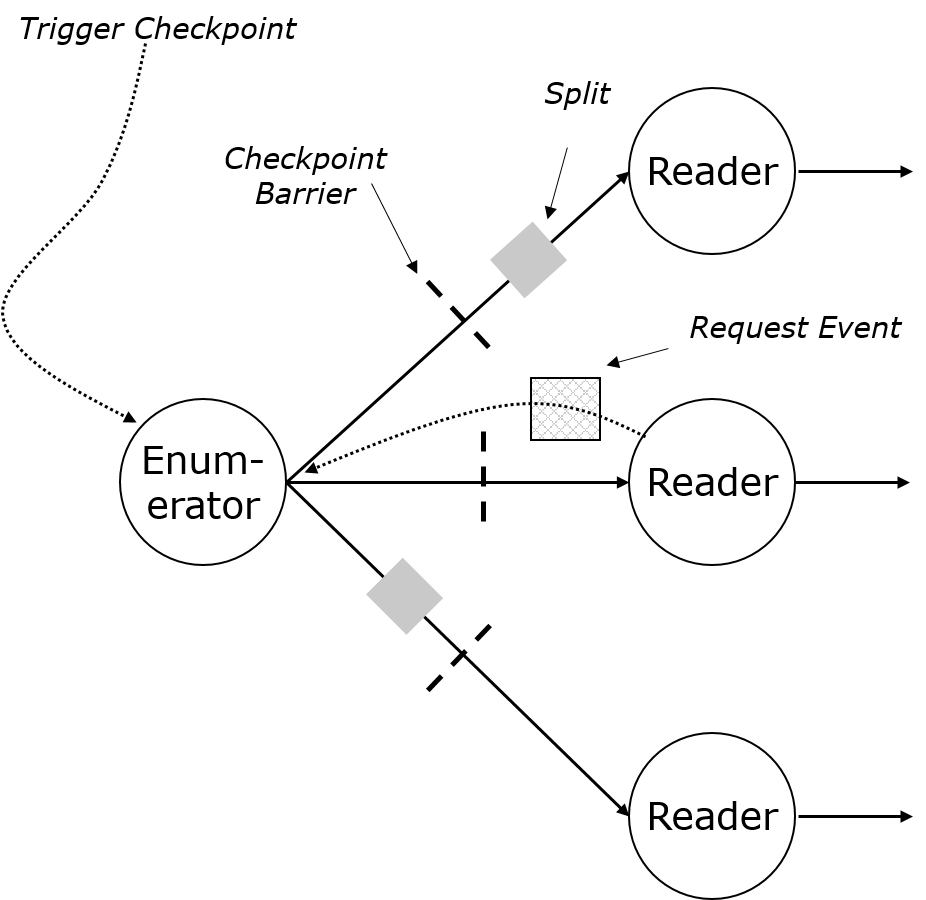
The network connection between enumerator and split reader is treated by the scheduler as a boundary of a failover region.
To decouple the enumerator and reader restart, we need one of the following mechanisms:
- Pipelined persistent channels: The contents of a channel is persistent between checkpoints. A receiving task requests the data "after checkpoint X". The data is pruned when checkpoint X+1 is completed.
When a reader fails, the recovered reader task can reconnect to the stream after the checkpoint and will get the previously assigned splits. Batch is a special case, if there are no checkpoints, then the channel holds all data since the beginning.- Pro: The "pipelined persistent channel" has also applications beyond the enumerator to reader connection.
- Con: Splits always go to the same reader and cannot be distributed across multiple readers upon recovery. Especially for batch programs, this may create bad stragglers during recovery.
- Reconnects and task notifications on failures:The enumerator task needs to remember the splits assigned to each result partition until the next checkpoint completes. The enumerator task would have to be notified of the failure of a downstream task and add the splits back to the enumerator. Recovered reader tasks would simply reconnect and get a new stream.
- Pro: Re-distribution of splits across all readers upon failure/recovery (no stragglers).
- Con: Breaks abstraction that separates task and network stack.
Option 2: Enumerator on the JobManager
Similar to the current batch (DataSet) input spit assigner, the SplitEnumerator code runs in the JobManager, as part of an ExecutionJobVertex. To support periodic split discovery, the enumerator has to be periodically called from an additional thread.
The readers request splits via an RPC message and the enumerator responds via RPC. RPC messages carry payload for information like location.
Extra care needs to me taken to align the split assignment messages with checkpoint barriers. If we start to support metadata-based watermarks (to handle event time consistently when dealing with collections of bounded splits), we need to support that as well through RPC and align it with the input split assignment.
The enumerator creates its own piece of checkpoint state when a checkpoint is triggered.
Critical parts here are the added complexity on the master (ExecutionGraph) and the checkpoints. Aligning them properly with RPC messages is possible when going through the now single threaded execution graph dispatcher thread, but to support asynchronous checkpoint writing requires more complexity.
Option 3: Introduce an independent component named SourceCoordinator, Enumerator runs on the SourceCoordinator
The SourceCoordinator is an independent component, not a part of ExecutionGraph. The SourceCoordinator could run on JobMaster or run as an independent process. There is no restrict by design. Communication with SourceCoordinator (Enumerator) is through RPC. Split assignment through RPC supports pull-based. SourceReader need to register to SourceCoordinator (address is in TaskDeploymentDescriptor or be updated by JobMaster through RPC) and then sends split request with payload information.
Each job has at most one SourceCoordinator which is started by JobMaster. There might be several Enumerators in one job since there might be several different sources, all Enumerators run on this SourceCoordinator.
Split assignment need to satisfy the checkpointing mode semantics. Enumerator has its own states (split assignment), they are a part of global checkpoint. When a new checkpoint is triggered, CheckpointCoordinator sends barriers to SourceCoordinator first. SourceCoordinator snapshots states of all Enumerators. Then SourceCoordinator sends barriers to SourceReader through RPC. The split and barrier through RPC is FIFO, so Flink could align the split assignment with checkpoint naturally.
If user specifies RestartAllStrategy as the failover strategy, Flink restarts all tasks and SourceCoordinator when a task fails. All tasks and Enumerators are restarted and restored from last successful checkpoint.
If user specifies RestartPipelinedRegionStrategy as failover strategy, it’s a little complicated. There is no failover region problem in this model, since there is no execution edge between Enumerator and SourceReader (SourceCoordinator is not a port of ExecutionGraph). We need to explain it separately.
When a
SourceReadertask fails,JobMasterdoes not restart theSourceCoordinatoror theEnumeratorson it.JobMastercancels other tasks in the same failover region with failed task as usual. ThenJobMasternotifiesEnumeratorthe failure or cancelation ofSourceReadertasks (there might be multipleSourceReadertasks in same failover region) and which checkpoint version will be restored from. The notification happens before restarting new tasks. WhenEnumeratoris aware of the task failures, it restores the states related failed tasks from the specific checkpoint version. That meansSourceCoordinatorneed to support partial restoring.Enumeratoralso keeps a two-level map ofSourceReader, checkpoint version and split assignment in memory. This map helps to find the splits should be reassigned or added back toEnumerator. There would be different strategies to handle these failed splits. In some event-time based jobs, reassignment of failed splits to other tasks may break the watermark semantics. After restoring the split assignment state, reconstructing the map in memory and handling the failed splits,Enumeratorreturns an acknowledgement back toJobMaster, thenJobMasterrestarts the tasks of failed region. There might be an optimization thatEnumeratorreturns an acknowledgement immediately without waiting for restoring. Thus the scheduling of failed region tasks and restoringEnumeratorcan be processing at the same time. Another important thing is that whenEnumeratoris restoring, the other runningSourceReadersshould work normally, including pulling next split.When
EnumeratororSourceCoordinatorfails, if there is a write-ahead log available (mentioned below),JobMasterwould restart theEnumeratororSourceCoordinatorbut not restartSourceReadertasks. After restarting,Enumeratorrestores states, replays the write-ahead log, then starts to working. At the meantime,SourceReaderwaits for reconnecting, there is no more splits assigned temporarily until reregistering successfully. The reregistration is necessary. There should be alignment after replaying write-ahead log betweenEnumeratorandSourceReaderbecauseEnumeratorcan not make sure last split assignments to eachSourceReaderare successful or not. The reconnection information is updated byJobMasterif needed (process is crashed). If there is no write-ahead log available, the failover would fallback to global failover, all tasks andEnumeratorswould be restarted and restored from last successful checkpoint.
CheckpointCoordinator should notify Enumerator that checkpoint has been completed. So Enumerator could prune the map kept in memory and the write-ahead log.
Open Questions
In both cases, the enumerator is a point of failure that requires a restart of the entire dataflow.
To circumvent that, we probably need an additional mechanism, like a write-ahead log for split assignment.
Comparison between Options
| Criterion | Enumerate on Task | Enumerate on JobManager | Enumerate on SourceCoordinator |
|---|---|---|---|
Encapsulation of Enumerator | Encapsulation in separate Task | Additional complexity in ExecutionGraph | New component SourceCoordinator |
| Network Stack Changes | Significant changes. Some are more clear, like reconnecting. Some seem to break abstractions, like notifying tasks of downstream failures. | No Changes necessary | No Changes necessary |
| Scheduler / Failover Region | Minor changes | No changes necessary | Minor changes |
| Checkpoint alignment | No changes necessary (splits are data messages, naturally align with barriers) | Careful coordination between split assignment and checkpoint triggering. Might be simple if both actions are run in the single-threaded ExecutionGraph thread. | No changes necessary (splits are through RPC, naturally align with barriers) |
| Watermarks | No changes necessary (splits are data messages, watermarks naturally flow) | Watermarks would go through ExecutionGraph | Watermarks would go through RPC |
| Checkpoint State | No additional mechanism (only regular task state) | Need to add support for asynchronous non-metadata state on the JobManager / ExecutionGraph | Need to add support for asynchronous state on the SourceCoordinator |
| Supporting graceful Enumerator recovery (avoid full restarts) | Network reconnects (like above), plus write-ahead of split | Tracking split assignment between checkpoints, plus | Tracking split assignment between checkpoints, plus write-ahead of split assignment between checkpoints |
Personal opinion from Stephan: If we find an elegant way to abstract the network stack changes, I would lean towards running the Enumerator in a Task, not on the JobManager.
Appendix - Previous Versions
Public Interfaces
We propose a new Source interface along with two companion interfaces SplitEnumerator and SplitReader:
public interface Source<T, SplitT, EnumeratorCheckpointT> extends Serializable {
TypeSerializer<SplitT> getSplitSerializer();
TypeSerializer<T> getElementSerializer();
TypeSerializer<EnumeratorCheckpointT> getEnumeratorCheckpointSerializer();
EnumeratorCheckpointT createInitialEnumeratorCheckpoint();
SplitEnumerator<SplitT, EnumeratorCheckpointT> createSplitEnumerator(EnumeratorCheckpointT checkpoint);
SplitReader<T, SplitT> createSplitReader(SplitT split);
}
public interface SplitEnumerator<SplitT, CheckpointT> {
Iterable<SplitT> discoverNewSplits();
CheckpointT checkpoint();
}
public interface SplitReader<T, SplitT> {
/**
* Initializes the reader and advances to the first record. Returns true
* if a record was read. If no record was read, records might still be
* available for reading in the future.
*/
boolean start() throws IOException;
/**
* Advances to the next record. Returns true if a record was read. If no
* record was read, records might still be available for reading in the future.
*
* <p>This method must return as fast as possible and not block if no records
* are available.
*/
boolean advance() throws IOException;
/**
* Returns the current record.
*/
T getCurrent() throws NoSuchElementException;
long getCurrentTimestamp() throws NoSuchElementException;
long getWatermark();
/**
* Returns a checkpoint that represents the current reader state. The current
* record is not the responsibility of the reader, it is assumed that the
* component that uses the reader is responsible for that.
*/
SplitT checkpoint();
/**
* Returns true if reading of this split is done, i.e. there will never be
* any available records in the future.
*/
boolean isDone() throws IOException;
/**
* Shuts down the reader.
*/
void close() throws IOException;
}
The Source interface itself is really only a factory for creating split enumerators and split readers. A split enumerator is responsible for detecting new partitions/shards/splits while a split reader is responsible for reading from one split. This separates the concerns and allows putting the enumeration in a parallelism-one operation or outside the execution graph. And also gives Flink more possibilities to decide how processing of splits should be scheduled.
This also potentially allows mixing and matching different enumeration strategies with split readers. For example, the current Kafka connector has different strategies for partition discovery that are intermingled with the rest of the code. With the new interfaces in place, we would only need one split reader implementation and there could be several split enumerators for the different partition discovery strategies.
A naive implementation prototype that implements this in user space atop the existing Flink operations is given here: https://github.com/aljoscha/flink/commits/refactor-source-interface. This also comes with a complete Kafka source implementation that already supports checkpointing.
Proposed Changes
As an MVP, we propose to add the new interfaces and a runtime implementation using the existing SourceFunction for running the enumerator along with a special operator implementation for running the split reader. As a next step, we can add a dedicated StreamTask implementation for both the enumerator and reader to take advantage of the additional optimization potential. For example, more efficient handling of the checkpoint lock.
The next steps would be to implement event-time alignment.
Compatibility, Deprecation, and Migration Plan
- The new interface and new source implementations will be provided side-by-side to the existing sources, thus not breaking existing programs.
- We can think about allowing migrating existing jobs/savepoints smoothly to the new interface but it is a secondary concern.
2 Comments
Lukasz Slonina
>> For "bounded input", it uses a
SplitEnumeratorthat enumerates once all files under the given path.What about continously enumerating files in under given path, but treating content of a file as a "bounded input"?
Biao Liu
Hi Lukasz Slonina, I think what you described is a typical "continuous input" scenario.
The
Enumeratorcontinuously enumerates files under given path, encapsulates the file path into a split and then sends the split toSourceReader. After getting the split, theSourceReaderreads content of this file.