Basic definitions
Node - separate instance of Ignite, server or client.
Node order - internal property of each node (in case of TcpDiscoverySpi it is just a uniformly increasing number).
Coordinator - specific (with minimal order) server node responsible for coordinating different processes in the cluster (like verifying discovery messages, managing Partition Map Exchange and others).
Topology - high-level structure all nodes are organized into.
Introduction
Discovery mechanism is the most basic piece of functionality aimed to form a cluster from separate Ignite nodes. Its main goal is to build some view of the cluster (number of nodes, nodes' orders and so on) shared by all nodes and maintain consistency of that view.
Discovery is hidden behind the interface DiscoverySpi, its default implementation is TcpDiscoverySpi. Another implementation is ZookeeperDiscoverySpi but it is out of scope of this article.
DiscoverySpi implementation defines a structure called topology all nodes - both servers and clients - are arranged into. Cluster with TcpDiscoverySpi uses ring-shaped topology.
Ring-shaped topology
Tcp Discovery aligns all server nodes in the cluster into a ring-shaped structure when each node maintains connection to its next and its previous maintains connection to the node. Client nodes stay outside of the ring and are always connected to a specific server (there is no previous node for client, only a server it is connected to).
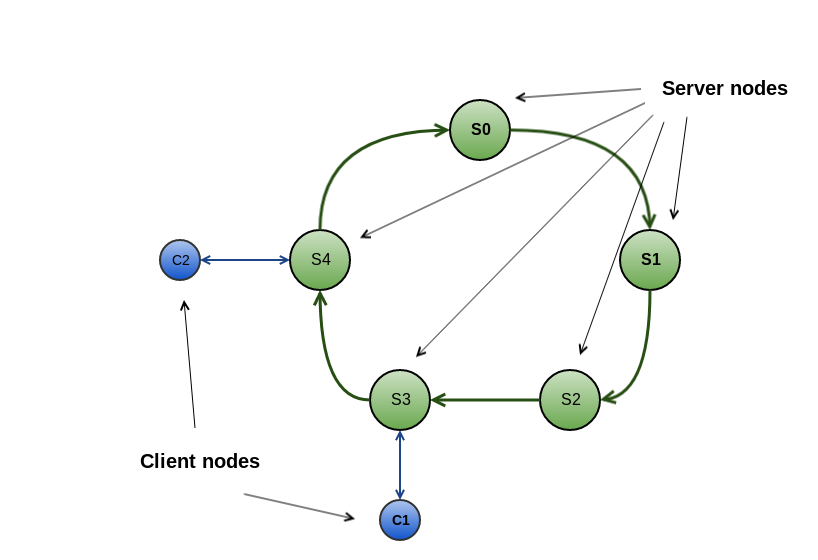
Most of implementation logic lives in ServerImpl and ClientImpl classes for servers and clients respectively.
Later on "node" will be referring to "server node" for convenience.
When new node starts it tries to find existing cluster probing all addresses provided by TcpDiscoveryIpFinder. If all addresses are unavailable node considers itself as a very first node, forms the cluster from itself and becomes coordinator of this cluster.
If node manages to connect to one of addresses from IpFinder, it starts join process.
Node join process
Overview
Node join consists of several phases involving different messages - join request, NodeAdded message, NodeAddFinished message. During the process new node is validated, configuration information exchange happens if validation was successful and topology information is updated on all nodes.
When node joins successfully it is placed between previous last node and coordinator in the ring.
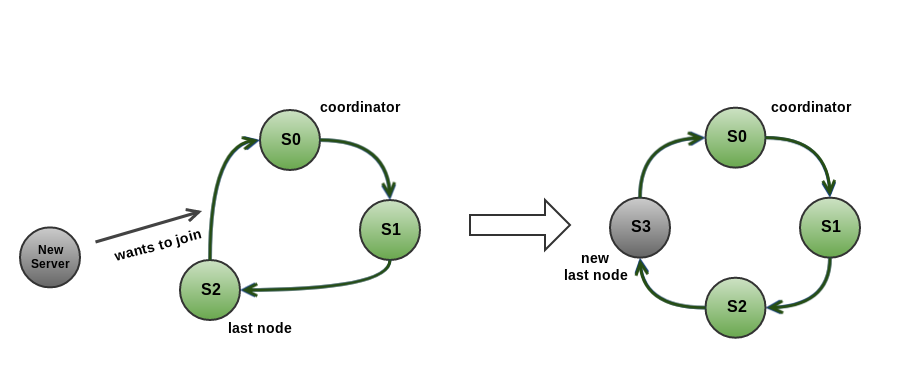
Join request message
Starting point for join process is joinTopology method presented in both ServerImpl and ClientImpl classes.
At first node collects discovery data from all its components (i.g. it collects cache configurations from GridCacheProcessor). Central point here is TcpDiscoverySpi#collectExchangeData which calls GridComponent#collectJoiningNodeData on each component.
This disco data is packed into join request and sent to the cluster.
When JoinReq reaches coordinator it validates the message and generates NodeAdded message if validation has passed (ServerImpl.RingMessageWorker#processJoinRequestMessage). After that lifecycle of join request is finished; only NodeAdded message is used further. Coordinator creates this message, adds info about joining node (including joining node discovery data from JoinReq) to it and sends across the ring.
NodeAdded message
Processing logic lives in ServerImpl.RingMessageWorker#processNodeAddedMessage.
On receiving NodeAdded each node in cluster (including coordinator node) applies joining node discovery data to components, collects its local discovery data and adds it to the message.
Then node sends NodeAdded to the next node by calling ServerImpl.RingMessageWorker#sendMessageAcrossRing.
Lifecycle of NodeAdded is finished when it completes pass across ring and again reaches coordinator. Coordinator creates NodeAddFinished message and sends it to ring.
NodeAdded message is delivered to the joining node as well, it receives the message at the very end when all other nodes have already processed it.
NodeAddFinished message
NodeAddFinished message as its name suggests finishes the process of node join. On receiving this message each node both server and client fires NODE_JOINED event to notify discovery manager about new joined node.
NodeAddFinished and additional join requests
Joining node will send additional join request if it doesn't receive NodeAddFinished on time. This time is defined by TcpDiscoverySpi#networkTimeout and has a default value of 5 seconds (TcpDiscoverySpi#DFLT_NETWORK_TIMEOUT).
Detecting and removing failed nodes from topology
Detecting failed nodes is a responsibility of each server node in cluster. However detecting failed servers and clients works slightly different and will be considered separately.
Server nodes failures - general case
As servers are organized into ring each node can easily detect failure of its next neighbor node when sending of next discovery message fails.
However process of removing failed node from the ring (there is a special structure called "ring" on each server node which reflects topology view of current node, see ServerImpl#ring field) is not that simple and has to be managed by coordinator. It contains two steps.
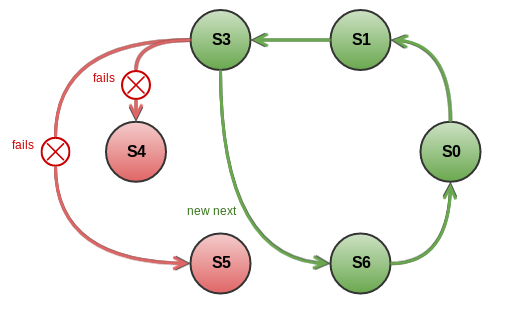
First step
On the first step server detected that it next has failed adds it to the special local map called failedNodes. Using this map it will filter failed nodes from all servers presented in the ring until the second step is completed for each failed node.
Along with adding next node to failedNodes map server picks up from the ring next server right after the failed and tries to establish connection with it. In case of success found server becomes new next, otherwise the process repeats from the beginning: adding node to failedNodes map, picking up next to failed and so on.
TcpDiscoveryAbstractMessage and its responsibilities
Any disco message can inform about failed nodes in topology (see TcpDiscoveryAbstractMessage#failedNodes collection and logic around) and all nodes receiving any disco message start processing it from updating their local failedNodes maps with info from that disco message (see ServerImpl$RingMessageWorker#processMessage where method processMessageFailedNodes is called almost at the beginning).
When ring is restored and next alive server node found, current node adds info about all nodes from failedNodes map to any discovery message it is about to send and sends it (see how this field is handled in ServerImpl$RingMessageWorker#sendMessageAcrossRing method).
Also server detected failed node is responsible for creating TcpDiscoveryNodeFailedMessage - special discovery message that starts second step of removing failed node. One message is created for a failed node. So if three nodes has failed, three TcpDiscoveryNodeFailedMessage messages are created.
Second step
Second step starts on coordinator.
When coordinator receives TcpDiscoveryNodeFailedMessage it verifies it and sends it across the ring. All servers (including coordinator) update their local topology versions, finally remove failed node[s] from the ring structure and failedNodes map (see ServerImpl$RingMessageWorker#processNodeFailedMessage).
Client nodes failures
Section patiently waits for someone to contribute content
Resilience in presence of short network glitches
Algorithm of restoring ring without failing nodes (that one involving CrossRingMessageSendState and other tricky things and special timeouts) should be covered here in great details (including special timeouts)
Corner cases with filtering of unverified NodeFailed messages
Section patiently waits for someone to contribute content
Custom discovery messages and events
Section patiently waits for someone to contribute content
Message delivery guarantees
Section patiently waits for someone to contribute content
Overview
Content Tools
Apps